
- PagerDuty /
- Der Blog /
- Automatisierung /
- Schnell! Sichern Sie sich alle Beweise: Erfassen Sie den Anwendungsstatus für die Forensik nach einem Vorfall.
Der Blog
Schnell! Sichern Sie sich alle Beweise: Erfassen Sie den Anwendungsstatus für die Forensik nach einem Vorfall.
von Jake Cohen
9. Februar 2023 | 5 Minuten Lesezeit
Dies ist der erste Teil einer mehrteiligen Blogserie. Im nächsten Blog stellen wir einen Vorlagenjob vor, der Kubernetes-Ephemeralcontainer um Beweise von Anwendungen zu erfassen, die in Kubernetes ausgeführt werden.
Jeder liebt einen guten Mystery-Thriller. Okay, nicht jeder – aber Hollywood schon. Ob Sherlock Holmes oder Hercule Poirot – das Publikum genießt eine fesselnde Geschichte über die Jagd nach dem Täter eines abscheulichen Verbrechens. Viele, mich eingeschlossen, bevorzugen Mystery-Thriller, bei denen das Rätsel am Ende „gelöst“ ist. Cliffhanger können zwar die Fantasie anregen, die möglichen Ausgänge zu durchdenken (erinnern Sie sich an das Ende von Chris Nolans „Inception“?), aber bei Kriminalromanen bevorzuge ich es zugegebenermaßen, die Antwort auf die Frage „Wer war der Täter?“ zu kennen.

Quelle: https://www.dazeddigital.com/artsandculture/article/24949/1/christopher-nolan-explains-the-spinning-top-in-inception
Damit ein Kriminalroman einen vollständigen Abschluss findet, müssen die Beweise für das Verbrechen idealerweise kristallklar und detailliert dargelegt sein, sodass der wahre Täter entlarvt und hoffentlich vor Gericht gestellt werden kann.
Im technischen Betrieb und bei der Aufrechterhaltung der Verfügbarkeit kritischer Dienste entsteht ein offensichtlicher Konflikt, der an einen Hollywood-Krimi erinnert. Wenn kritische Anwendungen unter Leistungseinbußen leiden – oder schlimmer noch, komplett ausfallen –, suchen Ingenieure umgehend nach der (scheinbaren) Ursache des Vorfalls, um das Problem schnellstmöglich beheben zu können. Die Teams nutzen die ihnen zur Verfügung stehenden Tools, um die überlastete Rechenressource, die blockierte Abfrage oder die überfüllte Warteschlange zu identifizieren und zu isolieren und umgehend Maßnahmen zur Behebung des Problems zu ergreifen.
Wie sich herausstellt, ist dies jedoch erst der Anfang des Krimis. In diesem Krimi vermuten die Zeugen, dass der Täter die Person ist, die zufällig zur falschen Zeit am falschen Ort war. Doch je mehr Beweise auftauchen, desto klarer wird, dass der „wahre Täter“ ein böses Genie war, das aus der Ferne einen größeren Plan ausheckte. Unglücklicherweise für unsere „Detektiv“-Ingenieure besteht bei der Beseitigung der (scheinbaren) Grundursache eine hohe Wahrscheinlichkeit, dass sie [un]wissentlich Beweise vernichtet haben, die auf den eigentlichen Täter hinweisen: Durch den Neustart eines Dienstes oder die Neubereitstellung eines Pods werden wertvolle forensische Beweise vernichtet.
Man kann sich vorstellen, wie sich der Chefinspektor die Haare rauft, als ihm klar wird, dass der Regen zur Unzeit die Fingerabdrücke weggespült hat, die ihm die stärkste Spur geliefert hätten.

Quelle: https://www.defendyourcase.com/criminal-defense-blog/2020/february/are-fingerprints-at-the-crime-scene-enough-evide/
Heutzutage kämpfen Entwickler und Betriebsingenieure mit demselben Seiltanz: Sie müssen die Dienste so schnell wie möglich wiederherstellen, ohne dabei wichtige Beweise zu verlieren, die ihnen dabei helfen würden, die Grundursache ihrer Vorfälle auf Codeebene zu ermitteln.
Aber Moment mal – sind Überwachungstools nicht genau dafür da? Die Antwort lautet: manchmal. Je nach Problem lassen sich Konfigurations- oder Codefehler mithilfe ausgefeilter Observability-Tools aufspüren. Entwickler benötigen jedoch oft noch detailliertere Daten, die von Überwachungstools nicht erfasst werden – einfach, weil diese Debug-Daten nicht für Warnmeldungen oder die Wiederherstellung von Diensten benötigt werden. Daten wie Heap-, Thread- und TCP-Dumps, Datenbankabfragen mit dem höchsten Ressourcenverbrauch und Stacktraces werden zwar verwendet, um den „wahren Übeltäter“ zu identifizieren, werden aber meist nicht zur Wiederherstellung des Dienstes benötigt. Das Sammeln dieser Daten ist zeitaufwändig, und wir alle wissen, dass im Falle eines Vorfalls die Wiederherstellung der Dienstverfügbarkeit Vorrang vor allem anderen hat.
