
APAC-Rückblick: Erkenntnisse aus einem Jahr voller Tech-Turbulenzen
von David Ridge
18. Dezember 2023 | 6 min Lesezeit
Im Jahr 2023 ist eines mehr als deutlich geworden: Unabhängig von der Größe einer Organisation oder Branche sind Vorfälle unvermeidlich.
In letzter Zeit haben wir in der gesamten Region Asien-Pazifik erlebt, wie zahlreiche Regulierungsbehörden gegen große Unternehmen vorgegangen sind, die keinen akzeptablen Service bieten, wobei einige von ihnen recht hohe Strafen verhängt haben. Für viele sind die Kosten eines Vorfalls nicht mehr nur Umsatzverluste und Kundenvertrauen, sondern auch finanzielle Strafen und Geschäftseinschränkungen.
Unabhängig davon, ob es sich um erhebliche technische Störungen, Unterbrechungen der Cloud-Dienste oder Bedrohungen der Cybersicherheit handelt, müssen moderne Unternehmen proaktiv planen und sich auf mögliche Vorfälle vorbereiten.
In dieser Blogserie befassen wir uns mit den fünf Phasen des Vorfalllebenszyklus und bieten Einblicke in die Maßnahmen, die Unternehmen ergreifen sollten, um auf das Unvermeidliche vorbereitet zu sein … ihren nächsten Vorfall.

——————————–
Teil 1: Erkennen: Das Rauschen filtern
Wir würden wetten, dass sich inmitten des ganzen Chaos aufgrund der jüngsten Ausfälle und Vorfälle dieses Jahres irgendwo in all dem Lärm die Warnung befand, die wirklich wichtig war.
Beobachtbarkeit ist ein grundlegendes Element jedes robusten Systems. Ursprünglich stammt der Begriff aus traditionellen Überwachungsfunktionen, hat sich jedoch mit zunehmender Komplexität der Systeme erheblich weiterentwickelt und bietet eine bessere Sicht auf Geschäftsprozesse und Kundenreisen. Das Verständnis der Leistung Ihres Unternehmens über verschiedene Zeiträume und Arbeitslasten hinweg ist nicht nur für die betriebliche Exzellenz, sondern auch für die Förderung des Unternehmenswachstums von entscheidender Bedeutung.
Eine umfassende Überwachung hat jedoch ihren Preis. Da die Kosten für die Datenerfassung sinken, erfassen Überwachungsanwendungen nun immer mehr Daten. Das ist großartig für die Analyse, aber das Problem liegt darin, dass die Warnmeldungen im gleichen exponentiellen Tempo zunehmen. Die Menschen werden gegenüber Warnmeldungen stumpf, was sie weniger effektiv macht.
Viele Organisationen ertrinken im Signalrauschen der Hunderten von Metriken, die jede Minute von ihren verschiedenen Observability-Tool-Suiten ausgelöst werden. Mit zunehmender Komplexität und enormen Abhängigkeits-Todessternen (wir meinen euch, Microservices!) steigt die Wahrscheinlichkeit, auf etwas aufmerksam gemacht zu werden, das vorgelagert und außerhalb Ihrer Kontrolle liegt, immer weiter an. Wie können wir also dieses Problem lösen?
Irgendwann wird jede dieser vielen Warnungen nützlich sein und eine Reaktion erfordern. Wir können also nicht einfach willkürlich 30 % unserer Warnungen abschalten, um eine Rauschreduzierung von 30 % zu erreichen. Wir benötigen eine ganzheitliche Sicht und wir brauchen Kontext.
Nicht alle Warnungen sind gleich … es kommt darauf an.
Um Ihre Warnungen zu verstehen, müssen Sie Ihre Systeme verstehen.
Nicht alle Dienste sind gleich. Wenn also eine Warnung ausgelöst wird, sollten Sie mit einer entsprechenden Antwort reagieren.
Was ist die angemessene Antwort? Nun, es kommt darauf an …
- Welcher Dienst ist betroffen?
- Wie spät ist es?
- Bietet dieser Dienst Support rund um die Uhr oder nur während der Geschäftszeiten?
- Welchen Schweregrad hat die Warnung?
- Um welche Art von Alarm handelt es sich?
- Kann ich das unterdrücken?
