PagerDuty and DataOps: Enabling Organizations to Improve Decision Making with Better Data
This blog was co-authored by Jorge Villamariona from Product Marketing and May Tong from Technology Ecosystem
Introduction
Many organizations have been digitally transforming their operations and the majority of them are moving to the cloud. With this transformation, data teams have to analyze ever larger and more complex data sets to allow downstream teams to make faster and more accurate decisions on a daily basis. Consequently, most organizations need to work with: customer data, product data, usage data, advertising data, and financial data. Some of the datasets are structured, some are semi-structured, and some unstructured. In short, there are endless amounts of data of various types arriving from multiple sources at increasing rates.
With these larger volume, velocity, and variety (commonly known as the 3Vs) of big data, the traditional approaches to managing the data lifecycle started to fall short. Concurrently, and towards the end of the first decade of the 2000s, software development teams started adopting agile methodologies for the software development lifecycle. These methodologies became known as DevOps (portmanteau of Development and Operations). The following diagram illustrates the DevOps process at a high level.

DevOps Process
Meanwhile, data professionals took a page from their next door software development colleagues and started applying DevOps methodologies and concepts to their own complex data environments. This is what brought about the DataOps approach.
So, what is DataOps?
DataOps is the practice of leveraging software and data engineering, quality assurance, and infrastructure operations into a single nimble organization. DataOps optimizes how organizations develop and deploy data applications. It leverages process evolution, organizational alignment, and multiple technologies to enable relationships among everyone who participates in producing, moving, transforming, and consuming data: developers, data engineers, data scientists, analysts, and business users. It fosters collaboration, removes silos, and gives teams the ability to use data across the organization to make better business decisions. Overall, DataOps helps teams to collect and prepare data, analyze and make faster and more accurate decisions from a complete data set. DataOps also reduces data downtime or failures by monitoring data for quality.
What Problems Does DataOps Solve?
DataOps addresses a number of common challenges in your organization’s data environments, among them:
- Removing silos and promoting collaboration between teams: Data engineers, scientists, and analysts must collaborate. There has to be a massive cultural shift. Companies need to allow their employees to iterate rapidly with data-driven ideas.
- Improving efficiency and agility – Responding to bugs and defects can be dramatically minimized with greater levels of communication and collaboration between teams and the use of automation.
- Improving data quality: DataOps gives data professionals the ability to automatically format data and uses multiple data sources to help teams to analyze the data and make better decisions.
- Eliminating data downtime and failures since the data is monitored for data quality by the data teams.
What is Data Observability ?
“Data observability” provides the tools and methodologies to monitor and manage the health of an organization’s data across multiple tools and across the complete data lifecycle. Data observability allows organizations to proactively correct problems in real-time before the problems impact business users.
What is the relationship between Data Observability and DataOps?
Data observability is a framework that enables DataOps. DataOps teams use agile approaches to extract business value from enterprise data. But any problems with incorrect or inaccurate data could create serious challenges, especially if issues (aka data downtime) are not detected before they impact the business. Fortunately, with AI-powered data observability, organizations can detect, resolve and prevent data downtime.
Data Observability tools are concerned with data: Freshness, Statistical distribution, Volume, Schema, and Lineage. The correct use of data observability tools results in better quality data, enhanced trust, and a more operationally mature environment.
Who are the stakeholders in DataOps?
Surely, building a strong centralized data team that builds relationships between all of the departments within an organization is a key factor in achieving data operational maturity. The data team usually publishes the most relevant datasets, thus ensuring that decisions, analyses, and data models are done from a single source of truth. At the other end of the spectrum are the data analysts and line-of-business users who consume these datasets by asking questions and extracting answers from the data. Carefully and intentionally defining roles and responsibilities helps organizations avoid conflicts, redundancies, and inefficiencies.
DataOps Personas
Here are the most common profiles (aka personas) that take part in the data lifecycle:
- Data Engineers: These data professionals are in charge of capturing the data and building the pipelines that bring it from the source systems into data stores so that analysts and data scientists can access it. They publish core datasets after cleansing and transforming the data. They are in charge of providing timely data that is clean, curated, and accessible to those who need it. In the most traditional data environments the ETL (Extraction, Transformation, and Loading) acronym appears in their title.
- Data Scientists: Apply their knowledge of statistics to build predictive and prescriptive models. Their most common environments are Scala, Python, and R. Aside from statistics, they are generally experts in data mining, machine learning, and deep learning. The financial industry, for example, has traditionally referred to them as quants, because of their solid background in mathematics.
- Data Analysts/Business Analysts: Are data professionals who are generally part of line-of-business or functional groups (sales, marketing, etc.). They are familiar with how the organization operates, the strategic objectives, and where, and how data is needed. They transform business questions into data queries. They have a deep understanding of the information and key metrics executives need to measure and achieve their goals. They are experts at utilizing front-end BI (Business Intelligence) tools.
- Data Platform Administrators: Manage the infrastructure so that it works well, has ample capacity, and provides high quality of service to every department relying on it. They are responsible for transactional databases, data warehouses, data lakes, BI tools and so on. Additionally, they establish the access policies, control the infrastructure, and licensing costs.
- Line of Business Data Consumers: Are the final users of the data, and generally use the data to make decisions. They rely on BI tools and are responsible for taking action based on what the data says. For example, sales leaders may decide to invest more in a particular geography based on sales activity. Perhaps marketing managers may decide to allocate campaign funds to certain types of campaigns based on ROI metrics.
- Chief Data Officer: This person oversees the whole data team operation. Typically they report to the CEO, CTO, and sometimes the CIO.

