- PagerDuty /
- Der Blog /
- Best Practices und Einblicke /
- APAC-Rückblick: Erkenntnisse aus einem Jahr voller technischer Ausfälle, Wiederherstellung: Reparatur vs. Grundursache
Der Blog
APAC-Rückblick: Erkenntnisse aus einem Jahr voller technischer Ausfälle, Wiederherstellung: Reparatur vs. Grundursache
von David Ridge
22. Januar 2024 | 7 min Lesezeit
Während unsere Erkundung des Jahres 2023 von der dritter Teil unserer Blogserie, Wissenssilos abbauen , Eine unbestreitbare Tatsache bleibt bestehen: Vorfälle sind für Unternehmen eine unvermeidliche Realität, unabhängig von ihrer Branche oder Größe.
Aktuelle Trends in der Region Asien-Pazifik zeigen, dass Regulierungsbehörden bei schlechten Serviceleistungen härter gegen Großunternehmen vorgehen und harte Strafen verhängen. Die Folgen eines solchen Vorfalls sind nicht mehr nur Umsatzverluste und Vertrauensverluste, sondern auch hohe Geldstrafen und Einschränkungen des Geschäftsbetriebs.
Angesichts einer Reihe von Störungen, die von größeren technischen Pannen bis hin zu Ausfällen von Cloud-Diensten und Cybersicherheitsrisiken reichen, müssen Unternehmen heute strategisch auf Vorfälle reagieren können. In dieser vierten Folge navigieren wir weiter durch die kritischen Phasen des Vorfalllebenszyklus und geben Organisationen Erkenntnisse, um sich auf das vorzubereiten, was nun unvermeidlich ist: ihren nächsten Vorfall.

Teil 4: Wiederherstellen: Reparatur vs. Grundursache
In der modernen Landschaft komplexer Systeme wird die Debatte darüber, ob die Wiederherstellung des Dienstes Vorrang vor der Behebung der Grundursache hat, weiterhin bestehen. Es ist entscheidend, das richtige Gleichgewicht zu finden. Eine sofortige Wiederherstellung des Dienstes schützt das Unternehmen vor finanziellen Verlusten und sorgt für die Kundenzufriedenheit. Standardisierte und automatisierte Wiederherstellungsverfahren sind hierfür von entscheidender Bedeutung. Eine klare Definition von „Gelöst“ ist für zuverlässige Messgrößen und ein effektives Vorfallmanagement von entscheidender Bedeutung. Um jedoch die Genauigkeit und Nützlichkeit von Messgrößen wie MTTR aufrechtzuerhalten, ist die Möglichkeit erforderlich, die Granularität dieser Messgrößen wie MTTR zu filtern und anzupassen.
Bei einem IT-Ausfall geht es vor allem um die schnelle Wiederherstellung der Dienste. Im vergangenen Jahr haben wir erlebt, wie Ausfallzeiten zu erheblichen finanziellen Verlusten, Rufschädigungen für Marken und Störungen im Kundenservice führen können. In solchen kritischen Situationen verlagert sich der Fokus von der Analyse der Grundursache auf die schnelle Wiederherstellung der betroffenen Systeme. Die Philosophie dabei ist unkompliziert und kann von einigen Grundprinzipien geleitet werden:
- Verfügbarkeit ist Geld : In unserer digitalen Welt ist die Verfügbarkeit in hohem Maße mit dem Umsatz verbunden. Je länger die Dienste unterbrochen bleiben, desto größer sind die finanziellen Auswirkungen für das Unternehmen. Die Wiederherstellung der Dienste stellt sicher, dass das Unternehmen den Betrieb schnell wieder aufnehmen kann, wodurch potenzielle finanzielle Verluste gemindert werden.
- Kundenerwartungen : Ob interne Mitarbeiter oder externe Kunden, Endbenutzer fordern einen unterbrechungsfreien Zugriff auf Dienste. Eine schnelle Wiederherstellung sichert nicht nur die Kundenzufriedenheit, sondern verhindert auch negative Auswirkungen auf den Ruf des Unternehmens.
