
- PagerDuty /
- Blog /
- Automation /
- Tickets Make Operations Unnecessarily Miserable
Blog
Tickets Make Operations Unnecessarily Miserable
by Damon Edwards
December 16, 2022
| 9 min read
IT Operations has always been difficult. There is always too much work to do—and not enough time to do it. The frequent interruptions and high levels of toil certainly don’t help. Moreover, there is relentless pressure from executives that question why everything takes too long, breaks too often, and costs too much.
In search of improvement, we have repeatedly bet on new tools to improve our work. We’ve cycled through new platforms (from virtualization, to cloud, to containers, to Kubernetes) and new automation (e.g., Ansible, Terraform, Pulumi). While each has provided benefits, would an average engineer say that the stress and overload on operations has fundamentally changed?
Enterprises have also spent the past two decades liberally applying management frameworks like ITIL and COBIT. Again, would an average engineer say things have gotten better or worse?
In the midst of all of this, there is conventional wisdom that rarely gets questioned—the extensive use of tickets to manage operations work.
Tickets have become the go-to work management tool in operations organizations. Need something done? Open a ticket. Someone needs something from you? A ticket will appear in your queue.
Ticket-driven ways of working have become so ubiquitous that few think twice about adding more ticket queues across an organization.
However, what if we were wrong about tickets? What if ticket queues were a significant source of operational strife hiding in plain sight? Let’s examine how ticket queues are often causing more harm than good.
What is wrong with tickets?
It’s the queues
Tickets on their own are relatively innocuous as they are just records. The issue is where you put those tickets. Tickets get put into ticket queues, and that is where the problems start.
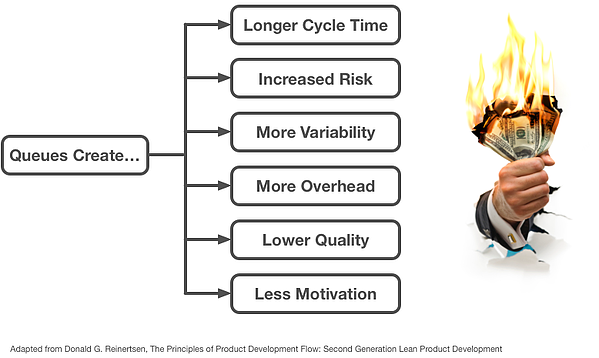
Queues add delay, increase risks, add variability, add overhead, lower quality, and decrease motivation.
These aren’t my opinions, the cost of queues comes from extensive research in other fields as diverse as physical manufacturing and product development. Queuing Theory is its respected area of academic study.
In the rest of this post, I’ll use “tickets” and “queues” somewhat interchangeably. Just know that it is the queue part that causes the problems.
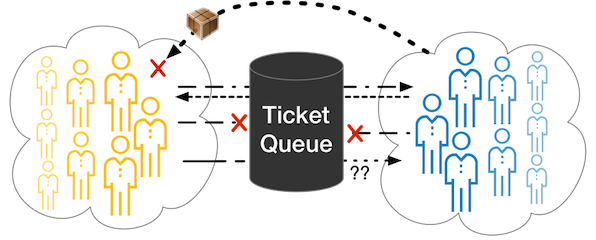
Tickets increase communication problems
Whenever parties are forced to communicate via ticket queues, there are going to be disconnects and miscommunication. Think about all of the problems you’ve probably had with tickets: Requests being misunderstood. The person reading a request lacks the context or is working in a different context. The requester makes the wrong request or doesn’t understand the ramifications of what they are requesting. As a request sits in the queue, the request parameters have (unknown to either party) changed or are no longer valid.
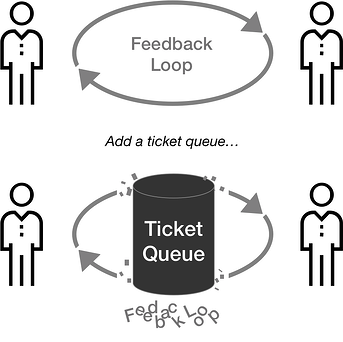
Tickets delay feedback and learning
Almost every modern management philosophy (from Lean to DevOps and the Lean Startup) hinges on the concept of the organization learning quicker. All strive for increasingly tighter feedback loops so that analysis and decisions happen faster.