- Haben wir hierzu bereits einen Vorfall gemeldet?
- Wie oft ist das schon passiert?
- Hat das etwas anderes damit zu tun?
- Hat sich in letzter Zeit etwas geändert?
- Ist eine Person überhaupt erforderlich?
- Ist das ein bekanntes Problem?
- Wird es wie immer innerhalb von 2 Minuten automatisch gelöst?
- Können wir es automatisch beheben?
Wenn Sie für alle Alarme die gleiche Warnrichtlinie und den gleichen Warnmechanismus haben und keine Möglichkeit haben, die wichtigen und umsetzbaren Alarme von denen zu filtern, die keiner sofortigen Aufmerksamkeit bedürfen, werden die Empfänger dieser Alarme irgendwann alarmmüde und schalten ab. Sie reagieren erst, wenn das Major Incident Management-Team anruft.
Moderne Unternehmen können es sich nicht mehr leisten, dies manuellen Eventmanagement- und Ticketing-Warteschlangen zu überlassen. Sie benötigen eine automatisierte Lösung, die die Größe und Komplexität großer moderner Systeme bewältigen kann und die die richtigen Filter bereitstellt, um die relevanten Warnmeldungen innerhalb von Sekunden an die richtige Person weiterzuleiten und mit der entsprechenden Antwort zu korrelieren.
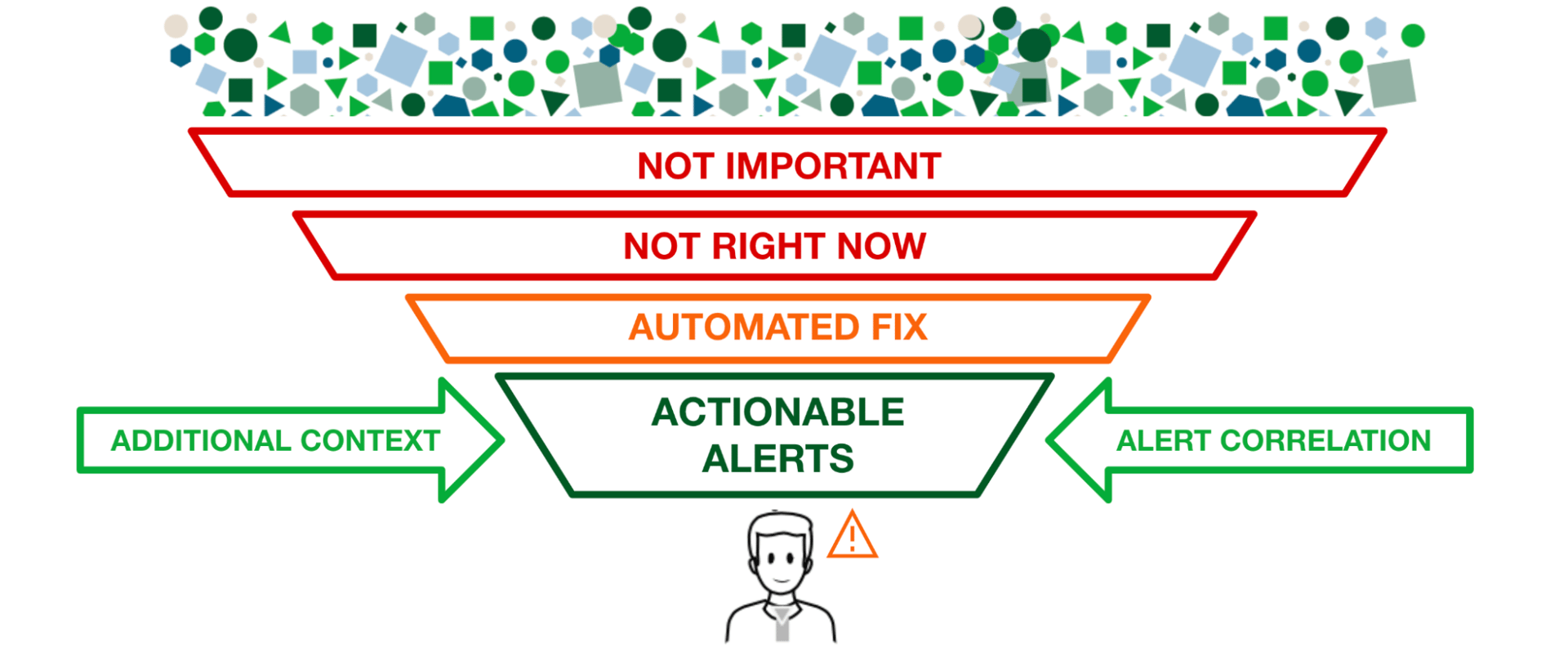
Kontext und Relevanz sind der Schlüssel zum Alarmmanagement.
