
- PagerDuty /
- Blog /
- Best Practices & Insights /
- APAC Retrospective: Learnings from a Year of Tech Outages, Restore: Repair vs Root Cause
Blog
APAC Retrospective: Learnings from a Year of Tech Outages, Restore: Repair vs Root Cause
by David Ridge
January 22, 2024
| 7 min read
As our exploration of 2023 continues from the third-part of our blog series, Dismantling Knowledge Silos, one undeniable fact persists: Incidents are an unavoidable reality for organisations, irrespective of their industry or size.
Recent APAC trends show that regulatory bodies are cracking down harder on large corporations for poor service delivery, imposing harsh penalties as a result of the negative consequences. The stakes of an incident have escalated from mere revenue loss and eroded trust to include substantial fines and business operation limitations.
Faced with a range of disruptions from major technical glitches to cloud service failures and cybersecurity risks, today’s businesses must be strategically poised for incident response. In this fourth instalment, we continue to navigate the critical stages of the incident lifecycle, equipping organisations with insights to prepare for what is now inevitable: their next incident.

Part 4: Restore: Repair vs Root Cause
In the modern landscape of complex systems, the debate between prioritising service restoration over fixing the root cause will persist. Striking the right balance is crucial. Immediate service restoration safeguards the business from financial losses and maintains customer satisfaction. Standardised and automated restoration procedures are key to this. A clear definition of “Resolved” is critical for reliable metrics and effective incident management, but having the ability to filter and adjust the granularity of metrics such as MTTR is required to maintain its accuracy and usefulness.
When an IT outage strikes, the primary concern is the rapid restoration of services. In the past year, we have witnessed how downtime can lead to significant financial losses, damage to a brand’s reputation, and disruptions in customer service. In such critical situations, the focus shifts from dissecting the root cause to quickly bringing the affected systems back online. The philosophy here is straightforward and can be guided by some basic principles:
- Uptime is money: In our digital world, uptime equates strongly to revenue. The longer services remain disrupted, the greater the financial impact on the organisation. Service restoration ensures that the business can resume operations swiftly, mitigating potential financial losses.
- Customer expectations: Whether internal employees or external customers, end users demand uninterrupted access to services. Swift restoration not only maintains customer satisfaction but also prevents a negative impact on the organisation’s reputation.
- Operational continuity: Some issues may not have an immediate, clear root cause. Engaging in a lengthy process to identify and fix the underlying problem may not align with the need for operational continuity. Service restoration allows the organisation to function while a more thorough investigation takes place.
Temporary Solutions Until It’s Fixed
Identifying the root cause of an IT incident is a crucial step towards preventing future occurrences. However, the process of fixing the underlying problem can be time-consuming, especially if it involves a full development and testing cycle. In many cases, organisations operate with complex systems and dependencies, making it challenging to predict the exact impact of changes.
Consider a scenario where a critical bug is identified, and the operational team traces it back to a recent code deployment. While investigating the root cause, they discover that fixing the underlying problem involves changes in multiple modules and requires extensive testing. Or maybe it’s just 2am and not exactly the best time to start coding!
The correct action, especially in the face of a service outage, would be to opt for a swift rollback of the change that introduced the bug. Rolling back allows the organisation to revert to a known stable state quickly and aligns with the goal of minimising downtime and getting the services back online promptly. This approach also removes the stress of a ticking clock over the heads of the developers trying to fix the problem.
Another strategy in the context of service restoration is the implementation of temporary measures, such as adding more resources to keep critical services running. This approach recognizes that fixing the underlying problem might take time, and the organisation cannot afford extended downtime.
For example, if an unexpected surge in user activity is overwhelming the existing infrastructure, temporarily scaling up resources or adding more compute power can alleviate the immediate strain. While this might not address the root cause of the increased demand, it ensures that services remain operational, buying time for a more thorough investigation and long-term solution implementation.
A Blended Approach
For both these scenarios, automation is key.
In the previous post, we outlined how organisations can speed up the triage stage of the incident lifecycle and identify the root cause. A similar approach can be taken to service restoration. Having the operational tools available in a single click to perform standard recovery procedures, such as rollback a deployment or increase resources, can relieve pressure and give back valuable time.
The arguments for prioritising service restoration over fixing the root cause sometimes blur the lines between incident management and problem management. Incident management focuses on restoring services quickly, while problem management aims to identify and eliminate the root causes of recurring incidents. Striking a balance between these two is essential for maintaining a robust and resilient IT environment.
In certain situations, a blended approach can be adopted. This involves implementing temporary measures to restore service promptly while concurrently conducting a parallel investigation into the root cause. The key is to find a pragmatic balance that minimises downtime without endless patching or neglecting the long-term stability of the IT infrastructure.