However, as Scott Prugh likes to remind us all, “Queues don’t learn.” Queues work against feedback loops by both injecting delays and stripping each request of its context. It is tough to become a learning organization when there is rampant use of ticket-driven request queues.
Tickets encourage bottlenecks
The nature of how teams work through ticket queues encourages bottlenecks. First, ticket queues are often used where there are capacity mismatches. For example, ticket queues are commonly used to buffer requests made of specialist teams (e.g., network, database, security) who are largely outnumbered by people who need them to do something. These requesting teams “stuff” the queue with requests, which causes the queue length and response times to grow. Because queues delay feedback, the requestors are often unaware of (or don’t care about) the capacity mismatch and continue to stuff the queue. This behavior increases both the queue length and response time, worsening the bottleneck.
Additionally, as queue lengths grow, the teams responsible for working the queue will instinctively look inward to protect their capacity. This natural reaction leads to optimizations for the team behind the queue—often at the expense of the broader organization. For example, if a firewall team only makes non-emergency changes on Mondays and Thursdays, it creates a delay for the rest of the organization even if it helps the firewall team optimize its workload.
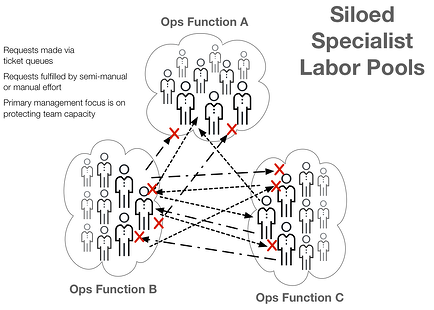
Tickets reinforce siloed ways of working
Ticket queues act as buffers that allow teams to continue working in a siloed, disconnected manner. The more disconnected teams become, the more they behave like siloed pools of specialist labor.
Requests are made of these specialists via ticket queues, and requests are fulfilled as one-offs through semi-manual or manual efforts. Variability is high. Priorities and context are difficult to gauge.
As with the reaction to bottlenecks, the primary management focus is on protecting team capacity (not the needs of the broader organization). The more that silos’ effects are reinforced, the more disconnects, mistakes, and delays there will be. Ticket queues are the enablers of this downward spiral.
Tickets create snowflakes
The default FIFO (First In, First Out) nature of ticket queues encourages one-offs. When a ticket comes up to the top of the queue, the people working the ticket queue will spring into action, attempt to garner as much context as possible in the limited time they have, do what they think is correct from their perspective, and then move on to the next ticket.
This way of working—jumping from one request to another, each with seemingly disconnected context—is a leading cause of snowflakes. “Snowflakes” is a term that describes something that may be technically correct (even perfect) but a one-off that is not reproducible. A manually updated server is the classic example of a snowflake. You may be able to get it into a working state, but in all likelihood, it is going to be slightly different from other servers in your fleet (and often in undetectable ways).
The cost of snowflakes might seem minimal at first, but as environments grow, the costs quickly compound and create an expensive and seemingly intractable condition. As Keith Chambers has famously pointed out, “How many enterprises have had ‘snow days’ where some small, unexpected variation results in an incident that kills a team’s capacity for hours or days?”