- Betriebskontinuität : Manche Probleme haben möglicherweise keine unmittelbare, eindeutige Ursache. Ein langwieriger Prozess zur Identifizierung und Behebung des zugrunde liegenden Problems steht möglicherweise nicht im Einklang mit der Notwendigkeit der Betriebskontinuität. Die Wiederherstellung des Dienstes ermöglicht es der Organisation, weiter zu funktionieren, während eine gründlichere Untersuchung durchgeführt wird.
Temporäre Lösungen, bis das Problem behoben ist
Die Identifizierung der Grundursache eines IT-Vorfalls ist ein entscheidender Schritt zur Vermeidung künftiger Vorfälle. Allerdings kann die Behebung des zugrunde liegenden Problems zeitaufwändig sein, insbesondere wenn ein vollständiger Entwicklungs- und Testzyklus erforderlich ist. In vielen Fällen arbeiten Unternehmen mit komplexen Systemen und Abhängigkeiten, was es schwierig macht, die genauen Auswirkungen von Änderungen vorherzusagen.
Stellen Sie sich ein Szenario vor, in dem ein kritischer Fehler erkannt wird und das Betriebsteam ihn auf eine kürzlich erfolgte Codebereitstellung zurückführt. Bei der Untersuchung der Grundursache stellen sie fest, dass die Behebung des zugrunde liegenden Problems Änderungen in mehreren Modulen und umfangreiche Tests erfordert. Oder vielleicht ist es einfach 2 Uhr morgens und nicht gerade die beste Zeit, um mit dem Programmieren zu beginnen!
Die richtige Vorgehensweise, insbesondere bei einem Dienstausfall, wäre ein schnelles Rollback der Änderung, die den Fehler verursacht hat. Ein Rollback ermöglicht es der Organisation, schnell zu einem bekannten stabilen Zustand zurückzukehren und entspricht dem Ziel, Ausfallzeiten zu minimieren und die Dienste umgehend wieder online zu bringen. Dieser Ansatz beseitigt auch den Stress einer tickenden Uhr über den Köpfen der Entwickler, die versuchen, das Problem zu beheben.
Eine weitere Strategie im Zusammenhang mit der Wiederherstellung von Diensten ist die Implementierung vorübergehender Maßnahmen, z. B. das Hinzufügen weiterer Ressourcen, um kritische Dienste am Laufen zu halten. Bei diesem Ansatz wird berücksichtigt, dass die Behebung des zugrunde liegenden Problems einige Zeit in Anspruch nehmen kann und sich das Unternehmen keine längeren Ausfallzeiten leisten kann.
Wenn beispielsweise ein unerwarteter Anstieg der Benutzeraktivität die vorhandene Infrastruktur überfordert, kann eine vorübergehende Skalierung der Ressourcen oder das Hinzufügen zusätzlicher Rechenleistung die unmittelbare Belastung lindern. Dies behebt zwar möglicherweise nicht die Grundursache der erhöhten Nachfrage, stellt jedoch sicher, dass die Dienste betriebsbereit bleiben, und verschafft Zeit für eine gründlichere Untersuchung und die Implementierung einer langfristigen Lösung.
Ein kombinierter Ansatz
Für beide Szenarien ist Automatisierung der Schlüssel.
Im vorherigen Beitrag haben wir erläutert, wie Unternehmen die Triage-Phase des Vorfalllebenszyklus beschleunigen und die Grundursache ermitteln können. Ein ähnlicher Ansatz kann bei der Wiederherstellung von Diensten verfolgt werden. Wenn die Betriebstools mit einem einzigen Klick verfügbar sind, um Standardwiederherstellungsverfahren wie das Zurücksetzen einer Bereitstellung oder die Erhöhung der Ressourcen durchzuführen, kann dies den Druck verringern und wertvolle Zeit sparen.
