- PagerDuty /
- Der Blog /
- Best Practices und Einblicke /
- So vermeiden Sie den „Swoop and Poop“-Effekt der Geschäftsführung und andere bewährte Methoden für betriebliche Reife
Der Blog
So vermeiden Sie den „Swoop and Poop“-Effekt der Geschäftsführung und andere bewährte Methoden für betriebliche Reife
von Hannah Culver
11. August 2021 | 7 min Lesezeit
Wir gehen wieder in Restaurants essen. Wir treffen unsere Familie nach zu langer Zeit wieder. Manche von uns kehren vielleicht sogar ins Büro zurück. Das heißt aber nicht, dass der Druck auf digitale Dienste nachlässt. Die Steigerung der operativen Reife bleibt weiterhin unser Hauptanliegen.
Während die digitalen Transformationen bereits seit zwei Jahrzehnten stattfinden, hat COVID-19 den Druck erhöht, Initiativen zu beschleunigen. In dieser Zeit kam es in den Teams zu mehr Zwischenfällen, und da die Grenzen zwischen Arbeit und Privatleben immer mehr verschwimmen, begannen viele Menschen, Überstunden zu machen, um Feuerwehreinsätze zu leisten.
Tatsächlich eine Umfrage von über 700 Entwicklern und IT-Betriebsfachleuten, 58 % der Befragten geben an, dass die Zahl der Vorfälle innerhalb von 3 bis 6 Monaten um mehr als 40 % zugenommen hat — mit einer durchschnittlichen Steigerung von 47 % — und setzen ihre Teams erheblich unter Druck.
Wenn man mit Kunden darüber spricht, wie sie sich an dieses Umfeld angepasst haben, erkennt man einen klaren Unterschied zwischen Kohorten von Organisationen und Teams in ihrer operativen Reife. Kurz gesagt: Je reifer eine Organisation war, desto einfacher passte sie sich an das veränderte Tempo und die gestiegenen Anforderungen an. Aber bevor wir darauf eingehen, machen wir einen Schritt zurück. Was genau ist operative Reife?
Betriebsreife ist ein Maß für die allgemeine Konsistenz, Zuverlässigkeit und Belastbarkeit der IT-Infrastruktur, einschließlich der Art und Weise, wie sie verwaltet und gewartet wird . Dies umfasst, wie Teams mit Vorfällen umgehen. Die betriebliche Reife wirkt sich auf die Gesundheit und Zufriedenheit der Teams aus, die diese Infrastruktur unterstützen, sowie auf den Endbenutzer, was sie zu einer zunehmend wichtigen Investition macht.
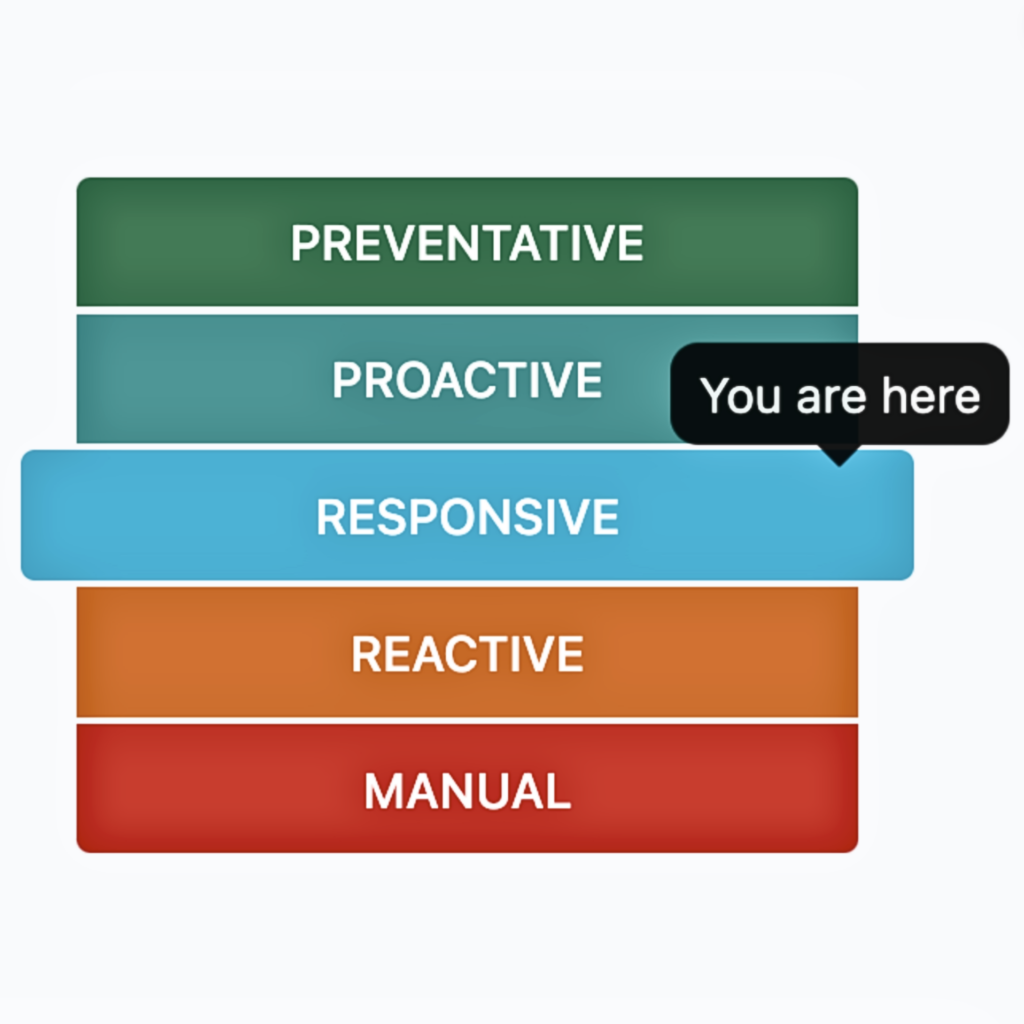
Wir haben festgestellt, dass fast alle Organisationen in fünf Kategorien der operativen Reife fallen: manuell, reaktiv, reaktionsfähig, proaktiv und präventiv . Um die nächste Stufe der betrieblichen Reife zu erreichen, sind Prozess-, Werkzeug- und Kulturänderungen erforderlich. Wir haben ein Webinar erstellt, das Teams dabei hilft, zu verstehen, wo sie jetzt stehen und wie sie sich verbessern können.
Um Ihnen einen Vorgeschmack auf die Themen zu geben, die wir behandeln, sind hier drei Best Practices, die Sie von unseren Referenten lernen werden:
Machen Sie die Reaktion auf Vorfälle zu einer geschäftlichen Reaktion