Stakeholders in the DataOps process at PagerDuty
The diagram above places the stakeholders in their traditional area of responsibility within the DataOps process at PagerDuty. Undoubtedly, there will be varying degrees of overlap in different organizations.
DataOps at PagerDuty
At PagerDuty we have implemented a DataOps practice that leverages PagerDuty and a handful of our technology partners. By applying PagerDuty and DataOps principles we have been able to:
- Move away from several data warehouses to a single data warehouse where datasets from MuleSoft, Segment, Fivetran, Kafka, and Spark pipelines get consolidated into a single source of truth.
- Meet data SLAs from multiple data workloads by taking advantage of automation and data technology partnerships.
- Leverage Observability for Detection, Resolution, and Prevention of Incidents with our data – before users learn about it.
- Shift the focus of the data team from administrative tasks to data driven insights and data science.
- Future-proof our data environment to meet the demands of proliferating data use cases. These range from BI to new Artificial Intelligence (AI) applications from over 400 internal users in multiple departments and thousands of customers.

DataOps Environment at PagerDuty
The diagram above depicts several of the key components that make up our DataOps environment. While every organization’s data needs and data environment are unique, you can glean into the fact that our problems and architecture are not all that unique (multiple data warehouses, multiple ETL tools, strict SLAs, sprawling demand for datasets). More than likely, you are already spotting several shared high level problems as well as architectural similarities with your own data environment.
You can also leverage PagerDuty in your DataOps environment
The PagerDuty digital operations platform alerts data teams and downstream data users and consumers as soon as data issues arise to prevent data downtime. We are excited to announce our six currently published DataOps or data-related integrations within our ecosystem. These technology partners solve data pipeline and data quality problems across the organization. They improve collaboration, reduce friction, and reduce data failures by improving alignment:
- Monte Carlo: Provides end-to-end data observability, solving data downtime before it happens.
- Lightup: Helps enterprises achieve great data quality at cloud scale.
- Arize: A Machine Learning (ML) observability platform to monitor, troubleshoot, and resolve ML model issues.
- WhyLabs: Prevents costly AI failures by providing data and model monitoring
- Prefect: Build and monitor data pipelines with real-time alerting
- Astronomer: Reduces data downtime with real-time data monitoring on pipelines
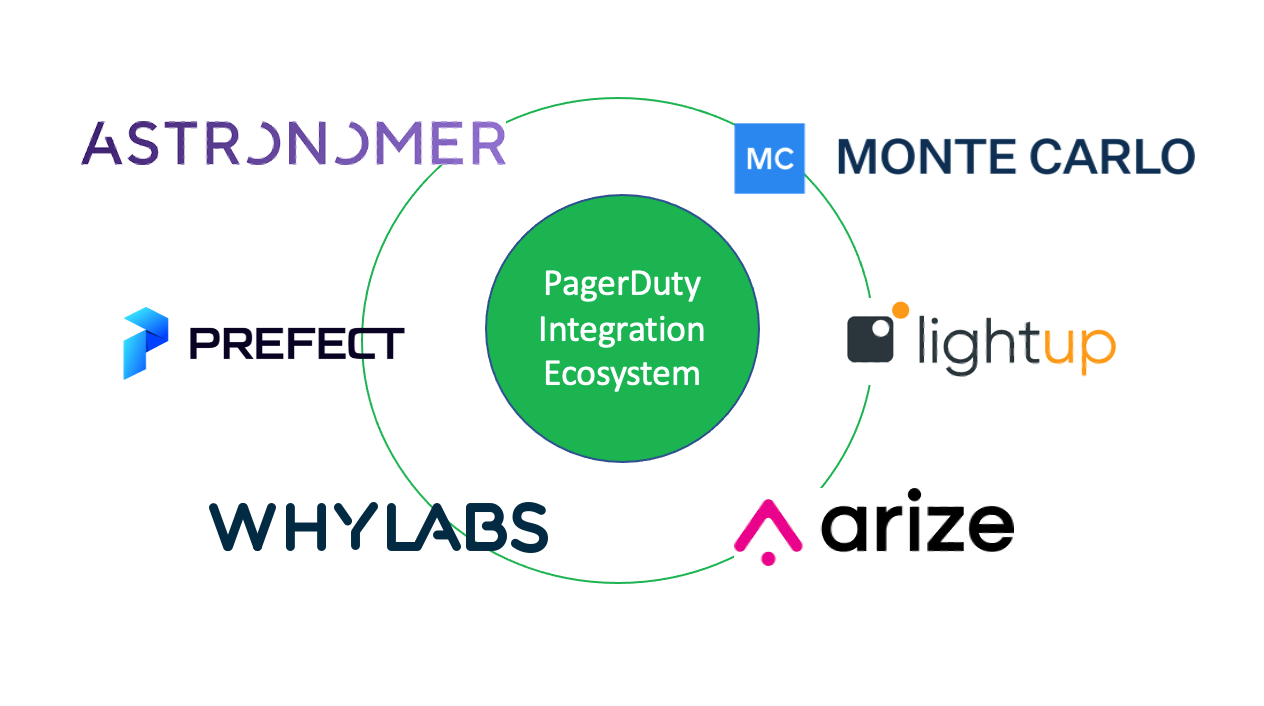
PagerDuty DataOps Ecosystem
Most importantly, these new DataOps integrations with PagerDuty cover key areas such as: data pipeline orchestration, testing and production quality, deployment automation, and data science/ML model management. We encourage you to try PagerDuty along with some of these PagerDuty ecosystem technology partners to help you drive tighter collaboration amongst cross-functional teams and achieve better and faster decisions with less data downtime. Similarly, if you are thinking about building a PagerDuty Integration, please sign up for a developer account to get started.