
- PagerDuty /
- Blog /
- Best Practices & Insights /
- Improving Beyond MTTR with PagerDuty Analytics
Blog
Improving Beyond MTTR with PagerDuty Analytics
by Mandi Walls
January 2, 2024
| 8 min read
Improving Beyond MTTR
We’ve posted a bit about the ambiguity around MTTR before, but we want to get deeper into the confusion and maybe false sense of security our reliance on MTTR causes, from both a qualitative and quantitative standpoint.
Our friends at the VOID have also tackled MTTR from the standpoint that we often can’t conclusively even pinpoint the time part; we are tracking time from when an alert is received or maybe from the time a customer reports an issue, but those methods are only as good as our metrics and customer reporting channels allow.
If our goals are to increase our reliability and lower our overall MTTR, we might find that MTTR isn’t giving us all of the information we need to improve. If you’re into Monte Carlo simulations (and who isn’t!), this paper from Google digs into some of the weaknesses of MTTR with math. Lots of math.
Being Mean about the Mean
You probably learned about summary statistics like the mean, mode, and median of a set of values in school. The mode is really the weird one there, it’s the value that appears most often. Median is the middle value of the set when arranged in numerical order, and mean is the average of all the values.
We use mean fairly often in incident response. Your team may track your mean time to acknowledge in addition to your mean time to recover/repair/resolve. When we think about the mean of a set of numbers, our remembered examples from algebra class are things like “the average test scores on a history exam” or “the average temperature in our town for this month”. These are numbers that are already going to be within a well-defined range, with reasonable upper and lower bounds. They are super useful for sets with a normal distribution.
The crazy thing about your resolve time is that there is effectively no upper bound; depending on the boundaries your team sets for MTTR, incidents can go on basically forever, which makes MTTR look… weird.
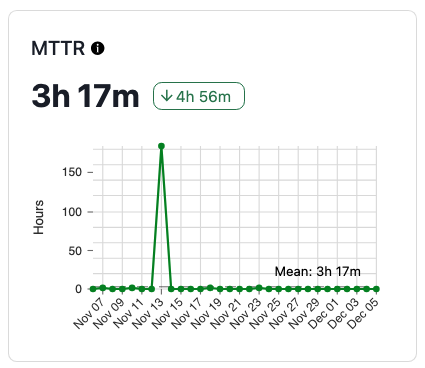
Summary statistics are helpful for abstracting characteristics of a set of values, but once those values start obliterating their boundaries you have to start making decisions about the usefulness of aspects like the mean, or potentially decide how to deal with anomalies. And in software incidents, anomalies can be totally legitimate; teams might be waiting on work to be approved and deployed, or a fix to be released by an upstream vendor.
For other data in the reliability realm, the industry has moved on, towards more robust and useful measures of data that might be in a skewed or multimodal distribution. Maybe you’re looking at some of your data based on percentiles instead of means. That tells you more about the shape of the values themselves and how likely a “bad” value is for the chosen datapoint.
For Quality, not a Quantity
MTTR can be a challenging metric to improve for many teams working in complex environments because it isn’t a flat one-dimensional feature. It’s often a blunt instrument, but for teams with no experience in incident management, it’s a good place to start. Once you have the mechanics of your incident response workflows under your belt, some of the shortcomings of MTTR start to show through.
Thinking about those test scores on the history exam I mentioned earlier. All the students in the class took the same exam; they probably had access to the same lectures and materials before the exam. If any of the students want to improve their score on the next test, they’ll study more. What should your team do to improve your MTTR? Can you study more?
Additionally, we hope you aren’t solving the same problem over and over during your incidents. We want folks to learn from incidents and use those learnings to improve their service reliability. Plus there’s lots of additional factors that alter the environment of your services: customer usage patterns, new code and features, other changes. It’s very hard to say “incident 150 this month is just like incident 120 last month and it took less time” because the circumstances of the environment are never the same.
Figuring out what’s going on in a complex system in order to remediate an incident can be a complicated process, involving multiple systems and teams. Comparing the recovery time for every incident a service has in a given time period won’t tell you a lot about how that service is behaving. Complex incidents are multi-dimensional, and what we know about them is important for how we improve and learn from them.
Much of the qualitative discussion around an incident should come out during the post-incident review, but if you’re looking for trend data to show improvements, there’s some ways to slice and dice your incidents to get a better look at the overall picture, and give your teams some guidance on what needs improvement.