Leider hat die Einführung und Verbreitung containerisierter Anwendungen und Container-Orchestrierung dieses Tauziehen aus zwei Hauptgründen nur noch verschärft:
- Microservice-Architekturen bieten schnellere Methoden zur sicheren Wiederherstellung der Verfügbarkeit, beispielsweise durch die erneute Bereitstellung eines Pods.
- In diesen Umgebungen stehen weniger Debugging-Dienstprogramme zur Verfügung, da Entwickler und Betriebsingenieure die Oberfläche ihrer Container-Images minimieren möchten.
Um den gegensätzlichen Kräften in diesem Tauziehen gerecht zu werden, ist eine Lösung erforderlich, die in Sekundenschnelle Maßnahmen ergreifen kann, sodass Beweise erfasst und aufbewahrt werden können – und gleichzeitig der Dienst danach sofort wiederhergestellt werden kann:
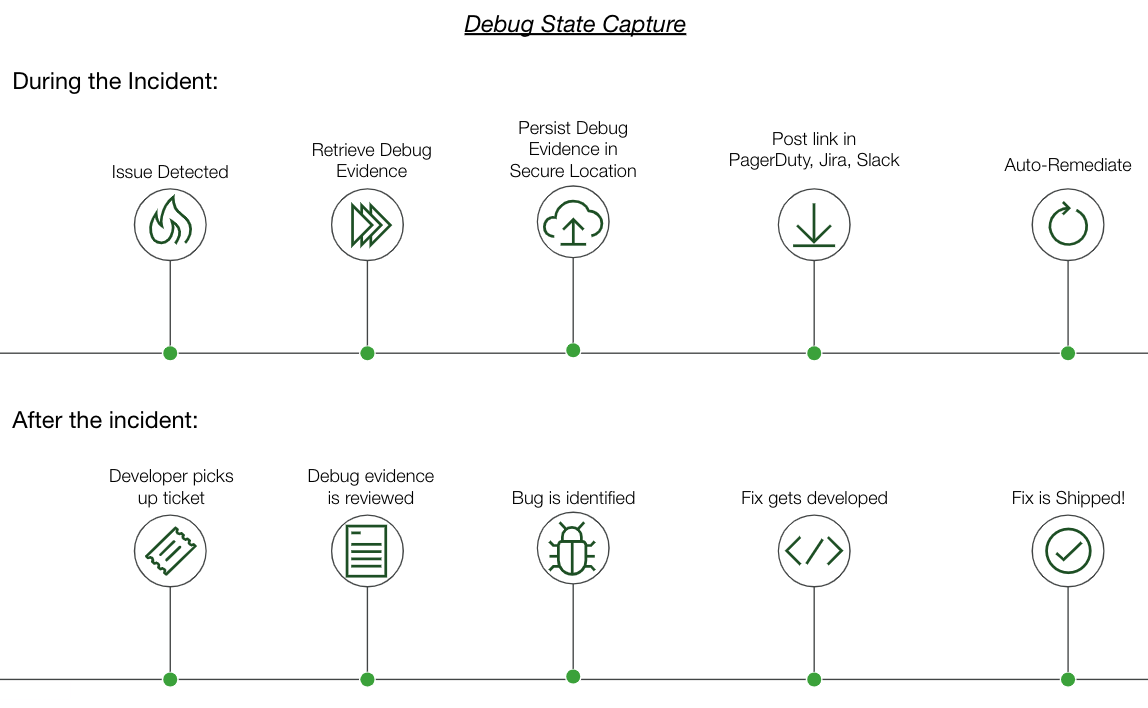
Eine solche Lösung bietet die Operations Cloud von PagerDuty. Durch die Nutzung von Runbooks, die bei erkannten Problemen sofort ausgelöst werden, können Debug-Beweise erfasst und an einen persistenten Speicherdienst wie S3 gesendet werden. Außerdem können Dienste mithilfe bekannter Fixes wiederhergestellt werden. Mit einer umfangreichen Bibliothek vorgefertigter Integrationen für lokale und Cloud-Umgebungen und einer wachsenden Liste von Runbook-Vorlagen können PagerDuty Nutzer dieses scheinbar kühne Ziel erreichen und sowohl die mittlere Reparaturzeit (MTTR) als auch den Zeitaufwand für die Bugreplikation zur Lösung von technischen Schuldentickets reduzieren. Bestehende PagerDuty Kunden können eine Testversion von Runbook Automation anfordern. Hier , während neue Benutzer mit PagerDuty Incident Response beginnen können Hier .
Schauen Sie sich außerdem unbedingt unsere Lösungshandbuch zur automatisierten Diagnose um einige dieser Beispiel-Runbooks anzuzeigen.
Dies ist der erste Teil einer mehrteiligen Blogserie. Im nächsten Blog stellen wir einen Vorlagenjob vor, der Kubernetes-Ephemeralcontainer um Beweise von Anwendungen zu erfassen, die in Kubernetes ausgeführt werden.
Bleiben Sie neugierig, meine Detektivkollegen.

