
- PagerDuty /
- Der Blog /
- Automatisierung /
- Debug State Capture für herkömmliche Infrastrukturen und Apps
Der Blog
Debug State Capture für herkömmliche Infrastrukturen und Apps
von Justyn Roberts
25. Mai 2023 | 5 Minuten Lesezeit
In unseren vorherigen Blogs über Erfassen des Anwendungsstatus und mit Temporäre Container zum Debuggen von Kubernetes haben wir den Wert der Bereitstellung spezifischer Tools zur Erfassung von Diagnosedaten für eine spätere Analyse erörtert und gleichzeitig dem auf den Vorfall reagierenden Personal die Möglichkeit gegeben, Infrastruktur- oder Anwendungsprobleme zu lösen.
Dadurch wird ein Gleichgewicht zwischen der Notwendigkeit geschaffen, einen Dienst so schnell wie möglich wiederherzustellen und gleichzeitig sicherzustellen, dass genügend Debug-Daten für eine spätere dauerhafte Lösung verfügbar sind. Gleichzeitig kann ein Entwicklungsteam dafür sorgen, dass ein Container schlank und leistungsfähig läuft.
Durch die Erfassung des Anwendungs- und Umgebungszustands zum Zeitpunkt des Vorfalls verbringt jeder Helfer oder Dienstbesitzer weniger Zeit mit dem Kontextwechsel zwischen Tools, Anmeldeinformationen und Umgebungen. Dies ermöglicht präzisere und schnellere Reaktionen und Problemlösungen.
Die in den vorherigen Blogs dieser Reihe besprochenen Techniken konzentrierten sich auf moderne, Cloud-native Plattformen wie Kubernetes und die besonderen Ansätze, die für Container erforderlich sind – insbesondere Container, die nicht nativ mit Debugging-Tools ausgeliefert werden.
Nicht jeder ist in der Lage oder bereit, jede Anwendung in die Cloud zu verschieben, und viele von uns arbeiten immer noch in einem Hybridszenario aus containerisierten und herkömmlichen Anwendungen.
Auch ohne die flüchtige Natur von Containern und die strengen Richtlinien für Container-Images besteht immer noch die Notwendigkeit, aktuelle Beweise zu erfassen, um die Ursachenanalyse zu unterstützen und so zukünftige Vorfälle zu vermeiden.
Sehen wir uns Anwendungsfälle an, die die Möglichkeit beschreiben, den Status im Falle eines Fehlers oder einer verringerten Leistung automatisch zu erfassen, und wählen wir einige interessante Szenarios aus, die wir uns genauer ansehen möchten.
Dies ist keine vollständige Liste. Hier sind jedoch einige Beispiele, wie die Debug-Statuserfassung in herkömmlichen Anwendungsumgebungen verwendet wird:
Infrastruktur & Netzwerk
- Prozesse mit dem höchsten Ressourcenverbrauch auf einer oder mehreren Infrastrukturkomponenten
- TCP-Dump; Thread-/Speicher-/Core-Dump
Datenbank
- Abfragen mit dem höchsten Ressourcenverbrauch
- Aktueller Abfragestatus
- Ausführung anwendungsspezifischer Abfragen
Anwendungsspezifisch
- Java – Führen Sie einen Thread-/Heap-Dump mit Tools wie jstack aus
- Windows – Proc Dump
- Python – Thread-Dump ausführen
- Alle – Anwendungsspezifische Protokolldateien
Zusätzliche Protokolldateien
Mit der Debug-Statuserfassung können ganze oder teilweise Protokolle aus beliebigen Dateien abgerufen werden, die möglicherweise nicht von einem Protokollaggregator erfasst werden.
PagerDuty Process Automation bietet viele vorgefertigte Vorlagen-Workflows zur Erfassung des Anwendungs- und Umgebungsstatus als Teil der automatisiertes Diagnoseprojekt . Diese Arbeitsabläufe sind flexibel und erweiterbar, sodass sie an Ihre speziellen Anwendungsfälle angepasst werden können.
