
APAC-Rückblick, Teil 2: Mobilisieren: Vom Signal zur Aktion
von David Ridge
4. Januar 2024 | 7 min Lesezeit
Fortsetzung unserer Serie über Erkenntnisse aus der Asien-Pazifik-Region für 2023 , Es wird immer deutlicher, dass es bei Vorfällen in Organisationen nicht um das „Ob“, sondern um das „Wann“ geht – und zwar unabhängig von der Größe oder Branche der Organisation.
In jüngster Zeit haben Regulierungsbehörden in der Region Asien-Pazifik strengere Maßnahmen gegen große Unternehmen wegen minderwertiger Dienstleistungen ergriffen. , was zu erheblichen Strafen führt. Abgesehen vom unmittelbaren Verlust von Einnahmen und Kundenvertrauen müssen diese Organisationen nun mit erheblichen finanziellen und betrieblichen Konsequenzen rechnen.
Da Unternehmen heute mit einer Reihe von Problemen konfrontiert sind, von größeren technischen Ausfällen bis hin zu Störungen der Cloud-Dienste und Bedrohungen der Cybersicherheit, müssen in ständiger Alarmbereitschaft und Vorbereitung sein. In diesem zweiten Teil unserer Blogserie werden wir die kritischen Phasen des Vorfalllebenszyklus genauer untersuchen und hervorheben, wie sich Organisationen auf das Unvermeidliche vorbereiten können: ihren nächsten Vorfall.

Teil 2: Mobilisieren: Vom Signal zur Aktion
Kurz zusammengefasst Das Incident Management erfordert von Organisationen, auf die unterschiedlichen Bedürfnisse der Stakeholder einzugehen. Die Implementierung automatisierter und benutzerfreundlicher Bereitschaftsmanagementsysteme ist entscheidend, um die mittlere Zeit bis zur Bestätigung (MTTA) zu verkürzen und die ersten Reaktionen zu beschleunigen. Bei größeren Incidents Die gleichzeitige Mobilisierung gezielter Einsatzgruppen sorgt für Zeiteffizienz, wenn es am wichtigsten ist. Darüber hinaus verbessert die Optimierung von Statusaktualisierungen von Vorfällen mit den entsprechenden Details für jede Person die Kommunikationseffektivität, sodass die Organisation die Berichterstattung verwalten und alle Parteien zuverlässig auf dem Laufenden halten kann.
Laut einer Aktueller Bericht und Umfrage von EMA Research , gehen die meisten Befragten davon aus, dass IT-Ausfälle und schwerwiegende Vorfälle entweder zunehmen (40 %) oder ungefähr gleich bleiben (27 %). Weitere 15 % der Teilnehmer gaben jedoch an, dass sie einen Anstieg erlebt haben, sagen aber, dass sie „die Auswirkungen mit AIOps und Automatisierung verringern können“, so der Bericht. Angesichts der steigenden Kosten und der Häufigkeit ungeplanter Ausfälle können es sich Unternehmen nicht leisten, für die Verwaltung ihrer Betriebsabläufe „ausreichend gute“ Lösungen und Prozesse für das Vorfallmanagement einzuführen.
So gerne wir uns auch durch Automatisierung und KI aus der Gefahrenzone begeben würden, im Mittelpunkt des Vorfallmanagements werden immer die Menschen stehen. Vorfälle sind naturgemäß ungeplante Arbeiten, die wir nicht vorhergesehen oder berücksichtigt haben und (zumindest abgesehen von bekannten Problemen) die Mobilisierung von Personen erfordern, die bei deren Verwaltung und Lösung helfen können. Je nach Auswirkung und Schwere des Vorfalls kann sich die Größe der erforderlichen Gruppe dramatisch ändern. Ob es sich nun um die Anrufung des Bereitschaftstechnikers handelt, der seine eigene Anwendung erstellt und betreibt, um das klassische ITIL-Framework Tier 1, 2, 3+ oder um einen größeren Vorfall, der zentral von Dutzenden Mitarbeitern verwaltet wird – die richtigen Personen auf einen Vorfall aufmerksam zu machen und darauf zu reagieren, kann oft die größte Zeitverschwendung im Lebenszyklus sein.
Den Weg des geringsten Widerstands entwerfen
Der Hauptgrund für diese Zeitverschwendung sind die Menschen.
