
- PagerDuty /
- Blog /
- Automation /
- PagerDuty at re:Invent 2022 Launches Automated Diagnostics for AWS that Enables Organizations to Resolve Incidents Faster So They Can Innovate More
Blog
PagerDuty at re:Invent 2022 Launches Automated Diagnostics for AWS that Enables Organizations to Resolve Incidents Faster So They Can Innovate More
by Inga Weizman
November 28, 2022
| 7 min read
It’s that time of the year! PagerDuty is coming back to sin city for AWS re: Invent 2022! The global conference brings organizations of all sizes and is set to explore themes of modernization, automation, and resiliency in the cloud. With current economic conditions, enterprises are looking to scale operations and optimize costs while delivering always-on, digital experiences to their customers. Automaton plays a key role in helping support operational and cost efficiency. This year, we are excited to bring along a new solution to the re:Invent floor: Automated Diagnostics for AWS that helps engineering teams have more time for innovation and less interruptions. We are also proud to be a Platinum Sponsor at re:Invent, deepening our long-term relationship with AWS and delivering automated CloudOps to joint our customers.
Cloud is eating the world
According to Gartner, “by 2023, 40% of all enterprise workloads will be deployed in cloud infrastructure and platform services, which is an increase from 20% in 2020.” This quote further drives home the reality that cloud adoption continues to be a top priority for enterprises looking to further digitize their services and backend infrastructure. AWS gives you unprecedented scale, agility, and speed of innovation, but teams face increasing complexity and ever-growing dependencies across systems, processes, and their organizations. This complex situation threatens to put the customer and employee experience — not to mention revenue — at risk.
As organizations migrate to the cloud and deploy cloud-native architectures, the increased complexity can cause more (expensive) incidents. Many organizations run in complex cloud architectures containing several interconnected services — many existing ephemerally — that are deployed across different availability zones and accounts. When incidents happen, it can take a long time to resolve them without understanding the root cause or who has the proper access privileges and subject matter expertise. This means lots of escalations and developers being pulled away from high-value work.
Incidents can get expensive — really expensive. A major retailer can lose upwards of $200K per minute in revenue every minute the site is down. Incidents also incur productivity costs, as engineers are working on fixing the problem instead of building new features and focusing on innovation. A poor customer experience because of or during an incident can further cost an organization dollars in the form of brand reputation. And when you add up all of those factors, the cost of an incident is much higher than you may have accounted for.
Resiliency matters
Resiliency is essential to ensuring that your customers enjoy their digital experiences with little to no interruption. The uncomfortable reality? Things will inevitably break and services will go down. It happens to all of us. What really matters is how fast you can recover and get your services back in the green, in addition to ensuring similar incidents like that don’t occur again in the future. Ensuring you have full visibility across your hybrid infrastructure and making sure you can detect and diagnose issues quickly is essential to continuity of your business and all your services.
Resilience doesn’t just happen, it’s a shared responsibility. Customers have to set up their infrastructure, operations, and people in a way that helps them endure and quickly respond to incidents. Defining clear ownership and accountability by having teams build and own their services is an essential part ensuring that you can have focused, real-time incident response.
PagerDuty empowers teams with end-to-end incident response and advanced automation capabilities that quickly and accurately orchestrate the right response, every time. Process Automation helps teams to quickly diagnose and resolve incidents by significantly reducing the number of escalations and MTTR so engineering teams can focus on continuous improvement and innovation.
Too many humans, too little time
Modern cloud architectures for AWS customers are composites of some 250 AWS services and 25,000 SaaS workflows available in the market, combined with in-house developed software and other legacy systems.
When incidents occur in these complex cloud environments, access to full cloud stack expertise is often needed to determine probable root cause, rule out other possibilities among dependencies, and check for false positives. This may require a first responder to escalate to several expert engineers to gather these diagnostics to determine who the ultimate resolver should be.
First line responders often lack know-how and access to gather diagnostic content in AWS environments. Many first line responders are generalists, and lack technical knowledge of what investigations are needed to diagnose specific issues in services. First responders also lack superuser access to be able to execute technical investigations due to security policies.
This means first responders typically must escalate to multiple experts to get the data they need to triage an incident, consuming more staff time to resolve the incident and interrupting more team members. For serious outages this needlessly extends the length of time it takes to resolve an incident, takes engineers away from high-value work, and increases the overall cost of an outage. Automation can play a key role in not only resolving incidents faster, but in arming first responders with the diagnostic data they need to resolve incidents on their own, thus safeguarding valuable engineering time.
Automated Diagnostics for AWS
With Automated Diagnostics for AWS, incident responders can quickly triage incidents themselves, reducing the need to escalate for help, speeding up resolution for customers, and increasing operational efficiency. Automated Diagnostics for AWS in PagerDuty provides frequently used, pre-built diagnostics job templates for commonly used services, including Amazon EC2, AWS Lambda, Amazon ECS, Amazon RDS, and more. Customers can easily configure these template jobs to work in their specific environments and extend the diagnostics steps in a workflow. Automated Diagnostics for AWS also allows customers to quickly design their own diagnostic jobs for AWS, and corrective automation for mitigation and remediation that can be invoked by responders within PagerDuty Incident Response, or triggered by PagerDuty Event Intelligence.
Customer Service teams and stakeholders are coordinated with real-time status information to deliver a better customer support experience. Automation helps internal teams operate more efficiently by shaving 25 minutes off MTTR, reducing the number of people required to resolve an incident and decreasing the number of escalations by 40%, saving time and money while improving the customer experience.
