
- PagerDuty /
- Der Blog /
- Automatisierung /
- Minimieren der Abweichung von Data-Science-Modellen durch Nutzung von PagerDuty
Der Blog
Minimieren der Abweichung von Data-Science-Modellen durch Nutzung von PagerDuty
von PagerDuty
15. August 2022 | 7 min Lesezeit
Von Thomas Pin – Data Scientist
PagerDuty verfügt über ein Frühwarnsystem (EWS), das den Abteilungen Customer Success und Sales hilft, das Wohlbefinden bestehender PagerDuty Kunden anhand der Produktnutzung und externer Geschäftsfaktoren zu ermitteln. Dieses Frühwarnsystem ist zu einer kritischen Infrastruktur und zur ersten Verteidigungslinie bei der Erkennung einer schlechten Produktnutzung geworden, die zu einer Kundenabwanderung führen könnte. Der Erfolg des Frühwarnsystems und die großen Anstrengungen der Abteilung Customer Success haben unsere riskante Produktnutzung verringert. Bei einem so kritischen Modell in der Produktion ist es von größter Bedeutung, dass es immer genaue Ergebnisse liefert und regelmäßig aktualisiert wird.
Im Januar 2021 veröffentlichte das Modell des Frühwarnsystems aufgrund einer vorgelagerten Änderung einen ungenauen Kundenrisiko-Score, was dazu führte, dass ein fehlerhafter Score einige Tage lang online war. Erst als uns einer der Customer Success Manager wegen der Verwechslung kontaktierte, konnten wir das Modell sofort diagnostizieren und reparieren. Das Data Platform and Business Intelligence-Team, intern als DataDuty bekannt, war entschlossen, nach einer Lösung zu suchen, um ähnliche Pannen in Zukunft zu vermeiden.
Das oben aufgeführte Problem betrifft nicht nur PagerDuty. In der Data Science-Community wäre dies ein Beispiel für Modelldrift und es treten mehr Formen auf als nur Upstream-Datenänderungen. Das DataDuty-Team war entschlossen, die Auswirkungen dieses Phänomens durch automatisierte Tests zu minimieren und PagerDuty Warnmeldungen wenn diese Probleme auftreten.
PagerDuty
Das Produkt von PagerDuty ist das entscheidende Puzzleteil, um proaktiv Modelldrift zu vermeiden. Da Machine-Learning-Modelle mehrere Plattformen nutzen, ist es ohne spezielle Software zur Vorfallstriage wie PagerDuty unmöglich, die Protokolle mehrerer Plattformen zu erfassen, Vorfälle zu erstellen, nach Priorität zu eskalieren und Praktiker zu alarmieren. Unabhängig davon, wie robust unsere automatisierten Tests sind, wird es keinen Unterschied machen, wenn wir die Ergebnisse nicht zur richtigen Zeit an die richtige Person übermitteln können. PagerDuty hat den Erfolg unserer Strategie ermöglicht und wir konnten nachteilige Änderungen erkennen, bevor ein Modellpraktiker sie bemerkt hat.
Modelldrift
Modelldrift kann in drei Kategorien unterteilt werden: Konzept, Daten und Upstream, wobei jede Kategorie einen anderen Lösungsansatz erfordert.