Genauer gesagt, manuelle Prozesse und veraltete Aufzeichnungen. Wenn man die Leute sich selbst überlässt, werden sie oft Wählen Sie den Weg des geringsten Widerstands – das menschliche Gehirn ist darauf programmiert. In diesem Szenario bedeutet das, dass Sie einfach manuell die Person anrufen, die Sie kennen, oder die Person, die das Problem beim letzten Mal behoben hat, oder sogar nur den Manager des Teams, und diese Person entscheiden lassen, wen Sie anrufen. Dies mag wie die schnellste und einfachste Lösung erscheinen, um eine Reaktion zu mobilisieren, ist aber ein kurzfristiger Erfolg, der bei der geringsten Belastung und Komplexität zusammenbricht.
-
- Welches Team besitzt das betroffene System?
- Wer hat derzeit für dieses Team Bereitschaftsdienst?
- Was passiert, wenn sie nicht antworten?
- Wie lange wartest du?
- Wen sollten Sie sonst noch anrufen?
- Und was ist, wenn sie Urlaub haben?
- Soll noch jemand einbezogen werden?
Das Beantworten all dieser Fragen nimmt Zeit in Anspruch und erfordert die manuelle Ausführung mehrerer Schritte.
Selbst wenn viele dieser Prozesse vorhanden sind, benötigen die Mitarbeiter Flexibilität. Mitarbeiter gehen in Urlaub, werden krank oder haben persönliche Notfälle, aufgrund derer sie kurzfristig nicht verfügbar sind. Diese alltäglichen Vorkommnisse sind einfache Dinge, die eine manuelle oder tabellenbasierte Vorgehensweise bei der Verwaltung von Bereitschaftsplänen überfordern.
Damit ein menschenzentrierter Prozess funktioniert, müssen wir grundsätzlich sicherstellen, dass der Weg des geringsten Widerstands auch der richtige ist.
Moderne Organisationen benötigen eine automatisierte Lösung, um die entsprechende Reaktion auf einen Vorfall zu mobilisieren. Dieses System muss das Service-Ownership-Modell innerhalb der Organisation berücksichtigen, aber auch flexibel genug sein, um mit dem sich ständig weiterentwickelnden Explosionsradius von Vorfällen umzugehen. Darüber hinaus muss es den Menschen gerecht werden, die Nutzen Sie es, mit einfachem Wechsel der Ansprechpartner, automatisierten Eskalationen und mehreren Kommunikationsmodi.
Diese Anforderungen sind bei einem schwerwiegenden Vorfall noch geschäftskritischer als bei einem DevOps-Ingenieur, der um 2 Uhr morgens aus dem Bett gesprungen ist. Ohne eine automatisierte Lösung müssen die Manager schwerwiegender Vorfälle diesen Prozess für jeden erforderlichen Teamvertreter durchlaufen. Und wie wir im vergangenen Jahr wiederholt gesehen haben, ist Zeit ein entscheidender Faktor. In den ersten Minuten eines Vorfalls ist es entscheidend, die richtigen Leute so schnell wie möglich zusammenzubringen, um mit dem Vorfallreaktionsprozess zu beginnen. Wenn es gelingt, einem möglichen Ausfall zuvorzukommen, bevor er Auswirkungen auf die Kunden hat, kann dies oft den Unterschied zwischen einem normalen Betriebstag und einem Auftritt in den Morgennachrichten ausmachen.
Daher gibt es voreingestellte Szenarien oder systemspezifische automatisierte Workflows, die bei der Meldung eines schwerwiegenden Vorfalls ausgelöst werden können. können die ersten 30 Minuten eines Vorfalls in die ersten 30 Sekunden verwandeln.
Keine Nachrichten sind schlechte Nachrichten
Eine der Lehren, die wir aus den Vorfällen des vergangenen Jahres ziehen können, ist, dass Schweigen nicht immer gut ausgeht. Regelmäßige Updates für die verschiedenen Interessengruppen sind ein Muss. Ohne sie suchen die Interessengruppen nach ihren eigenen Updates und der offizielle Kanal verliert die Kontrolle über die Berichterstattung. Spekulationen und Nebengeschichten wird zum neuesten Update und die Wahrnehmung des Vorfalls wird möglicherweise größer als der Vorfall selbst.