Automation of standard recovery procedures that can be invoked by the operational teams in seconds is required for operationally mature organisations to give them the buffer they need to fix underlying problems, without the unnecessary downtime.
MTTR – Repaired or Resolved?
In the realm of incident management, the term “Resolved” carries significant weight. Mature organisations recognize the importance of having a clear definition for “Resolved” in order to confidently use metrics like Mean Time to Resolve (MTTR) and meet Service Level Agreements (SLAs).
However, incident resolution can sometimes be ambiguous. While the immediate disruption might be resolved, the underlying issue may persist or user verification may be required. This creates a dilemma as to whether the incident can truly be considered resolved.
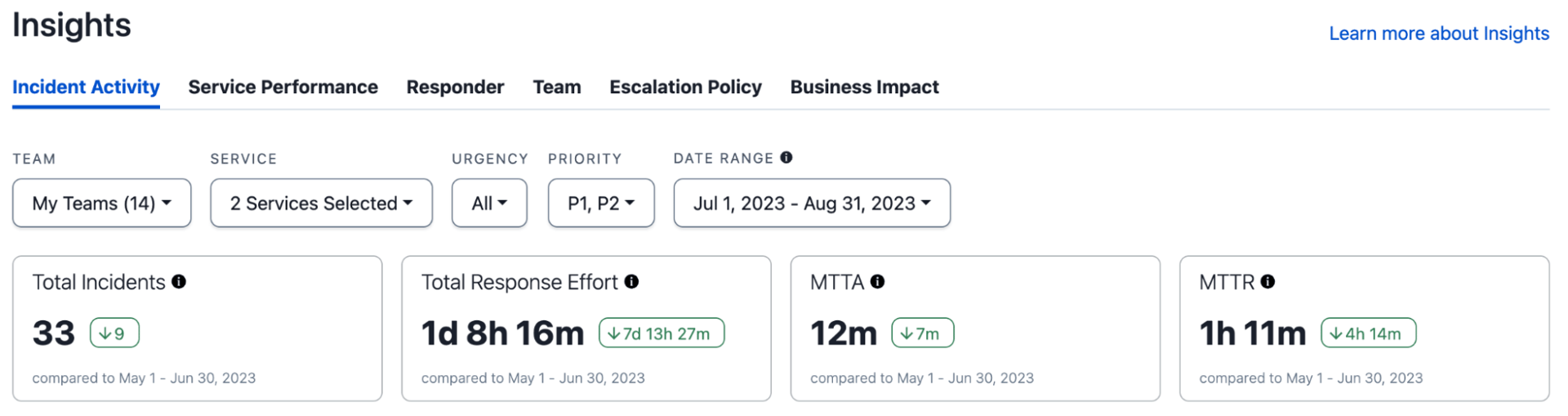
Metrics like MTTR and SLAs are critical for evaluating an organisation’s performance in incident response both internally and externally. However, without a clear definition of resolution, these metrics may provide a false sense of security or a skewed picture of reality. Organisations understand the need for precision in defining the moment an incident is truly resolved, as well as reporting that can accurately track and measure this at various levels of granularity and priority.
This granularity is key when we use a metric like “mean”. There is no upper bound on the duration of an incident, so results can skew for sample sizes that do not have a normal distribution. For an excellent deep dive on MTTR, this recently published blog outlines the benefits and challenges perfectly.
Ultimately, the pragmatic approach involves understanding the context of each outage and choosing the most efficient path. The primary goal of operational teams should always be to minimise downtime and ensure business continuity. While addressing the root cause is critical for preventing future incidents, organisations must weigh the urgency of service restoration against the potential delays associated with extensive troubleshooting and fixing.
Swiftly restoring services, even through temporary measures or rollbacks, can be a strategic decision that aligns with the immediate needs of the business. This approach acknowledges the real-world challenges of complex environments and the unpredictable nature of incidents. Striking the right balance between incident management and problem management combined with the ability to accurately measure this, ensures that organisations can navigate the intricate balance between rapid recovery and long-term stability.
A Look Ahead
In our fifth and final post, we will wrap up our journey through the incident lifecycle to understand how we can use principles of continuous improvement and learning to iteratively improve incident management with each incident.
Want to Learn More?
We will also be hosting a three-part webinar series that focuses on the P&L and how it has helped clients to focus on growth and innovation. Click the links below to learn more and register:
- 7th February 2024: Part 1: Better Incident Management: Avoiding Critical Service Outages in 2024
- 21st February 2024: Part 2: From Crisis to Control: How You Can Modernise Incident Management with the help of Automation & AI
- 26th to 29th February 2024: Part 3: PagerDuty 101

