
- PagerDuty /
- Der Blog /
- Integrationen /
- Überwachung sozialer Signale zur Reduzierung der Alarmmüdigkeit mit SignalFx und PagerDuty
Der Blog
Überwachung sozialer Signale zur Reduzierung der Alarmmüdigkeit mit SignalFx und PagerDuty
von Arijit Mukherji
19. September 2018 | 6 min Lesezeit
„Ich muss benachrichtigt werden, wenn bei SignalFx ein wichtiges Ereignis stattfindet.“ Das sage ich meinem Team. Obwohl ich CTO eines Überwachungsunternehmens bin, war es für mich schwieriger, die richtigen Warnmeldungen zu erstellen, um über laufende Vorfälle oder potenzielle Probleme informiert zu bleiben, als es auf den ersten Blick schien.
Warum?
Während das Aufkommen von Cloud- und Open-Source-Technologien es uns ermöglicht hat, Software viel schneller zu entwickeln, sind die heutigen Umgebungen deutlich komplexer zu Monitor und verwalten Sie aus einer Reihe von Gründen, darunter:
- Die explosionsartige Zunahme der Anzahl zu überwachender Compute-Instanzen (Hosts, Container, Funktionen).
- Dienste geben selten „gut funktionierende“ Messwerte aus und ändern sich im Laufe der Zeit ständig.
- Aufgrund der Microservices-Architektur steigt die Anzahl der Dienste, die einzeln überwacht werden müssen.
Das Ergebnis für viele von uns ist eine Flut von Fehlalarmen oder redundanten Alarmen. Alarmmüdigkeit behindert nicht nur die Fähigkeit Ihres Teams, Probleme in Echtzeit zu finden und zu beheben – wenn sie lange genug unbeachtet bleibt, zerstört sie auch die Teammoral und führt zu vermeidbaren Ausfällen.
Strategien zur Reduzierung von Alarmmüdigkeit
Reduzierung der Alarmmüdigkeit beginnt mit der Erweiterung des eigenen Fokus. Während die detaillierte Messung von Metriken bei der Fehlerbehebung und forensischen Analyse äußerst nützlich ist, basieren die aussagekräftigsten Warnungen auf einer Kombination von Signalen, die übergeordnete Indikatoren für die Anwendungsintegrität erstellen. Insbesondere sollten Sie Folgendes berücksichtigen:
Überwachung von Populationen, nicht von Einzelfällen
Definieren und abonnieren Sie Integritätsindikatoren pro Dienst oder pro Population, anstatt Warnmeldungen zum Status jeder einzelnen Komponente in Ihrer Umgebung zu erhalten. Sie können beispielsweise die Latenz des 99. Perzentils eines API-Aufrufs über alle Dienstinstanzen hinweg, die durchschnittliche CPU-Auslastung für einen bestimmten Knotencluster oder die Summe der API-Fehler für eine Gruppe von Containern, die diesen Cluster bedienen, verfolgen.
