
- PagerDuty /
- Blog /
- Incident Management & Response /
- Building Titles for Intelligent Alert Grouping
Blog
Building Titles for Intelligent Alert Grouping
by Quintessence Anx
January 27, 2022
| 7 min read
Co-authored by Chris Bonnell, PagerDuty Data Scientist VI
We’re continuing on with our third piece about how to utilize and improve your Intelligent Alert Grouping (IAG)! In case you missed it, in our first post, we introduced you to Intelligent Alert Grouping feature (here). In the second post, we explained how IAG uses merging to group alerts (here). We alluded to today’s post at the end of last: today we’ll be discussing how to use alert titles to improve IAG matches.
Where you will see the alert title – a refresher
When an alert is triggered in our platform, the notification can go out via a few paths: email, text, or push notification from the app itself. Regardless of the path, the minimum information that is displayed is: the alert number, service, and alert title. This will show in a few notable places. Depending on how you receive your alerts, some or all of these may look familiar. Note that while the urgency level (e.g., high) is used to determine how to reach you, it is not visibly displayed (but is in the incident details).
Phone push and text notifications
For example, let’s look at the lock screen an iPhone (in addition to the text notification and phone call for the same incident):
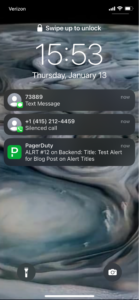
In this case, I have the alert pushing to all channels for the purpose of the blog post. Here you can see that the alert title, number, and service are what are displayed. A text message looks similar:

Email notifications
These look a little different. The email subject doesn’t give much detail, but the full alert details are included in the message body:
Why are we reviewing where alert titles are displayed?
If you’re like me, when you were writing alert titles and descriptions for real situations and real services, you were likely optimizing for human brains. You can see artifacts of this even above. The alert title reads more like a type of blog post title and heavy-handedly includes the identifier “Title” in the title itself to accentuate where it appears. This is for humans—when you’re skimming these images I want your attention in specific areas.
What if I were designing for non-humans? For example, what if I were designing on machine learning? I’d probably take whatever I knew or learned about machine learning and start to skew the message to favor that.
What I want you to take away from all this is: Don’t lose the fact that you still need to keep humans in mind when you start to include your awareness of machine learning to improve your experience with Intelligent Alert Grouping.
Utilizing your alert title to your advantage
When you build the alert title for people, remember to:
- Be concise. As you can see, both the push and text notifications have a short character limit.
- There are different limits by OS and web browser. For example, Android has a push title character limit of 65 with an additional limit of 240 characters for a description, whereas iOS has a combined character limit of 178 characters for title and description.
- Be clear. Do not be so concise that the title is confusing or doesn’t convey anything.
- Do not favor the title field and neglect the other fields.
- The PagerDuty mobile apps, as well as the web interface, have the full incident information available, including other incidents, their services, and their descriptions. Do not top load information into the title field just because it appears first.
For more information about these, please take a look at our Alerting Principals page on our Incident Response Ops Guide.
For machine learning, keep the following in mind:
- Use distinctiveness and frequency to your advantage.
- Data models cannot read (in the same sense that humans do).
- Data models cannot infer intent.
The reason for this is understanding how machines perform what’s called “natural language processing”. Natural language processing is what allows a spelling or grammar checker to differentiate between “it’s” and “its” and notify the author accordingly, or allows autocorrect to know what word and conjugation and what form (conjugation, declination) to suggest. For natural language processing as applies to alert titles: titles are anonymized (more on this in a moment), broken down into sentences and then words, in processes called “sentence tokenization” and “word tokenization” respectively, then the words are lemmatized, and the end result is used to determine frequency and look for correlations with other alerts.
Starting with anonymization: the goal of this is to replace otherwise too-unique information with the pattern of that information, for example replacing a specific IP address with xx.xx.xx.xx. This text is not entirely removed as to avoid totally stripping potentially relevant context, but prevent the unique information from causing titles to not be correlated that should be. Lemmatization is the process of simplifying conjugated or declinated words into a base form, called a lemma. Again by example: {“dogs”, “dog’s”, “dogs’”, “dog”} would all be lemmatized to “dog” and similarly {“is”, “are”, “be”, “were”} to “be”. This means that sentences like “The dog’s bones.” and “The dogs’ bones.” are both lemmatized to {“the”, “dog”, “bone”, “.”} at this phase.
At this point, the Intelligent Alert Grouping model uses both n-grams (groups of N words) and our knowledge of incident language patterns to extract information out of the alert title and make meaningful correlations. Let’s take another look at the examples I included in my previous post:
- First pattern:
- memory usage high (> N %) on server $NAME in region $REGION
- Second pattern:
- memory usage on host is high (> N %)
I already anonymized a bit with N % and $NAME, but let’s go through the exercise of tokenizing what’s in those titles:
- Tokenized and lemmatized first pattern:
- {“memory”, “use”, “high”, “(“, “>”, “N”, “%”, “)”, “on”, “server”, “$NAME”, “in”, “region”, “$REGION”}
- Tokenized and lemmatized second pattern:
- {“memory”, “use”, “on”, “host”, “be”, “high”, “(“, “>”, “N”, “%”, “)”}
If we consider the impact of what the patterns mean, in the second alert the only term that varies is N, depending on the value put there. If the threshold is consistent rather than the current memory usage, then N might not vary at all or only have one or two values that will appear in the title. By contrast, the first alert title has more uniqueness in the name of the server and its region. So that’s three varying terms instead of one or none. Insofar as the language processor is concerned, alerts of the second pattern are therefore much more likely to be correlated than the first.
Where to go from here
It’s important to consider both humans and machine learning when building your alert titles, with a slight skew for optimizing on machine learning, as people can make use of the full alert and incident details to get additional context and information, whereas Intelligent Alert Grouping is using the title field only. To read more about the basics of natural language processing, take a look at the Introduction to Natural Language Processing for Text blog post on the Towards Data Science blog. For best practices on what information is relevant to include in alerts and incidents in general, please take a look at our Incident Response Ops Guide.