Die Weiterentwicklung des grundlegenden Eventmanagements zu modernen AIOps hat eine Reihe neuer Funktionen mit sich gebracht, die es Unternehmen ermöglichen, ihre Warnmeldungen im Kontext eines ständig wachsenden Datensatzes zu verstehen. Algorithmen für maschinelles Lernen können anhand historischer Muster erkennen, ob es sich bei einer Warnmeldung tatsächlich um eine Anomalie handelt und wie häufig diese Warnmeldung auftritt. Ebenso kann eine ganzheitliche Ansicht aller relevanten, aktiven Warnmeldungen und Vorfälle, angereichert mit dem Kontext ihrer Abhängigkeiten, einer einzelnen Warnmeldung eine dringend benötigte Perspektive verleihen und möglicherweise einen kaskadierenden Fehler mit einem wahrscheinlichen Ursprung oder einen direkten Abhängigkeitsfehler aufzeigen.
Egal, ob Sie ein einzelner DevOps-Ingenieur sind, der für Ihre eigene Anwendung auf Abruf bereitsteht, ein Level-1-Support-Ingenieur, der für die Bewertung von Warnungen aus mehreren Systemen verantwortlich ist, oder ein Major Incident Manager, der versucht, den Explosionsradius einer fehlgeschlagenen Änderung einzuschätzen: Wenn Sie sofort einen Kontext darüber haben, was sonst noch in der Organisation passiert und welche Vorgänge für Ihren Vorfall besonders relevant sind, können Sie zu Beginn eines Vorfalls entscheidende Minuten (sogar Stunden) sparen, um sicherzustellen, dass Sie sich auf die richtigen Signale konzentrieren und nicht durch falsche Positivmeldungen in die Irre geführt werden.
Das Ziel für Organisationen besteht darin, auf der Reifeskala von einem reaktiven zu einem proaktiven und idealerweise zu einem präventiven Prozess aufzusteigen. Dies erfordert jedoch eine Verlagerung der Incident Response von schwerwiegenden Incidents mit bekannten Auswirkungen auf den Kunden hin zu einer Reaktion auf Frühindikatoren für Ausfälle oder Leistungseinbußen und zur Behebung des Problems, bevor es überhaupt zu Auswirkungen auf den Kunden kommt. Dies kann nur mit einer Art Intelligenz oder AIOps-Fähigkeit erreicht werden, um die beteiligten umfassenderen Elemente zu verstehen, sofort relevanten Kontext bereitzustellen und letztlich das Rauschen herauszufiltern.
In Teil 2: Mobilisieren werden wir erläutern, wie Organisationen das menschliche Reaktionselement im Lebenszyklus eines Vorfalls optimieren können. Von Ersthelfern und Managern wichtiger Vorfälle bis hin zu Geschäftspartnern und sogar der Öffentlichkeit werden wir uns damit befassen, was auf jeder Ebene der Vorfallkommunikation erforderlich ist.
Möchten Sie mehr erfahren?
Wir werden auch eine 3-Stufen-Webinarreihe anbieten. Diese Webinare konzentrieren sich auf die Gewinn- und Verlustrechnung und wie diese den Kunden geholfen hat, sich auf Wachstum und Innovation zu konzentrieren. Klicken Sie unten, um mehr zu erfahren und sich anzumelden:
07. Februar 2024: Teil 1: Optimierung des Incident Managements: Produktivitätssteigerung für einen höheren ROI
21. Februar 2024: Teil 2: Neugestaltung und Optimierung der Reaktion auf Vorfälle mit KI und Automatisierung
26. bis 29. Februar 2024: PagerDuty101 (Anmeldungen beginnen in Kürze)

