- PagerDuty /
- Der Blog /
- Alarmierung /
- Einen Rechenzentrumsausfall überleben
Der Blog
Einen Rechenzentrumsausfall überleben
von Amanda Folson
20. Januar 2015 | 3 Minuten Lesezeit
PagerDuty basiert auf einer einfachen Idee: die richtigen Leute zu wecken, wenn etwas kaputt geht. Wenn ein Ereignis ausgelöst wird, benachrichtigt PagerDuty auf magische Weise die richtige Person oder das richtige Team, dass etwas nicht stimmt.

Allerdings ist es nicht so einfach, sicherzustellen, dass die Nachricht unseren Weg zu Ihnen findet. Da wir Sie benachrichtigen, wenn Ihre Systeme ausgefallen sind, sind wir stark daran gehindert, aktiv zu sein. Wenn Sie uns nicht vertrauen können, wem dann?
Wir verlassen uns in unserer Alarmierungspipeline auf einige verteilte Technologien, da sie uns die Redundanz bieten, die wir brauchen, um sicherzustellen, dass die Alarme die Benutzer erreichen. Wir haben viel Zeit darauf verwendet, unsere Infrastruktur so fehlertolerant wie möglich zu gestalten, um dauerhafte und konsistente Lese-/Schreibvorgänge in unserer kritischen Alarmierungspipeline zu gewährleisten.
Diese Pipeline beginnt mit einem Ereignisendpunkt – entweder HTTP oder E-Mail. Von dort durchläuft jedes Ereignis aus dem Überwachungstool eines Kunden eine Pipeline aus separaten Diensten (wie z. B. Vorfallmanagement- und Benachrichtigungsmanagementdienste) und landet schließlich beim Nachrichtendienst, der die Leute tatsächlich erreicht. Viele dieser Dienste basieren auf Scala und werden im Backend von Cassandra zur Datenspeicherung unterstützt. Wir nutzen auch andere Technologien wie Zookeeper zur Koordination. Diese Pipeline muss immer aktiv und intakt sein, damit wir sicherstellen können, dass die Benachrichtigungen die Leute erreichen.
Cassandra bei PagerDuty
Wir haben Cassandra seit etwa zweieinhalb Jahren in der Produktion. Im Gegensatz zu einigen Unternehmen, die Cassandra zur Unterstützung ihrer „Big Data“-Bemühungen verwenden, ist unser Datensatz relativ klein – in der Größenordnung von 10 GB zu jedem beliebigen Zeitpunkt. Da wir es verwenden, um Ereignisse durch unsere Pipeline zu leiten, können die Daten dazu aus der Pipeline gelöscht werden, sobald das Ereignis das Ende erreicht. Wir versuchen, unseren Datensatz so schlank wie möglich zu halten.

Cluster-Konfiguration
Wir erstellen normalerweise Cluster aus 5 Cassandra-Knoten mit einem Replikationsfaktor von 5. Diese Knoten sind auf drei Rechenzentren verteilt: zwei Knoten in einem, zwei Knoten in einem anderen und ein Knoten in einer weiteren Einrichtung. Wir nutzen die Quorum-Konsistenzstufe von Cassandra, um die Haltbarkeit zu erreichen, die wir in der Pipeline benötigen. Dies bedeutet, dass jeder Schreibvorgang an die Mehrheit des Clusters gesendet werden muss, d. h. an mindestens 3 der 5 Knoten.
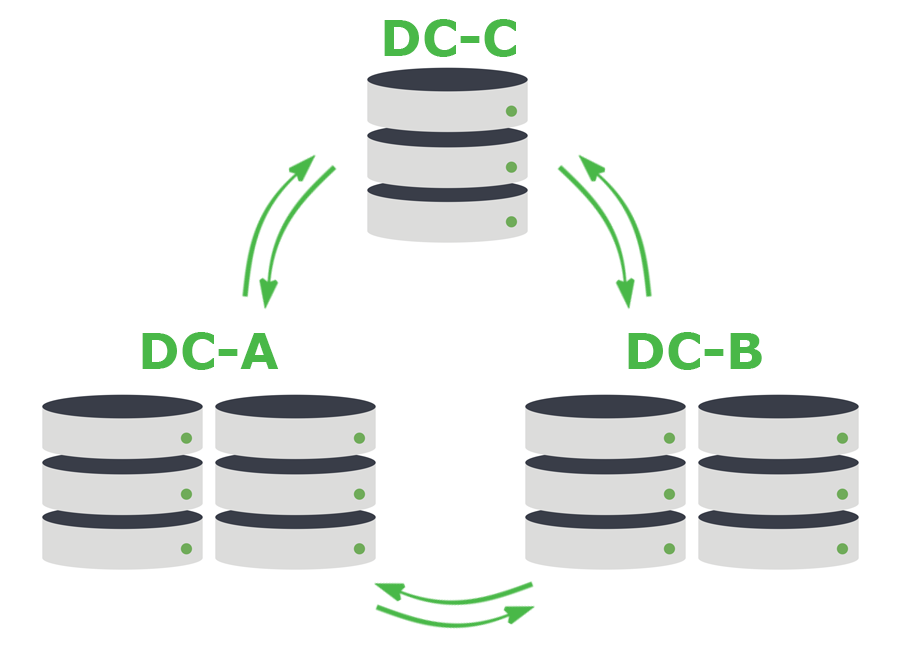
Dieses Muster ist nicht ohne Mängel. Jeder Vorgang erfolgt über das WAN und ist mit Latenzzeiten zwischen den Rechenzentren verbunden. In gewisser Weise widerspricht dies den üblichen Empfehlungen für Datenbankcluster. Da diese Latenzzeiten jedoch nicht von Menschen verursacht werden, sind wir bereit, diesen Kompromiss angesichts der Vorteile in Kauf zu nehmen: Ereignisse gehen nicht verloren, Nachrichten werden nicht wiederholt und wir erhalten Beständigkeit und Verfügbarkeit für den Fall, dass ein ganzes Rechenzentrum ausfällt. Bei diesem 3-von-5-Muster wird alles in mindestens zwei Rechenzentren geschrieben.
Woher wissen wir, dass das funktioniert?
Wir führen absichtlich Fehler in unsere Infrastruktur ein, um sicherzustellen, dass im Falle eines Ausfalls alles weiterhin reibungslos läuft. Dazu gehört das gründliche Testen von Cassandra-Knoten in degradiertem und nicht funktionsfähigem Zustand. Weitere Informationen hierzu finden Sie in unserem Beitrag vom Misserfolg am Freitag .
Bei PagerDuty lösen wir gerne interessante technische Probleme. Wenn Sie daran interessiert sind, unseren Cluster robuster zu machen, stellen wir derzeit ein für Positionen in San Francisco Und Toronto .