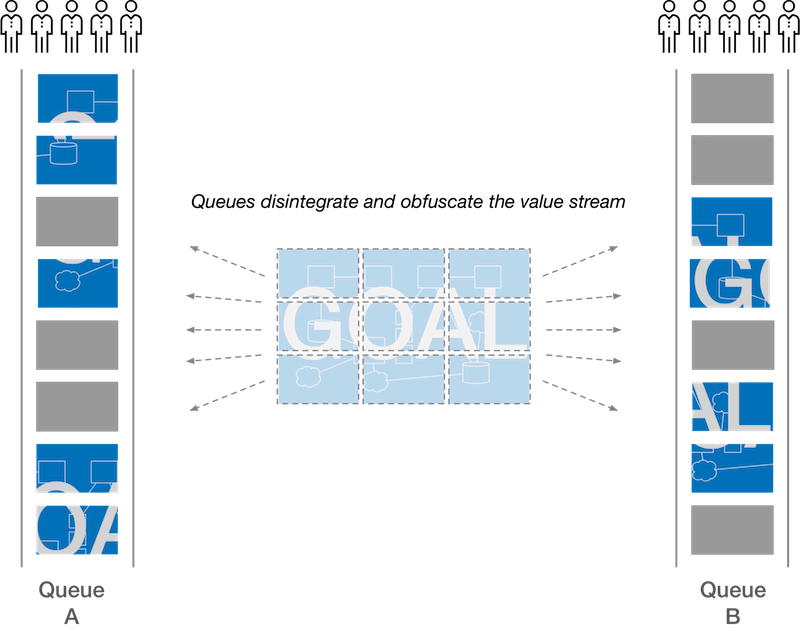
Tickets obscure the value stream
So much of the work of the Lean, Agile, and DevOps movements have been about breaking down barriers to build a systemic view of the work that needs to be done to deliver value (this end-to-end systemic view is often referred to as the “value stream”). Because context matters in all knowledge work, understanding where each piece of work fits into the broader system is critical.
After all the work that has been done to provide transparency and build-up context, breaking it down into a series of individual tickets obscures the value stream and scatters the context. In fact, breaking work down into smaller and smaller units is often seen as a ticket system best practice.
Tickets add management overhead
Ticket queues don’t just appear and take care of themselves. Someone has to set up the queue and define the rules (rules that also often add the overhead of other people needing to learn how to work within or around those rules). Someone has to maintain the ticket system itself. Priorities, conflicts, and politics also need to be continuously managed (often through an expensive project management overlay). All of this work has a cost and requires time and effort that could be spent on other value-adding work.
What are tickets good for?
Don’t get me wrong; tickets aren’t all bad. Tickets are just overused and/or used for the wrong reasons.
In my opinion, ticket systems are useful for raising true exceptions (e.g., logging bugs or enhancement requests). Also, there is some merit to using ticket systems to document human-to-human communication when approvals are unavoidable.
Ticket queues are also useful when each request is atomic and isolated (e.g., traditional customer helpdesk or selling tickets at a box office). However, most of these requests are prime candidates for self-service automation.
When it comes to the complex knowledge work required to deliver and operate enterprise software-based services, the evidence seems clear that ticket queues are costly at best and destructive at worst.
How do we get rid of as many ticket queues as possible?
As more organizations become aware of the toxic side effects of ticket-driven request queues, I see the same basic pattern emerging to remove as much work from queues as possible:
- Redesign the work to avoid handoffs wherever possible
Forward-thinking organizations have been focusing on creating “service ownership” or “product-aligned teams” that can handle as much of the lifecycle as possible (without needing to hand off work to other teams). Eliminating handoffs, naturally, cuts down on the need for ticket queues.
- Apply self-service automation to eliminate remaining ticket queues
Wherever ticket queues can’t be eliminated, replacing the queues with self-service is an excellent alternative. Self-service automation enables both the definition and execution of operations activity to be delegated across traditional organizational boundaries. By replacing ticket queues with pull-based self-service interfaces, wait time is eliminated, feedback loops are shortened, breaks in context are avoided, and costly toil is eliminated. The few ticket queues that remain are the ones for true expectations and one-offs.

It is time to take action
It is time, as an industry, to question the conventional wisdom of ticket queues. Tickets have their place, but have been overused to everyone’s detriment. Here at PagerDuty, we’re working with our users to find and enable better ways of working that make it easier to get things done. We hope you can join us on this mission.
Contact us to learn more about PagerDuty Process Automation.