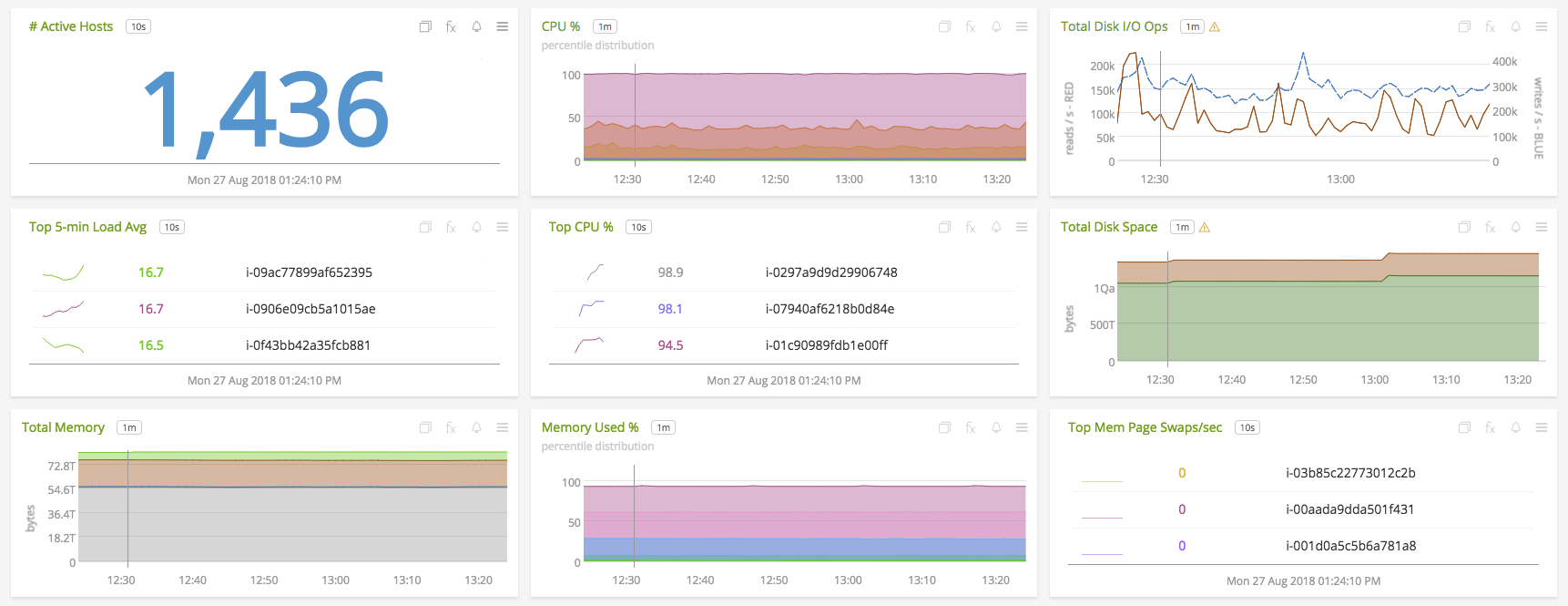
Aggregierte Systemmetriken für 1.436 Hosts
Warnmeldungen basierend auf Mustern und Trends statt auf festen numerischen Schwellenwerten
Verwenden Sie algorithmisch generierte Schwellenwerte, die sich an veränderte Umgebungen anpassen können. Verteilte Systeme verhalten sich oft auf mysteriöse Weise, was es äußerst schwierig macht, die „richtige“ Menge an CPU-Auslastung oder API-Fehlern zu bestimmen, die auftreten, bevor eine Warnung ausgelöst wird.
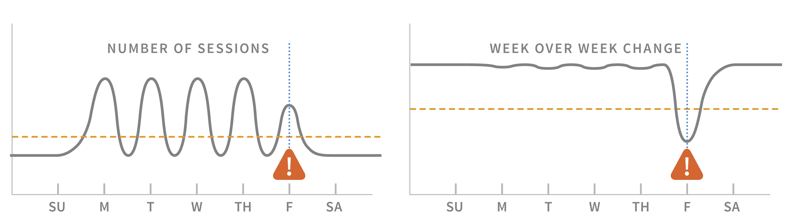
Warnmeldungen bezüglich der Rohanzahl der Sitzungen im Vergleich zur wöchentlichen Veränderung
Durch die Berücksichtigung regelmäßiger Muster (z. B. höherer Datenverkehr an Wochentagen) oder durch prädiktive Warnungen (Warnung, wenn ein Cluster in den nächsten N Tagen nicht genügend Speicherplatz hat) können Sie noch besser zwischen dem regulären Systemverhalten und etwas unterscheiden, das eine Reaktion rechtfertigt.