Die Argumente dafür, der Wiederherstellung von Diensten Vorrang vor der Behebung der Grundursache zu geben, verwischen manchmal die Grenzen zwischen Vorfallmanagement und Problemmanagement. Beim Vorfallmanagement geht es darum, Dienste schnell wiederherzustellen, während beim Problemmanagement die Grundursachen wiederkehrender Vorfälle ermittelt und beseitigt werden sollen. Für die Aufrechterhaltung einer robusten und widerstandsfähigen IT-Umgebung ist es wichtig, zwischen diesen beiden Aspekten ein Gleichgewicht zu finden.
In bestimmten Situationen kann ein gemischter Ansatz gewählt werden. Dabei werden vorübergehende Maßnahmen zur schnellen Wiederherstellung des Dienstes umgesetzt, während gleichzeitig eine parallele Untersuchung der Grundursache durchgeführt wird. Der Schlüssel liegt darin, ein pragmatisches Gleichgewicht zu finden, das die Ausfallzeiten minimiert, ohne endlos Patches durchzuführen oder die langfristige Stabilität der IT-Infrastruktur zu vernachlässigen.
Für betrieblich ausgereifte Organisationen ist die Automatisierung standardmäßiger Wiederherstellungsverfahren erforderlich, die von den Betriebsteams in Sekundenschnelle aufgerufen werden können, um ihnen den Puffer zu geben, den sie zum Beheben zugrunde liegender Probleme ohne unnötige Ausfallzeiten benötigen.
MTTR – Repariert oder gelöst?
Im Bereich des Incident Managements hat der Begriff „Gelöst“ eine erhebliche Bedeutung. Erfahrene Organisationen erkennen die Bedeutung einer klaren Definition von „Gelöst“ an, um Kennzahlen wie die mittlere Zeit bis zur Lösung (MTTR) sicher verwenden und Service Level Agreements (SLAs) einhalten zu können.
Die Lösung von Vorfällen kann jedoch manchmal unklar sein. Die unmittelbare Störung kann zwar behoben werden, das zugrunde liegende Problem kann jedoch weiterhin bestehen oder eine Benutzerüberprüfung erforderlich sein. Dadurch entsteht ein Dilemma, ob der Vorfall wirklich als gelöst betrachtet werden kann.
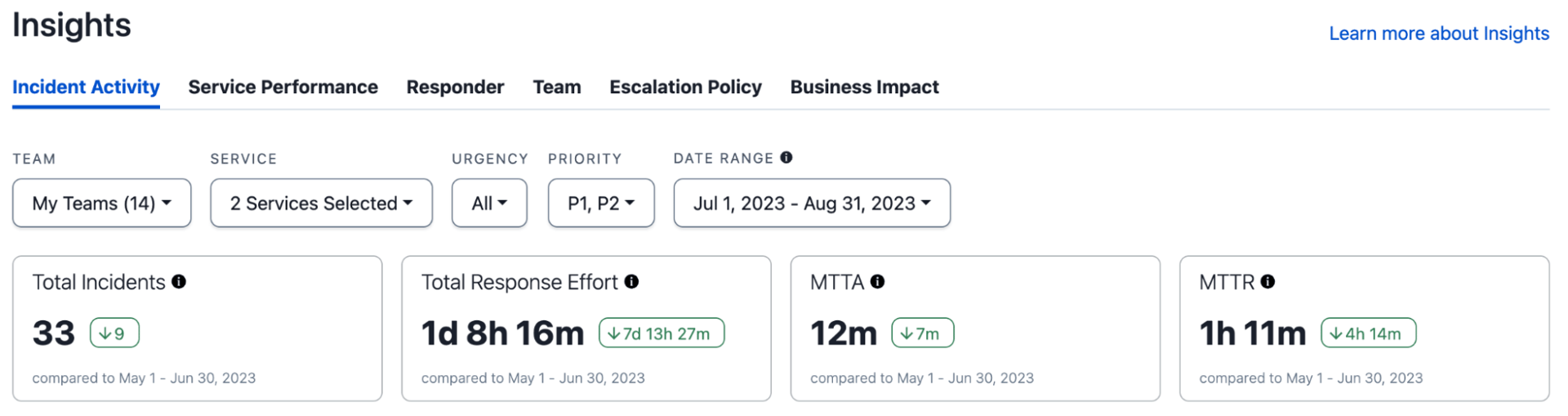
Kennzahlen wie MTTR und SLAs sind für die interne und externe Bewertung der Leistung einer Organisation bei der Reaktion auf Vorfälle von entscheidender Bedeutung. Ohne eine klare Definition der Lösung können diese Kennzahlen jedoch ein falsches Sicherheitsgefühl oder ein verzerrtes Bild der Realität vermitteln. Organisationen wissen, dass eine genaue Definition des Zeitpunkts, zu dem ein Vorfall tatsächlich gelöst ist, sowie ein Bericht erforderlich sind, mit dem dies auf verschiedenen Ebenen der Granularität und Priorität genau verfolgt und gemessen werden kann.