Denken Sie an eine Feuerwehrmannschaft. Bei der Reaktion auf einen Großbrand gibt es einen Chef, der die Abläufe delegiert (der selbst aber nichts zur Brandbekämpfung beiträgt), einen Navigator und Kommunikator sowie mehrere Feuerwehrleute, die aktiv das Feuer löschen. Die Reaktion auf einen Vorfall funktioniert ähnlich. Operativ ausgereifte Teams haben für größere Vorfälle bestimmte Rollen. Sie haben einen Kommandanten, der die Einsätze organisiert, einen Kommunikationsleiter, der neue Entwicklungen mitteilt, sowie mehrere Fachexperten, die den Vorfall lösen.
Aber Reaktion auf Geschäftsvorfälle geht über die bloße Einbindung der Serviceinhaber und direkten Ansprechpartner hinaus. Die erfahrensten Teams stellen außerdem sicher, dass andere Geschäftsinteressenten während des gesamten Prozesses auf dem Laufenden gehalten werden. Diese Aufgabe übernimmt häufig der Kommunikationsleiter.
Bei schwerwiegenden Vorfällen muss mehr als nur ein Team über das Problem informiert sein. Der Kundensupport muss beispielsweise wissen, dass er mit einem höheren Anruf- und Ticketaufkommen rechnen muss. Der Vertrieb muss möglicherweise Demos oder Anrufe verschieben. Das Marketing muss möglicherweise wissen, dass es einen bestimmten Social-Media-Beitrag zurückhalten oder mit überdurchschnittlicher Medienaufmerksamkeit rechnen muss. Führungskräfte möchten wissen, welche Auswirkungen nicht nur das beteiligte technische Team, sondern alle diese Teams gemeinsam auf das Geschäft haben.
Durch die Kommunikation mit den Beteiligten, die Aktualisierung über neue Entwicklungen und die Zusammenarbeit ohne Silos werden Vorfälle schneller gelöst und haben geringere Auswirkungen auf Kunden und Marke. Darüber hinaus hilft dies, das „Swoop and Poop“ zu vermeiden, ein Begriff für den Fall, dass andere Geschäftsbereichsbeteiligte die Vorfallreaktionsbemühungen unterbrechen, um zu verstehen, wie sich dies auf ihre Teams auswirken wird. Indem sie ihre Bedenken proaktiv ansprechen, bevor sie fragen, können die Helfer Zeit und Energie sparen.
Aus Fehlern lernen und Änderungen vornehmen
Vorfälle passieren. Sie lassen sich nicht vermeiden. Aber Sie können aus ihnen lernen und in manchen Fällen sogar verhindern, dass sich Vorfälle der gleichen Art oder Art erneut wiederholen. Dies hängt davon ab, wie gut Ihr Team aus Fehlern lernt, und ist ein weiteres Kennzeichen betrieblicher Reife.
Obduktionen sind eine wichtige Methode, um aus Systemfehlern zu lernen. Nachdem ein Vorfall behoben wurde, machen sich betrieblich erfahrene Teams an die Arbeit, um herauszufinden, warum es dazu kam und wie man ein erneutes Auftreten verhindern kann. Dieser Prozess umfasst in der Regel die Erstellung einer umfassenden Dokumentation des Vorfalls, einschließlich Zeitplänen, Skripts oder Runbooks, die im Lösungsprozess verwendet wurden, und relevanter Telemetriedaten.
