- PagerDuty /
- Der Blog /
- Best Practices und Einblicke /
- Bessere SecOps mit Incident Management
Der Blog
Bessere SecOps mit Incident Management
von Patrick O Fallon
7. Juli 2017 | 6 min Lesezeit
Die Bedrohungslandschaft wächst in einem rasenden Tempo. Jeden Tag werden neue Schwachstellen bekannt und die Anzahl der Server, Anwendungen und Endpunkte, die ITOps verwalten muss, wächst ständig. Diese Bedrohungen werden auch immer wirksamer und häufiger, wie eine jüngste Flut von Globale Ransomware-Angriffe haben Täter Tausende von Dollar erpresst. Experten glauben dass es sich dabei oft um eine List handelt, die den Versuch tarnen soll, Daten zu vernichten.
Wenn Organisationen bimodale ITOps Methoden zu entwickeln, um agiler zu sein, Zwischenfälle zu vermeiden und die Sicherheit zu erhöhen, kann eine ziemliche Herausforderung darstellen. Einige der neuen Herausforderungen sind die Nutzung von Containern und öffentlichen Cloud-Ressourcen, die Verwaltung von Sicherheitsvorfällen über diese separaten Datendomänen hinweg und die Arbeit mit völlig neuen Gruppen von Pseudo-Admin-Benutzern, die Zugriff auf wichtige Ressourcen haben. Um die vollständige Stapeltransparenz und Vorfalllösung für die ständig wachsenden Anforderungen an ITOps zu ermöglichen, ist eine vielschichtige Strategie für SecOps erforderlich. Tatsächlich neige ich dazu, das Vorfallmanagement von SecOps als eine notwendige Kombination zu betrachten, um eine wirklich sichere Umgebung aufzubauen, die sowohl umsetzbar als auch sichtbar ist.
Phase 1: Stoppen Sie die Bedrohung
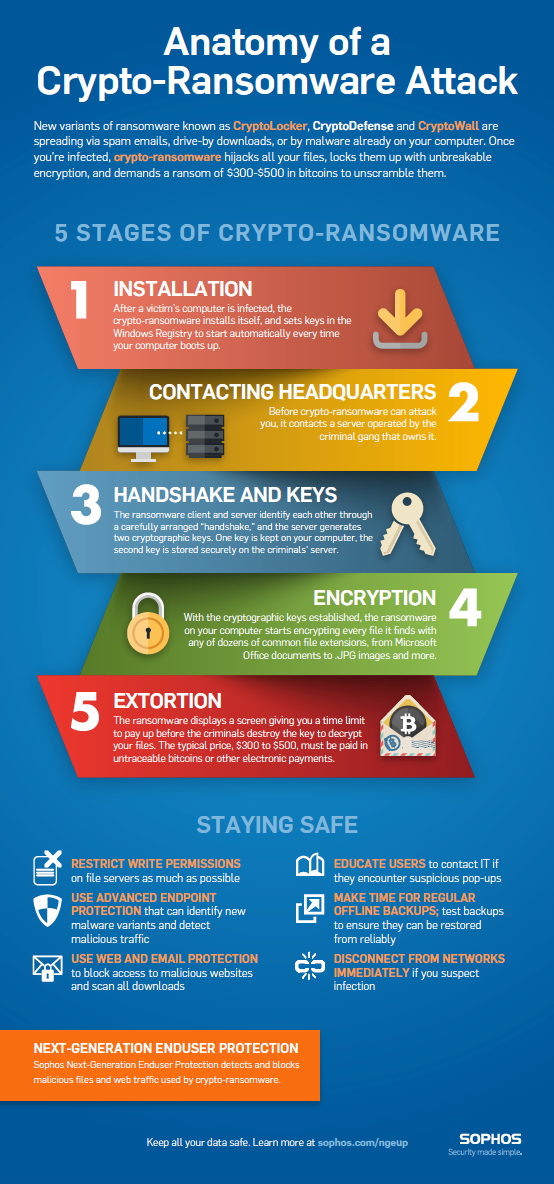
Quelle: Sophos – Anatomie eines Ransomware-Angriffs (Infografik)
In erster Linie hilft Ihnen die Reduzierung der Komplexität Ihres SecOps-Stacks dabei, die Handlungsfähigkeit aufrechtzuerhalten und gleichzeitig Ihre SecOps-Richtlinie durchzusetzen. Einfach ausgedrückt: Vereiteln Sie den Angriff und benachrichtigen Sie Ihr ITOps-Team, dass es Abhilfe schaffen muss. Einfachheit ist der Schlüssel, wenn Sie den Lärm Ihrer Sicherheitswarnungen und -vorfälle reduzieren möchten, damit Sie sich auf die Signale konzentrieren können, die wirklich wichtig sind. SecOps-Praktiken empfehlen, dass Teams eine integrierte Stoppuhr nutzen, um so schnell wie möglich zu reagieren und sicherzustellen, dass Bedrohungen gestoppt werden, bevor sie Produktions-SLAs und kritische Daten beschädigen. Die besten Beispiele für diese Schwere sind, wenn Netzwerke und Systeme ausgesetzt sind Zero-Day-Bedrohungen oder Ransomware . In diesen Fällen besteht der Schlüssel darin, eine Strategie zu entwickeln, um massive Bedrohungen zu stoppen und zu verhindern und gleichzeitig Warnmeldungen an Ihr Vorfallmanagementsystem zu senden. Im Fall von Crypto-Ransomware wie Cryptolocker und Cryptowall besteht das Ziel darin, Tools einzusetzen, die verhindern, dass die Ransomware die Bedrohung auslöst (Phase 2 der folgenden Infografik von Sophos), wodurch der Handshake verhindert und die Crypto-Infektion abgewendet wird.