A Der Schlüssel zur Verwaltung des Vorfallberichts ist eine optimierte Stakeholder-Kommunikation – die Möglichkeit, personenbasierte Kommunikationskanäle für interne und externe Stakeholder einzurichten. Stakeholder sollten die Flexibilität haben, die Systeme und Dienste zu abonnieren, die ihnen wichtig sind (auch sie können Lärm machen!), aber Vorfallmanager sollten auch die Möglichkeit haben, ein Update an jeden weiterzuleiten, der ihrer Meinung nach informiert sein muss.
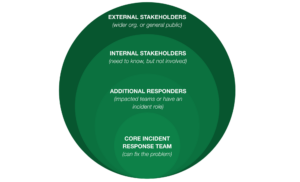
Hier kommen unsere immer größer werdenden Kommunikationskreise ins Spiel. Unterschiedliche Interessengruppen benötigen möglicherweise unterschiedliche Detailebenen. Einige interne Begriffe und Systemnamen lassen sich möglicherweise nicht extern übersetzen. Ebenso ist ein Update eines Slack- oder Teams-Kanals möglicherweise nicht für die stark formatierte und strukturierte E-Mail geeignet, die an das Führungsteam gesendet wird.
Persona-basierte Kommunikationsvorlagen können die statischen, wiederholbaren Daten automatisch ausfüllen, aber auch generative KI verwenden, um ein entsprechendes Statusupdate zur Genehmigung zu erstellen. Sie können modernen Organisationen helfen, den Aufwand der Großschadensmanager zu reduzieren. damit sie sich auf die Wiederherstellung des Dienstes konzentrieren können. Darüber hinaus wird dieses Update automatisch direkt an einen externen Kommunikationsspezialisten gesendet, der es über Updates der externen Statusseite für externe Stakeholder und/oder die Öffentlichkeit anpassen und freigeben kann. So wird sichergestellt, dass die Vorfallkommunikation konsistent und regelmäßig erfolgt.
Zusammenfassend lässt sich sagen, dass es für Organisationen wichtig ist, die Bedürfnisse der verschiedenen Gruppen zu verstehen, wenn es um Meldungen und Kommunikation bei Vorfällen geht. Eine automatisierte und benutzerfreundliche Methode für das Bereitschaftsmanagement kann die mittlere Zeit bis zur Bestätigung (MTTA) für Ersthelfer erheblich verkürzen. Wenn dies ausgeweitet wird, um bei größeren Vorfällen gleichzeitig mehrere gezielte Gruppen von Helfern zu mobilisieren, kann sichergestellt werden, dass keine kostbare Zeit verschwendet wird, wenn es am wichtigsten ist. Schließlich wird durch die Optimierung der Statusaktualisierungen von Vorfällen, sodass jede Person den entsprechenden Detaillierungsgrad erhält, sichergestellt, dass die Organisation die Berichterstattung verwalten und alle zuverlässig auf dem Laufenden halten kann.
Ein Blick nach vorn
In Teil 3: Triage werde ich auf die verschiedenen Aufgaben, Aktionen und Runbooks eingehen, die während eines Vorfalls verwendet werden, um zu sehen, wie Organisationen ihr Stammeswissen sicher demokratisieren und Level-1-Teams und Junior-Ingenieure befähigen können, die Größe und Dauer eines Vorfalls zu reduzieren. Wir werden uns auch einige Möglichkeiten ansehen, den Vorfallprozess zu optimieren, indem einige der Runbooks vollständig automatisiert werden.
Möchten Sie mehr erfahren?
Wir werden auch Wir veranstalten eine dreiteilige Webinar-Reihe, die sich auf die Gewinn- und Verlustrechnung konzentriert und zeigt, wie diese den Kunden geholfen hat, sich auf Wachstum und Innovation zu konzentrieren. Klicken Sie auf die folgenden Links, um mehr zu erfahren und sich anzumelden:
- 07. Februar 2024: Teil 1: Optimierung des Incident Managements: Produktivitätssteigerung für einen höheren ROI
- 21. Februar 2024: Teil 2: Neugestaltung und Optimierung der Reaktion auf Vorfälle mit KI und Automatisierung
- 26. bis 29. Februar 2024: PagerDuty101 (Anmeldungen beginnen in Kürze)