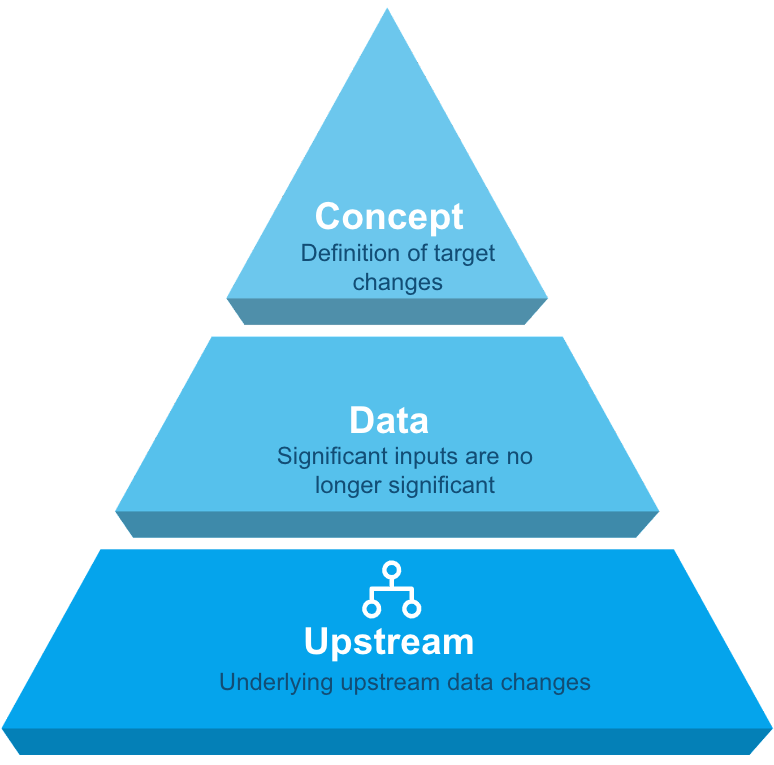 Konzept : Definition des Ziels der Modelländerungen
Konzept : Definition des Ziels der Modelländerungen
Daten : Signifikante Inputs verlieren an Bedeutung
Stromaufwärts : Änderungen der zugrunde liegenden Upstream-Daten
Konzept-Drifttests
Es ist schwierig, einen Test zu schreiben, um Konzeptänderungen zu erkennen, da es sich dabei um ein Konstrukt handelt, das von den Datenwissenschaftlern und Stakeholdern entwickelt wurde. Im Fall des Frühwarnsystemmodells ist das Ziel jedoch „Churn“, was eine einfache Definition hat. Bei PagerDuty wird „Churn“ als ein Konto definiert, das entweder aktiviert oder deaktiviert wird, und diese Definition ist stabil geblieben.
Um zu messen, ob das Frühwarnsystemmodell den Kundenrisikowert richtig vorhersagt, führen wir einige Unit-Tests durch:
- Vor dem Early Warning System hatte PagerDuty eine monatliche Abwanderungsrate zwischen x % und y %. Wenn die monatliche Abwanderungsrate also über z % liegt, wird dies als Problem angesehen.
- Die Gesamtwerte der Early Warning System Scores haben sich in den letzten Jahren stabilisiert, wobei die Werte einzelner Konten mit der Zeit steigen oder fallen können. PagerDuty geht jedoch davon aus, dass 25*% der Konten einen niedrigen Kundenrisikowert, 25*% einen mittleren bis niedrigen Kundenrisikowert, 25*% einen mittleren Kundenrisikowert und 25*% einen hohen Kundenrisikowert aufweisen. * Keine tatsächlichen Zahlen
- Der monatliche Durchschnittswert des Frühwarnsystems liegt historisch innerhalb einer Toleranz von 2,5 % des mittleren Frühwarnsystemwerts.
Sollte einer dieser Tests fehlschlagen, würde dies als hohe Priorität eingestuft und PagerDuty würde eine Warnung an einen der diensthabenden Datenwissenschaftler von DataDuty senden, um zu untersuchen, ob die Definition des Modells für „Churn“ zutreffend war und ob eine Aktualisierung erforderlich ist.
Datendrifttests
Im Laufe der Zeit können Modellmerkmale für die Bewertung des Frühwarnsystemmodells relevanter oder weniger relevant werden, und PagerDuty hat Tests entwickelt, um diese Risiken zu mindern. Im letzten Jahr war beispielsweise eine der wichtigsten Kennzahlen der Prozentsatz der Vorfälle, die „bestätigt“ wurden ( Vorfallbestätigungsrate ). Dies war ein relevantes Merkmal zur Vorhersage der Abwanderungswahrscheinlichkeit eines Kontos. Kürzlich wurde jedoch festgestellt, dass die Bestätigungsrate von Vorfällen mit hoher Dringlichkeit war relevanter und ersetzte den ursprünglichen Vorfall Bestätigungsrate . PagerDuty führt die folgenden Tests durch, um die Relevanz eines Features in unserem Feature Store zu bestimmen:
- Cohens d schätzt die Effektgröße zwischen zwei Mittelwerten. Die Modell-Engine des Frühwarnsystems basiert auf Merkmalen, die einen signifikanten Abstand zwischen den Mittelwerten der Kundenverteilung und der Verteilung der abgewanderten Kunden aufweisen.