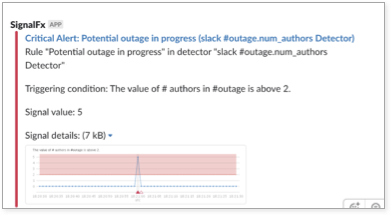
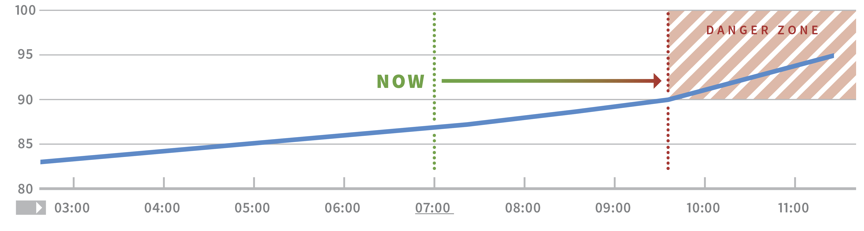
Diagramm mit einer Metrik zur Kapazitätsentwicklung
Definieren allgemeiner Kennzahlen zur Anwendungsleistung
Kombinieren Sie Metriken aus verschiedenen Microservices, um Signale und Warnungen auf höherer Ebene abzuleiten. Zwei Möglichkeiten sind die Anzahl der Seitenaufrufe pro angemeldetem Benutzer oder die Anzahl der API-Fehler, gemessen als Prozentsatz der gesamten API-Aufrufe. Einer unserer Kunden kombiniert Metriken aus all seinen Microservices, um einen „Health Score“ für Bereitstellungsversionen zu erstellen, der angibt, ob sich die Anwendungsleistung insgesamt verbessert hat.
Messung sozialer Signale
Obwohl wir bei SignalFx alle diese Techniken verwenden, gab es immer noch zu viele Fehlalarme. Beachten Sie Folgendes:
- Als technischer Leiter benötige ich keine so detaillierten Warnmeldungen wie ein Serviceinhaber oder ein Bereitschaftstechniker. Es ist auch unpraktisch, nur eine Teilmenge der Warnmeldungen zu verfolgen, da diese Abonnentenliste ohne ständige Wachsamkeit schnell veraltet.
- Obwohl unsere Organisation PagerDuty verwendet, bin ich nicht immer auf dem Bereitschafts-Eskalationspfad .
- Zwar könnte ich kleinere Probleme herausfiltern, indem ich Quellen wie die SignalFx-Statusseite anschaue, doch würde dies die Warnmeldungen zu spät erhalten (erst wenn ein Site-Problem bereits in vollem Gange ist, und nicht vorher), als dass ich aktiv zur Reaktion auf den Vorfall beitragen könnte.
Welche anderen Signale könnte ich messen? Bei SignalFx haben wir einen Slack-Kanal namens #outage, der speziell für die Diskussion von Vorfällen gedacht ist. Dieser Kanal empfängt auch kritische Warnmeldungen von PagerDuty , um den Kontext für diese Diskussionen beizubehalten. Da ich wusste, dass schwerwiegende Probleme oft dazu führen, dass mehrere Benutzer in Slack zusammenarbeiten und die Situation über PagerDuty eskaliert, habe ich beschlossen, in #outage Metriken zur menschlichen Aktivität zu sammeln. Das Ergebnis sah ungefähr so aus:
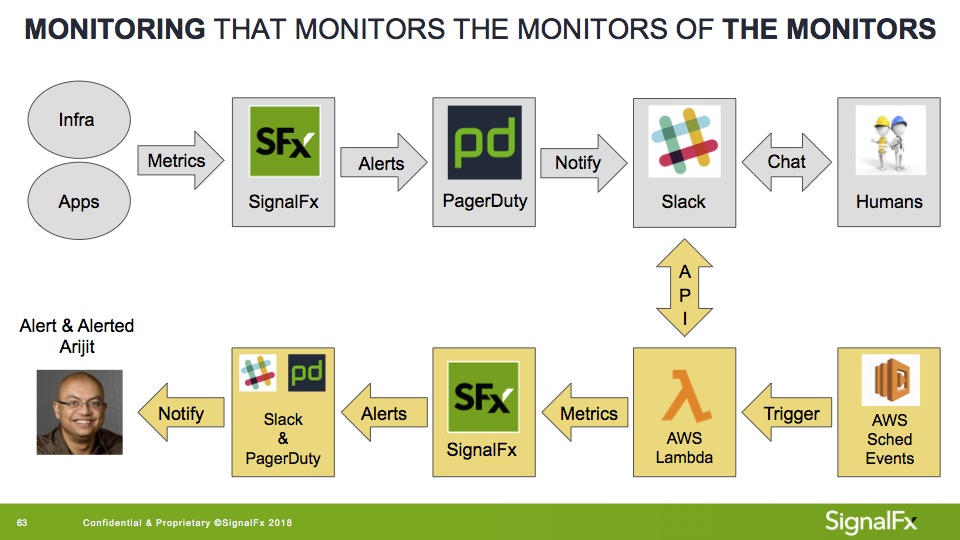
Grau: „Normaler“ SignalFx-Alarmierungsworkflow
Gelb: Alarmierung mit sozialen Signalen
Ich benutzte ein AWS Lambda eingestellt, um Nachrichten abzufragen und zu klassifizieren (z. B. von Menschen oder Bots generiert) und sie dann auf SignalFx zu veröffentlichen. Als Nächstes habe ich einen Warnmelder erstellt, der mich benachrichtigt, wenn mehr als drei verschiedene menschliche Autoren für einen Zeitraum von fünf Minuten oder länger #outage eintippten. Warnmeldungen wurden über PagerDuty an mein Telefon gesendet und eine Direktnachricht in Locker .
