
- PagerDuty /
- Blog /
- Best Practices & Insights /
- APAC Retrospective: Learnings from a Year of Tech Outages: Reactive to Proactive
Blog
APAC Retrospective: Learnings from a Year of Tech Outages: Reactive to Proactive
by David Ridge
January 29, 2024
| 6 min read
As we reach the end of our blog series on the occurrences in 2023 from the fourth installment of our blog series, Restore: Repair vs. Root Cause, the unavoidable truth is that incidents are a universal challenge for organisations, regardless of their scale or field.
In the APAC region, there’s a noticeable increase in regulatory bodies imposing strict penalties on major companies for service failures. Organisations are now dealing with consequences that go beyond revenue and trust loss, such as severe financial penalties and operational restrictions.
When it comes to major technological disruptions, cloud service outages, and cybersecurity threats, businesses must be proactive and prepared. In this final (and fifth) instalment of our blog series, we now conclude our investigation of the incident lifecycle by focusing on critical strategies for organisations to fortify themselves against the unavoidable: the next incident.

Part 5: Learn–Reactive to Proactive
Overview
As evidenced over the course of the past year, organisations are realising that incidents serve as pivotal moments, not just disruptions. They act as opportunities for strategic learning and operational growth. In this instalment, we underscore the transformative power of incident learning, focusing on actionable steps to enhance organisational maturity. We’ll dive into the nuances of blameless incident reviews, the iterative learning process, and the tangible benefits that come with increased maturity and we shed light on how organisations can transition from reactive to proactive by emphasising actionable improvements in their incident response processes.
Taking a strategic and blameless approach to incident reviews transforms them from routine post-mortems to proactive tools for improvement. These reviews become a structured and trusted means of unravelling the complexities of an incident, offering actionable insights into areas of success and potential improvements. As mentioned in the previous post, organisations should strongly advocate moving beyond just numerical data analysis. While analytics play a crucial role in creating a baseline incident narrative, the emphasis should be on interpreting the data in context, understanding the nuances and insights that the responders experienced during the incident, and the observations that can actively shape a more sophisticated incident response strategy. This strategy should also align with the wider organisational goals, and not just those of the development and operations team. An example might be where uptime and brand reputation hold a higher value to the business than fixing technical debt.
A Catalyst for Continuous Improvement
Following on from a major incident, the fallout should not just be about knee-jerk changes. Major incidents give an organisation a chance to make a fundamental shift from old and reactive incident management to a culture of continuous improvement. In times of instability and uncertainty, an organisation’s agility becomes the key driver which allows them to pivot effectively in response to evolving challenges. Insights gained from understanding how incidents are identified and where the bottlenecks are in the process gives teams the raw materials to drive change.
In fact, continuous and proactive problem-solving from incidents emerges as a competitive edge. It empowers organisations to take decisive action, addressing potential issues before they escalate and ensuring a strategic advantage in a landscape where downtime is not just an inconvenience but a significant business liability.
Actionable Insights
Reduced downtime isn’t just about saving time—it’s about understanding the true cost of inaction and actively implementing measures to minimise it. As we have observed all too often, downtime is no longer an operational hiccup but a strategic risk with tangible implications for revenue, customer trust, and market competitiveness. Mature organisations require the capabilities to look beyond the low level metrics of incident counts and durations. They must understand the various stages within the lifecycle of the incident. Visibility into each stage pain points of these stages is critical to derive actionable insights that can be used to continuously improve both the systems and the people involved.