Nachdem die Dokumentation abgeschlossen ist, trifft sich das Reaktionsteam (virtuell oder persönlich) und bespricht die Ereignisse, mögliche Ursachen, wie der Prozess funktioniert hat und was getan werden kann, um das System widerstandsfähiger gegen diese Art von Fehlern zu machen. In diesem Prozess ist es wichtig, Fehler ohne Schuldzuweisungen anzugehen, um die psychologische Sicherheit zu wahren und den größtmöglichen Nutzen aus diesem Prozess zu ziehen.
Nach Abschluss der Postmortem-Analyse haben die Teams oft eine Liste mit Aktionspunkten, die das System vor einem ähnlichen Fehler schützen könnten. Es reicht nicht aus, diese Aktionspunkte zu erstellen und sie unzugeordnet in einer Warteschlange zu belassen. Zur operativen Reife gehört auch, Maßnahmen zu ergreifen, um positive Änderungen vorzunehmen.
Nicht alle Aktionspunkte sind gleich. Manche sind wertvoller als andere. Wenn Sie überlegen, welche Aktionspunkte Sie priorisieren, betrachten Sie sie aus der Perspektive ihrer Auswirkungen auf das gesamte Unternehmen. Wenn zwei Aktionspunkte gleich viel Zeit in Anspruch nehmen, einer jedoch nur den Servicebesitzern und der andere einem größeren Teil des Unternehmens zugute kommt, priorisieren Sie den, der mehr Leuten hilft.
Burnout sowohl qualitativ als auch quantitativ messen
Vorfälle sind unvorhersehbar. Deshalb gelten sie als ungeplante Arbeit. Wenn wir alle unsere Zeitpläne um vorhersehbare Ausfälle herum planen könnten, wäre das Leben viel einfacher. So funktioniert es jedoch nicht und Unterbrechungen sind unvermeidlich. Wenn diese Unterbrechungen sehr häufig sind oder außerhalb der Arbeitszeiten wie nachts, an Wochenenden und Feiertagen stattfinden, könnten sich die Mitglieder des Bereitschaftsteams ausgebrannt fühlen.
Ein kürzlich Bericht von PagerDuty zeigte, dass der durchschnittliche PagerDuty Benutzer bis 2020 2 Stunden mehr pro Tag arbeitete als 2019. Das entspricht 12 zusätzlichen Arbeitswochen pro Jahr. Darüber hinaus stellte der Bericht fest, dass Benutzer, die mehr Unterbrechungen außerhalb der Arbeitszeit erlebten, diejenigen waren, die ihre PagerDuty -Konten am häufigsten löschten (unser Indikator für Fluktuation). Unternehmen müssen Burnout frühzeitig erkennen, bevor es zu einer schlechteren Teammoral und Fluktuation führt.
Wie können Organisationen dies erreichen? Quantitativ gesehen sollten Manager die Dauer der Bereitschaftsdienste, die durchschnittliche Anzahl und Dauer von Vorfällen pro Bereitschaftszeitraum sowie die Häufigkeit, mit der ihre Teams außerhalb der Arbeitszeit aus ihrem Alltag geholt werden müssen, um zu reagieren, berücksichtigen.
Doch die Geschichte des Burnouts lässt sich nicht nur in Zahlen erzählen. Es ist genauso wichtig, ein qualitatives Gefühl dafür zu bekommen, wie es den Teams geht. Manager sollten zum Beispiel auf Gespräche über lange Nächte oder Teammitglieder achten, die sich überarbeitet fühlen. Sie sollten auch auf etwaige Qualitätseinbußen bei der Arbeit oder verpasste Termine achten, die Anzeichen für Burnout sein können. Und nicht zuletzt müssen Manager die Teammoral im Auge behalten und sicherstellen, dass, obwohl viele von uns noch immer remote arbeiten, eine Politik der offenen Tür für alle Anliegen herrscht.
Wenn sich Teams darauf konzentrieren können, Burnout vorzubeugen, Vorfälle als Unternehmen und nicht nur als Team zu lösen und aus Fehlern zu lernen, sind sie auf dem besten Weg zur operativen Reife. Aber das ist nicht alles, was diese Transformation erfordert.
Unser Webinar „ Detaillierte Informationen zur betrieblichen Gesundheit ”, beschreibt, wie Sie die Weiterentwicklung Ihrer Organisation planen können. Begleiten Sie Mandi Walls, DevOps Advocate, und Logan Life, Senior Principal Customer Success Manager von PagerDuty, während sie Taktiken durchgehen, wie Sie die operative Reife steigern und DevOps-Best Practices wie Full-Service-Eigentum und eine Kultur der Schuldlosigkeit zu pflegen.
Registrieren um das On-Demand-Webinar anzusehen.