- Kurtosis misst die „Endigkeit“ zwischen zwei Verteilungen. Die Enden der Verteilungen von Kunden und abgewanderten Kunden sollten eine signifikante Lücke aufweisen.
- Kolmogorov-Smirnov-Test ist ein nichtparametrischer Test auf die Gleichheit kontinuierlicher, eindimensionaler Wahrscheinlichkeitsverteilungen, der zum Vergleichen einer Stichprobe mit einer Referenzwahrscheinlichkeitsverteilung oder zum Vergleichen zweier Stichproben verwendet werden kann. Das Modell „Early Warning System“ vergleicht die beiden Verteilungen für Kunden und abgewanderte Kunden.
- T-Test ist eine Inferenzstatistik, die verwendet wird, um zu bestimmen, ob es einen signifikanten Unterschied zwischen den Mittelwerten zweier Gruppen gibt und wie sie zusammenhängen. Wenn alles andere fehlschlägt, berechnen Sie die Signifikanz für Merkmale.
Die Funktionen sollten innerhalb der zugewiesenen Grenzwerte bleiben, andernfalls erstellt PagerDuty einen Vorfall und weist ihn einem der diensthabenden Datenwissenschaftler von DataDuty zu, um die Diskrepanz zu untersuchen. Darüber hinaus werden diese Kennzahlen vierteljährlich untersucht, um zu prüfen, ob dem Frühwarnsystemmodell eine neue Funktion hinzugefügt werden sollte.
Upstream-Datendrift
Dem Frühwarnsystemmodell vorgelagert sind die aggregierten Datentabellen, in denen relevante Metriken für eine mögliche Verwendung gespeichert sind. Derzeit gibt es neun Hauptaggregattabellen, die überwacht werden müssen, sowie über fünfzig Basistabellen, aus denen die Aggregattabellen schöpfen. Um die Datenintegrität und Verfügbarkeit aufrechtzuerhalten, umfasst der PagerDuty -Tech-Stack: Snowflake zur Speicherung der Daten, Monte Carlo zur Aufrechterhaltung der Datenintegrität, Apache Airflow zur Planung von Jobs, Databricks zum Erstellen und Durchführen von Experimenten mit dem Modell und PagerDuty zur Durchführung einer Vorfallstriage, falls Probleme auftreten. Wenn sich beispielsweise eine „falsche Datenladung“ auf das Frühwarnsystemmodell auswirkt, erstellt PagerDuty einen Vorfall und benachrichtigt den diensthabenden Dateningenieur von DataDuty.
PagerDuty und Modelldrift – Beispiel
Das Folgende ist ein echtes Beispiel für einen PagerDuty Alarm, den ein Mitglied des DataDuty-Teams während der Bereitschaft erhielt.