Tiefer eintauchen
Sehen wir uns einige konkrete Beispiele für die Erfassung des Umgebungszustands genauer an, die sich bei der Ermittlung der langfristigen Lösung eines Vorfalls als hilfreich erweisen könnten.
Anwendungsfall 1 – Sammeln von Datenbank-Debug
Wir können den SQL RUN-Schritt in der Prozessautomatisierung verwenden, um entweder eine Inline-Anweisung hinzuzufügen oder ein vorhandenes Skript auszuführen. Da meine Anwendung MariaDB ist (ein Fork von MySQL), kann ich die folgenden Parameter verwenden, um die MySQL-Abfrage auszuführen:
VOLLSTÄNDIGE PROZESSLISTE ANZEIGEN;
( Notiz : Anmeldeinformationen werden aus meinem vorhandenen externen Speicher abgeleitet und sicher übergeben, wenn ich den Schritt als Teil eines Workflows ausführe, sodass ich sicher delegieren kann, ohne Informationen preiszugeben)

Ich übergebe die Ausgabe an meine Vorfallplattform (in meinem Fall natürlich PagerDuty) und stelle den Job so ein, dass er automatisch Erfassungen durchführt, wenn innerhalb des Datenbankdienstes ein Vorfall auftritt.

Diese Informationen stehen nun automatisch sowohl meinem Responder in seiner App, seinem Chatops-Tool als auch in jeder Post-Mortem-Analyse zur Verfügung. In diesem Fall kann ich sehen, dass jemand zum Zeitpunkt des Vorfalls einen Benchmark-Test durchführt! Wie bei den vorherigen Blogbeiträgen wäre es auch einfach, komplexere Versionen davon zur späteren Analyse in einer Speicherumgebung wie einem AWS S3-Bucket zu veröffentlichen.
Anwendungsfall 2 – Sammeln von Anwendungsdebug
Mein Beobachtungstool teilt mir sehr schnell mit, WANN eine Anwendung fehlgeschlagen ist, aber nicht immer die Information, WARUM sie fehlgeschlagen ist. In diesem zweiten Anwendungsfall wird ein Ad-hoc-Befehl für meine Python-Anwendung ausgeführt, um py-spy, einen Sampling-Profiler für meine Anwendung, in Verbindung mit einem unserer Automatisierungs-Plugins zu verwenden, um Dateien sicher nach S3 zu verschieben und später abzurufen.
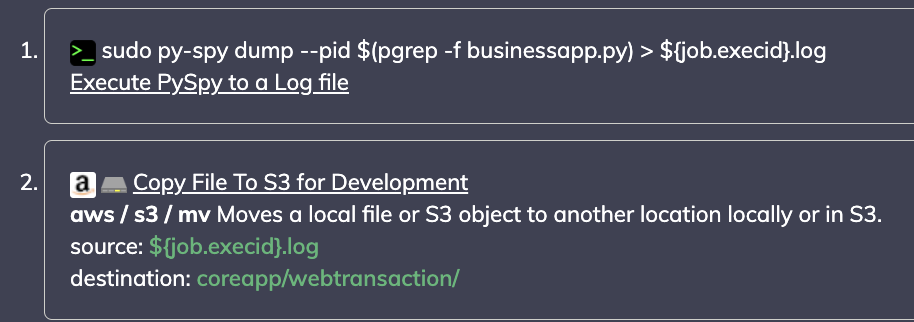
Gibt Daten direkt an meinen S3-Speicher aus:

Dieses Beispiel hebt die Worker-Zustände meiner Python-App auf Thread-Ebene hervor, gibt sie direkt an meine Entwickler weiter und speichert sie so lange, wie sie zum Referenzieren benötigt werden.
Natürlich sind diese Befehle nicht exklusiv und ich könnte problemlos mehrere Prüfungen verketten, um eine umfassendere Ansicht zu erhalten.