Diese Granularität ist entscheidend, wenn wir eine Metrik wie den „Mittelwert“ verwenden. Es gibt keine Obergrenze für die Dauer eines Vorfalls, daher können die Ergebnisse bei Stichprobengrößen, die nicht normal verteilt sind, verzerrt sein. Für einen hervorragenden Einblick in MTTR, dieser kürzlich veröffentlichte Blog beschreibt die Vorteile und Herausforderungen perfekt.
Letztlich geht es bei einem pragmatischen Ansatz darum, den Kontext jedes Ausfalls zu verstehen und den effizientesten Weg zu wählen. Das Hauptziel der Betriebsteams sollte immer darin bestehen, Ausfallzeiten zu minimieren und die Geschäftskontinuität sicherzustellen. Während die Beseitigung der Grundursache entscheidend ist, um zukünftige Vorfälle zu verhindern, müssen Unternehmen die Dringlichkeit der Wiederherstellung des Dienstes gegen die potenziellen Verzögerungen abwägen, die mit einer umfassenden Fehlersuche und -behebung verbunden sind.
Die schnelle Wiederherstellung von Diensten, selbst durch vorübergehende Maßnahmen oder Rollbacks, kann eine strategische Entscheidung sein, die den unmittelbaren Bedürfnissen des Unternehmens entspricht. Dieser Ansatz berücksichtigt die realen Herausforderungen komplexer Umgebungen und die unvorhersehbare Natur von Vorfällen. Die richtige Balance zwischen Vorfallmanagement und Problemmanagement in Kombination mit der Fähigkeit, dies genau zu messen, stellt sicher, dass Unternehmen die komplizierte Balance zwischen schneller Wiederherstellung und langfristiger Stabilität meistern können.
Ein Blick nach vorn
In unserem fünften und letzten Beitrag fassen wir unsere Reise durch den Vorfalllebenszyklus zusammen, um zu verstehen, wie wir die Prinzipien der kontinuierlichen Verbesserung und des Lernens nutzen können, um das Vorfallmanagement bei jedem Vorfall iterativ zu verbessern.
Möchten Sie mehr erfahren?
Wir werden auch eine dreiteilige Webinar-Reihe veranstalten, die sich auf die Gewinn- und Verlustrechnung konzentriert und zeigt, wie sie den Kunden geholfen hat, sich auf Wachstum und Innovation zu konzentrieren. Klicken Sie auf die folgenden Links, um mehr zu erfahren und sich anzumelden:
- 07. Februar 2024: Teil 1: Besseres Incident Management: Vermeidung kritischer Serviceausfälle im Jahr 2024
- 21. Februar 2024: Teil 2: Von der Krise zur Kontrolle: Wie Sie das Incident Management mithilfe von Automatisierung und KI modernisieren können
- 26. bis 29. Februar 2024: Teil 3: PagerDuty 101