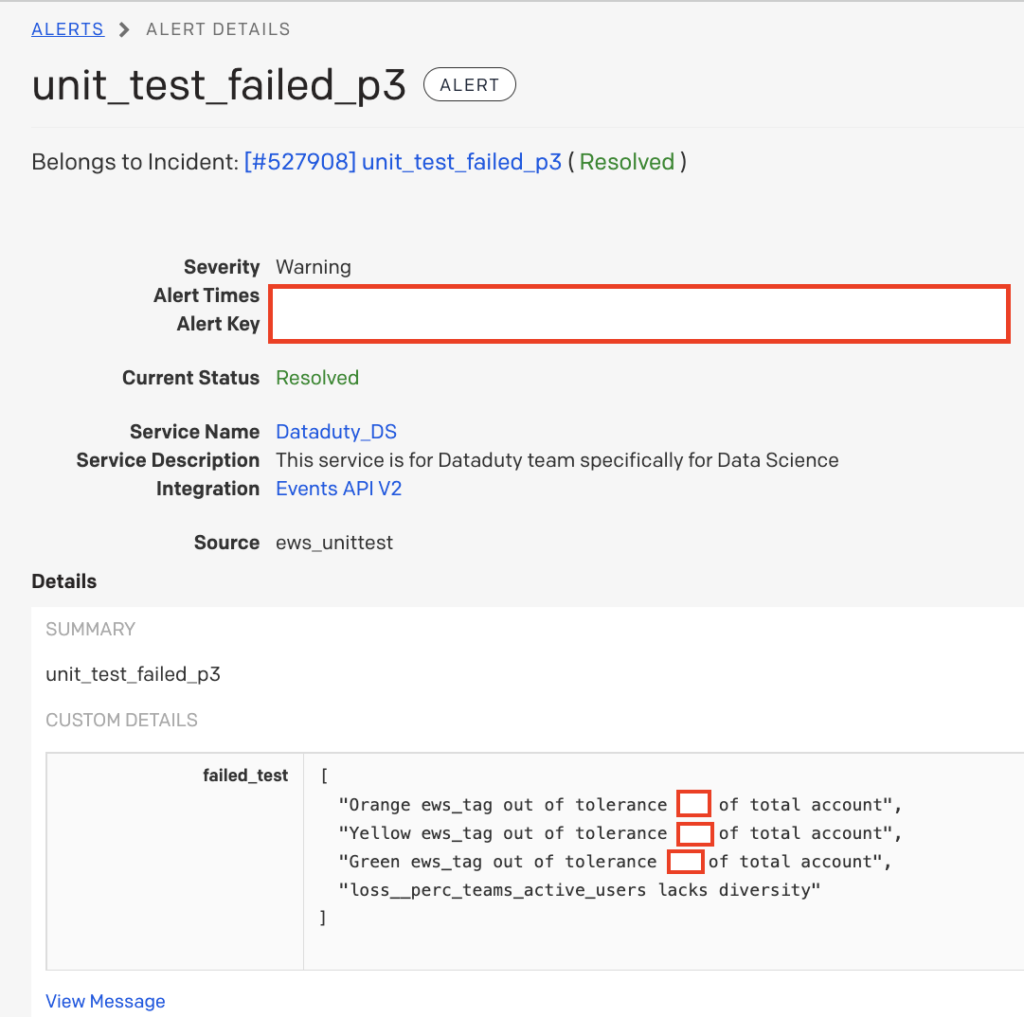
Der Datenwissenschaftler erhielt als Erster eine Warnung, dass möglicherweise etwas mit den Wertungen des Frühwarnsystemmodells nicht stimmt, da diese Tests darauf ausgelegt waren, Konzeptdrift zu erfassen. Die Quelle des Vorfalls war die Quelle „ews_unittest“, in der die Modelldrifttests gespeichert sind. Als Nächstes überprüfte der Datenwissenschaftler den Fehlertext und stellte fest, dass alle Kundenrisiko-Wertungszuweisungen unter ihren erwarteten Toleranzen lagen und eine der Kennzahlen keine großen Abweichungen aufwies. Der Datenwissenschaftler folgerte aus früheren Erfahrungen, dass die Kennzahl im Fehlertext höchstwahrscheinlich „auf Null gesetzt“ wurde, weil die Aggregattabelle nicht aktualisiert wurde. Nach einigen Minuten der Untersuchung bestätigte er, dass dies die Grundursache des Vorfalls war. Er ordnete den Vorfall einem Dateningenieur zu und fügte eine Notiz hinzu, die Aggregattabelle, aus der die problematische Kennzahl stammte, neu zu laden und die Modellberechnungen erneut auszuführen. Innerhalb von dreißig Minuten gab das Modell „Entwarnung“ und die korrekten Werte wurden in die Produktion gebracht, bevor einem der Customer Success-Manager das Problem auffiel. Mithilfe dieser automatisierten Tests und PagerDuty gelang es dem DataDuty-Team, den Vorfall zu diagnostizieren und zu beheben, bevor er den Betrieb des Unternehmens beeinträchtigte, und zwar mit minimaler Unterbrechung der täglichen Arbeit der Dateningenieure und Datenwissenschaftler von DataDuty.
Wenn Data-Science-Modelle zu einer kritischen Infrastruktur für ein Unternehmen werden, in dem Genauigkeit und Verfügbarkeit wichtig sind, sollten Data-Science-Teams Tests hinzufügen, die die Modelldrift überwachen und die entsprechenden Stakeholder bei den ersten Anzeichen von Problemen benachrichtigen. Der Aufbau von Vertrauen unter den Datenmodell-Anwendern ist für den Erfolg von Business-Machine-Learning-Modellen von größter Bedeutung. Wie Kevin Plank einmal sagte: „Vertrauen wird tröpfchenweise aufgebaut und eimerweise verloren“, also lassen Sie nicht zu, dass die Modelldrift das Vertrauen in Ihre Modelle beeinträchtigt.