Anwendungsfall 3 – Erfassung des Debugstatus einer herkömmlichen Infrastruktur
Für den dritten Anwendungsfall muss ich eine Reihe von Bash-Befehlen auf einem Remote-Computer bereitstellen und beim Auslöseereignis erneut ausführen. Dies führt in erster Linie zu Diagnosen wie offenen Dateien und Netzwerkverbindungen, führt aber auch Abonnieren , ein Tool, mit dem sich bestimmte Anrufe zurückverfolgen lassen:
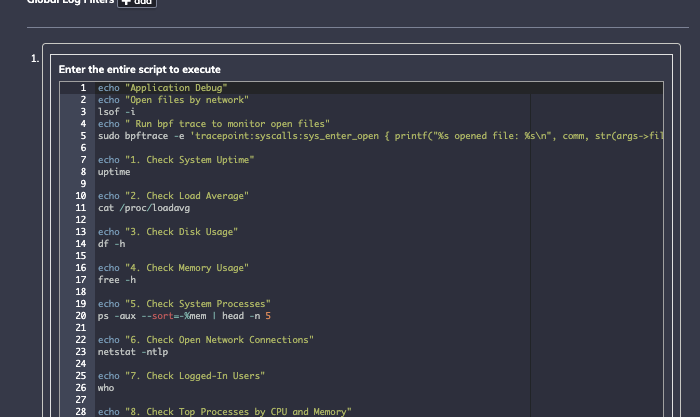
Mithilfe der Prozessautomatisierung kann ich ein ganzes Skript definieren und bereitstellen und die Ausgabe speichern, um einen Snapshot des Zustands meiner Umgebung zu erfassen:
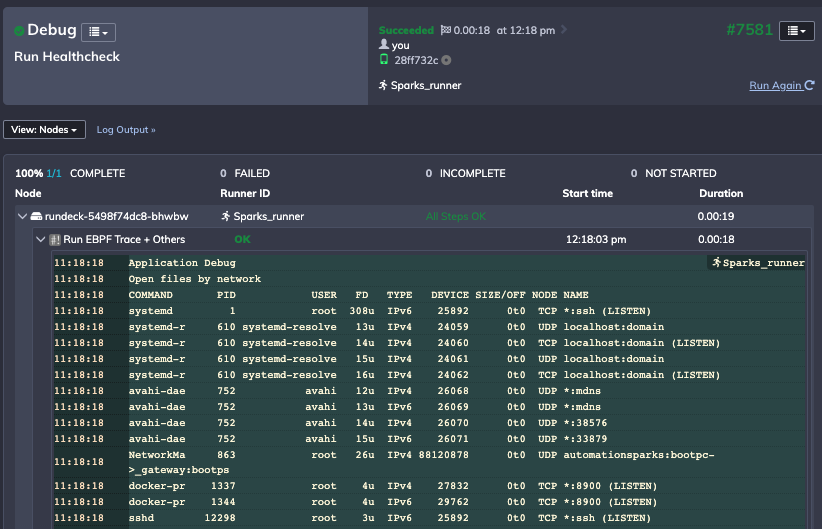
Abschluss
Signale von Überwachungstools profitieren selbst in herkömmlichen Umgebungen von einer breiteren Sichtbarkeit, sodass jeder Responder, DevOps-Ingenieur oder SRE schnelle und sichere Entscheidungen treffen kann. Entwickler benötigen außerdem häufig zusätzliche Informationen und die Möglichkeit, den Status bei auftretenden Problemen zu erfassen, da diese möglicherweise nicht sofort verfügbar sind.
Dies wird durch Debug State Capture ermöglicht, das einem Antwortenden zusätzlichen Kontext bietet, den Zeitaufwand für die Suche in verschiedenen Tools reduziert und die Möglichkeit bietet, tiefere Datensätze für die nachfolgende Analyse zu sammeln.
Möchten Sie mehr erfahren? Beginnen Sie noch heute mit einer Testversion von Runbook-Automatisierung .