Benachrichtigung über möglichen Ausfall im Gange
Das funktionierte überraschend gut – obwohl ich noch immer ein paar Fehlalarme erhielt, sank die Zahl auf fast Null und ich wurde über jeden einzelnen Vorfall, der mich interessierte, benachrichtigt. Interessanterweise wurde ich auch über einige potenzielle Vorfälle informiert, für die ich keine aktiven Alarme eingerichtet hatte, die unsere Techniker jedoch im Rahmen ihrer allgemeinen Beobachtung des Dienstes entdeckt hatten.
Hören Sie nicht bei der Überwachung von Hardware und Software auf
Ich war zunächst enttäuscht, dass ich nicht in der Lage war, die „perfekte“ Warnmeldung nur anhand von Anwendungs- und Infrastrukturmetriken zu erstellen, aber das war vielleicht eine naive Erwartung. Um die richtige Warnmeldung zu erstellen, müssen Sie nicht nur Ihre Umgebung verstehen, sondern auch, wie Ihre Organisation auf Vorfälle reagiert.
Für meinen speziellen Anwendungsfall reichte die Messung des menschlichen Verhaltens aus, doch angesichts der Interoperabilität und Datenagnostik vieler heutiger Tools gibt es eine Fülle weiterer Signale, die wir möglicherweise in unser Monitoring integrieren könnten.
Integrieren Sie die Problemerkennung in das Vorfallmanagement
Echtzeitgeschäfte erfordern betriebliche Intelligenz in Echtzeit, und die heutigen Technologien erzeugen weitaus mehr Daten, als herkömmliche Überwachungstools verarbeiten können. SignalFx sammelt Streaming-Metriken von jeder Komponente in Ihrer Umgebung, um Analysen und Warnungen in Sekundenschnelle bereitzustellen. So können Sie Probleme finden und beheben, bevor sie sich auf Kunden auswirken.
Mit SignalFx Und PagerDuty , Sie können Vorfälle automatisch in PagerDuty öffnen, wenn ein Alarmdetektor in SignalFx ausgelöst wird, je nach Alarm unterschiedliche Eskalationsrichtlinien zuordnen und Vorfälle automatisch als gelöst markieren, wenn sich die Lage wieder normalisiert.
Bei SignalFx helfen wir Organisationen dabei, alle wichtigen Signale zu überwachen – in Echtzeit und in jedem Umfang – und geben ihnen die Sicherheit, schneller als je zuvor Innovationen hervorzubringen.
Arijit Mukherji ist CTO bei SignalFx und begeistert sich für Monitoring. Er war einer der ursprünglichen Entwickler der Metriklösung (ODS) von Facebook und leitete anschließend die Entwicklung der Netzwerktools, der Datenvisualisierung und anderer Infrastrukturüberwachungssoftware von Facebook. Während er sich seit mehr als einem Jahrzehnt auf den Überwachungsbereich konzentriert, umfasst seine über 20-jährige Karriere auch IP-Telefonie, VoIP-Konferenzen und Netzwerkvirtualisierung.
Das könnte Ihnen auch gefallen ...