Should You Bother Measuring MTTR?
We see many teams who start using PagerDuty without an incident management plan in place drastically improve their MTTR in a short period of time. A large part of getting incidents resolved is mobilizing teams, getting automation involved, and communicating. For folks who aren’t proficient at that yet, getting good tools set up is the dawning of a new day. Logging improvements to MTTR is a great start for these teams.
Once your team is effectively using an incident response workflow, focusing on MTTR alone is unlikely to continue to create improvement in your service reliability. Your MTTR could absolutely stay the same, increase, or even decrease if you doubled the number of incidents you have on a service but the dataset had the same range (the Google paper shows an example of those scenarios). Your users would definitely feel that your reliability had decreased, though, if you have more incidents. MTTR can’t expose that change in overall reliability. Using a mean squashes the details too much.
There are other pieces of information you can look at, many of which are included in PagerDuty’s Analytics offering, as part of the Insights reports. These will help you drill down into the other dimensions of your incidents, but will require you to be diligent about data hygiene.
A good data point to have teams focus on is making sure incidents are assigned a priority.
Priorities
In your PagerDuty account, you have the ability to define a set of priorities that align with your reliability goals. Your team can determine what the priority levels represent, such as percentage of customers impacted, or duration of an incident, or other heuristics that make sense for you.
Priority is not automatically assigned to an incident; some teams will use alert data to determine priority via Event Orchestration and other teams will manually update the priority during the course of the incident. Other teams might wait until the incident is resolved and update the priority retroactively to more accurately reflect the incident.
Having priorities assigned to each incident your team responds to gives you the ability to see how your team is faring on the most impactful incidents, and you can use Priority as a filter on the Insights screen, and the summary data will show you summary data and trends for the priorities that matter the most.
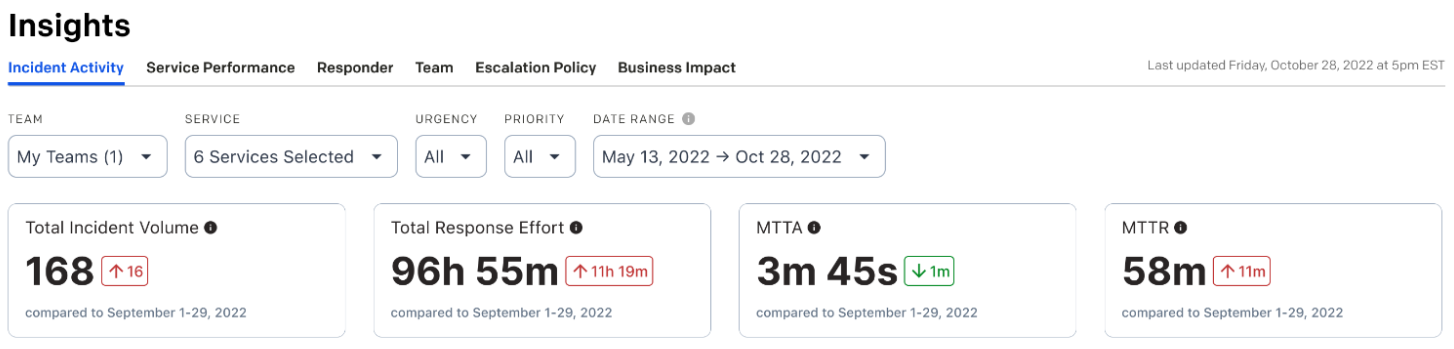
This helps you dig through some of the heterogeneity of your incidents, to focus on the ones your users will care about most. If your team has many low-priority incidents with short durations, your MTTR won’t tell you about the smaller number of high-priority incidents.
Watching the number of high-priority incidents on user-facing services, combined with a set of user-focused SLOs, can help your team set benchmarks and make better decisions. If a service has suffered too many SEV-1, customer-impacting incidents in the last 30 days, and the SLO is close to being breached, development teams can make an educated decision to freeze releases or prioritize reliability-related features to recover service reliability.
Summary
Keeping an eye on your MTTR can be a helpful way to benchmark your team’s improvements as you roll out a new incident response workflow. More experienced teams may get more benefits diving deeper into their incident data, and PagerDuty Analytics can help. For more information, and to see some of the latest features in Analytics, visit our YouTube channel where we’ve posted some of the latest features! See more on the Insights and the new Analytics Dashboard with our product team!