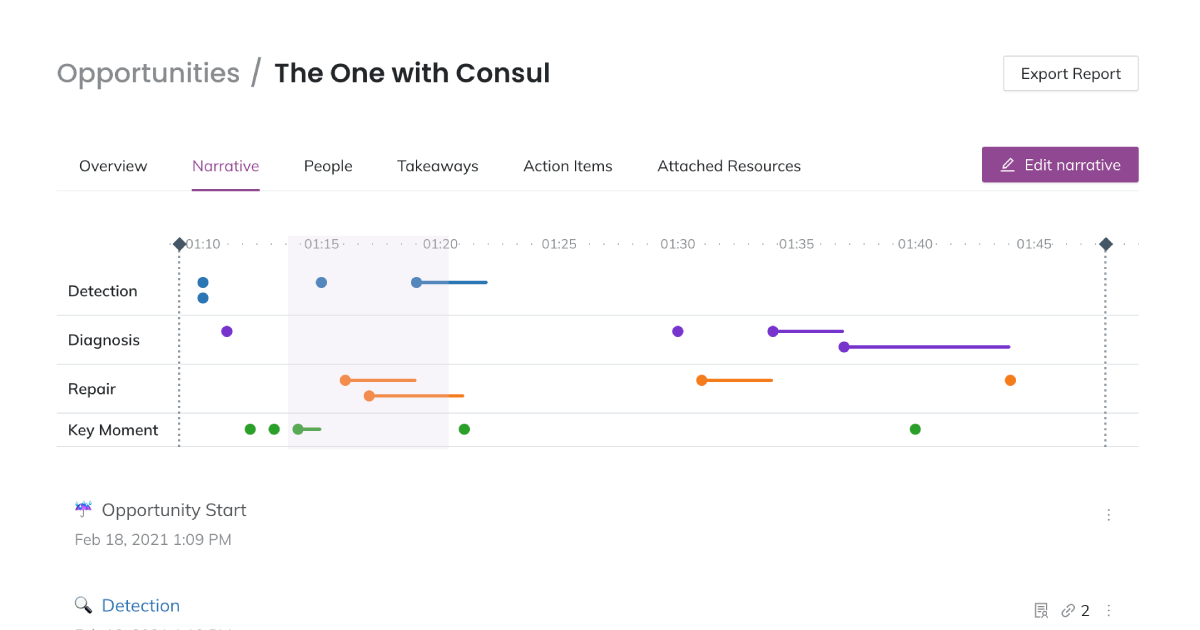
The numerous business benefits of increased incident response maturity are driven by these actionable insights. Organisations actively safeguard their reputation through mature incident response, retaining and attracting customers who value reliability and transparency. However, incident response maturity is not is not merely on reducing the obvious negative consequences of an outage such as lost revenue but on freeing up resources for delivering strategic initiatives and growing the business. A simple example might be analysing and categorising the different types of incidents by technology or business function and then understanding the optimal response team required, organisations can focus and mobilise an agile and targeted response, reducing the blast radius (and cost) of each incident.
“You can’t directly change culture. But you can change behaviour, and behaviour becomes culture” – Lloyd Taylor, VP Infrastructure, Ngmoco
Fostering a Culture of Resilience
The above quote has been referenced in a number of different talks and presentations, including The Five Love Languages of DevOps by Matty Stratton, and it very neatly captures the nuance of team culture. By promoting behaviours that encourage operational maturity based on blameless learning and actionable insights, a positive work culture of resilience emerges as a strategic foundation of the organisation.
It’s not just about acknowledging the team’s value, it’s about actively empowering them to contribute to a resilient and strategically aligned organisation. Organisations that actively distil actionable insights from their incidents gain a distinct advantage when making decisions. Especially in times of high pressure and visibility where they must be seen to act. As outages become more and more subject to regulatory compliance, and resilience becomes a matter of strategic assurance, a clear and focussed roadmap to getting better is never more valuable.
In conclusion, incident learning is not a passive endeavour; it is an active and ongoing vocation that organisations must embrace for operational maturity. By viewing incidents as learning opportunities, organisations can continuously improve through actionable insights. Learning from incidents is not just about understanding; it is about actively leveraging those insights to emerge stronger, more resilient, and strategically positioned for the future. The foundations laid by modern tooling, iterative learning, and a mature incident response approach, become a roadmap for actionable improvements that will drive long-term success in the ever-evolving tech ecosystem.
Want to Learn More?
We will also be hosting a three-part webinar series that focuses on the P&L and how it has helped clients to focus on growth and innovation. Click the links below to learn more and register:
- 7th February 2024: Part 1: Better Incident Management: Avoiding Critical Service Outages in 2024
- 21st February 2024: Part 2: From Crisis to Control: How You Can Modernise Incident Management with the help of Automation & AI
- 26th to 29th February 2024: Part 3: PagerDuty 101