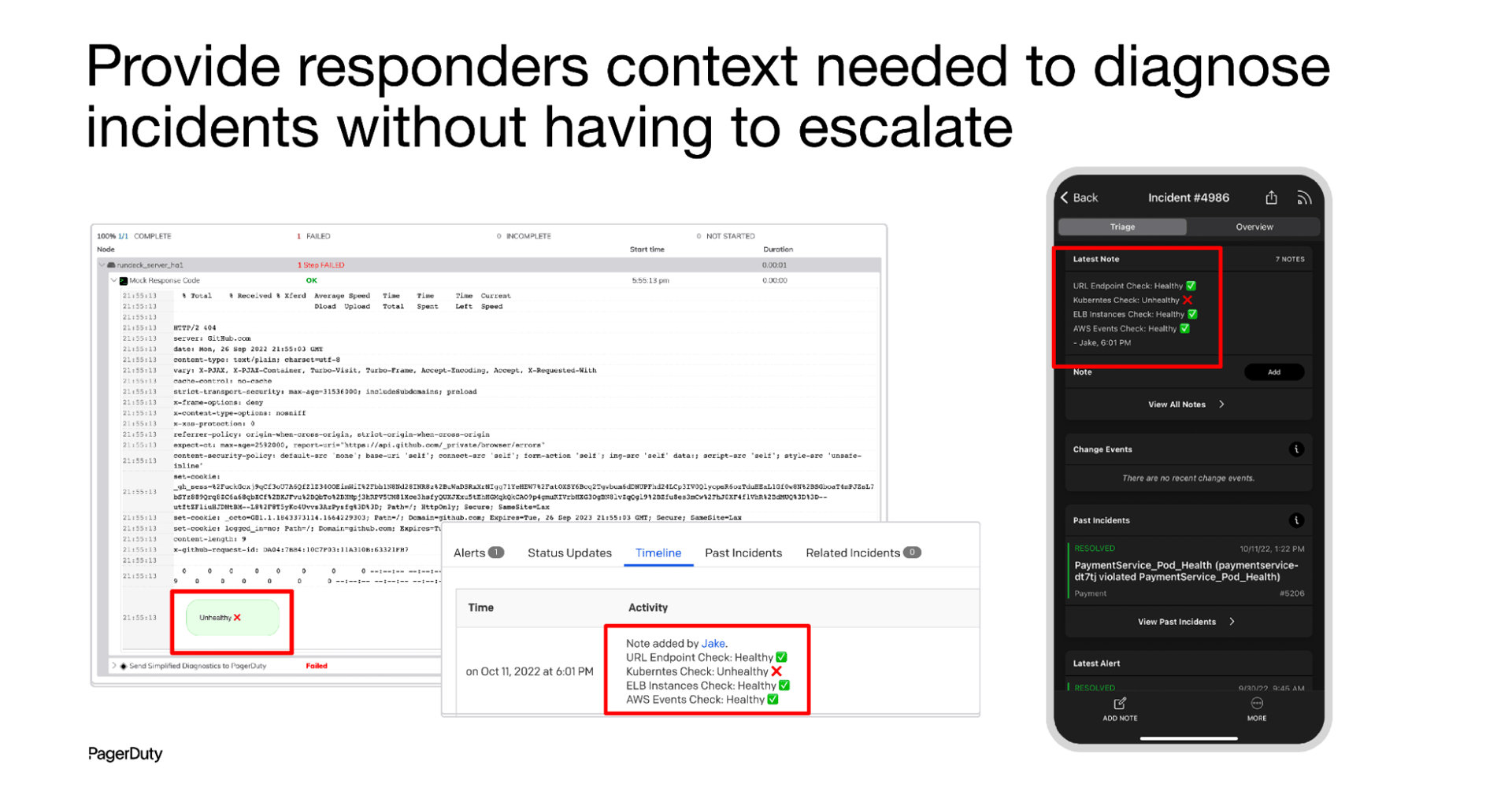
Automated Diagnostics for AWS:
- Empowers first responders with the power to triage, mitigate, and resolve incidents, improving MTTR across the board.
- Reduces escalations to engineers by using pre-built job templates and plugin integrations to critical AWS tools and services
- Enables teams to continuously improve the efficiency of incident response within their AWS environments giving time back to engineers
Learn more about Automated Diagnostics for AWS or get started here.
Meet PagerDuty at AWS re:Invent
There will be plenty of opportunities to meet our team at re:Invent, pick up some swag, say hello to Pagey and attend lightning talks at our booth.
Stop by our booth #3819 to get a demo of our product offerings including, Process Automation, Incident Response, Event Intelligence and Customer Service to see how the PagerDuty Operations Cloud can help you uplevel your digital operations. We will also have plenty of lightning talks from our partners – learn more here.
If you would like to avoid the crowds and schedule a meeting or demo in one of our meeting rooms, just submit your request here. Our team can tailor the conversation to your specific needs, and share more about PagerDuty and AWS.
Monday November 28, 2:30 pm at Venetian Theatre, Level 2, Session #PRT217
Join us for our panel of industry leaders from SalesForce, Netflix, Sailpoint and Benefitfocus as they discuss how they have transformed their organizations with PagerDuty and AWS.

Wednesday, November 30, 6:00-8:00 pm
Join our leaders and your industry peers at Matteo‘s Ristorante Italiano for evening cocktails and conversation. Learn more about how PagerDuty helps some of the most innovative companies in the world deliver a superior customer experience.

To learn more about PagerDuty and AWS click here or watch this webinar.