Wir können dann sicherstellen, dass Firewalls, Endpunkte, Sicherheitsüberwachungstools von Drittanbietern und andere relevante Datenquellen in eine zentrale Vorfallmanagementlösung eingespeist werden. Auf diese Weise können SecOps und ITOps sofort benachrichtigt und mit den Daten und Workflows ausgestattet werden, die für eine effektive Untersuchung und Behebung von Problemen mit hoher Priorität erforderlich sind. Der Einsatz effektiver Sicherheitstools bleibt für den Erfolg bei der Bewältigung Ihrer Sicherheitsvorfälle von entscheidender Bedeutung.
Phase 2 -> Vorfallmanagement und Behebung
Die Fähigkeit, Probleme nicht nur zu erkennen und zu melden, sondern auch zu verbessern, zu eskalieren und ihre Behebung und künftige Vorbeugung zu erleichtern, ist bei der durchgängigen Lebenszyklusverwaltung von Sicherheitsvorfällen ebenso wichtig. Um diese vollständige Transparenz zu erreichen, sollten Sie alle Ihre Sicherheitssysteme in eine zentrale Vorfallmanagementlösung integrieren und aggregieren. Konfigurieren Sie beispielsweise Ihre Firewalls und Netzwerkgeräte so, dass sie Informationen in Ihrer Überwachungsplattform aggregieren, indem Sie SNMP-Traps/-Abfragen nutzen, und integrieren Sie Syslog-Server, um alle Sicherheitsvorfälle an diese Quellen zu senden.

Quelle: Sophos UTM – Syslog-Prioritätswerte
Wenn Sie Ihre Firewall und das Syslogging Ihres Netzwerks konfigurieren, können Sie viel Zeit sparen und die Alarmmüdigkeit reduzieren, indem Sie Schwellenwerte für Warnungen und kritische Alarme gegenüber Info- und Debug-Alarmen konfigurieren. Je nach Anbieter können die Schwellenwerte unterschiedlich sein. Wenn Sie jedoch mit SNMP die OID filtern, um informationsbasierte und Debug-Alarme zu ignorieren, aber Alarme von Warn- und kritischen Statusmeldungen zuzulassen, wird sichergestellt, dass nur Alarme mit hoher Priorität an Ihr Vorfallmanagementsystem gesendet werden.
Mit Syslogging können Sie detailliertere Protokollierungsbedingungen festlegen. Der Schlüssel dabei ist jedoch, den Lärm gering zu halten und nur unter bestimmten Bedingungen zu benachrichtigen. Sobald Sie diese Ereignisse in Ihrem Überwachungssystem aggregiert haben, können Sie ein Framework erstellen, um die Warnungen mit umsetzbaren Informationen anzureichern und sie an Ihr Team weiterzuleiten, um Bedrohungen zu beheben.
Syslogging kann aus mehreren Gründen wertvoll sein. Es erfasst nicht nur detaillierte Informationen zur Sicherheit und den Netzwerkdaten, die in Ihre Überwachungssysteme fließen, sondern kann auch die Erkennung und Verhinderung von Angriffen sowie die Bedrohungsaufklärung erleichtern. Anstatt Ihr Syslog direkt in ein Überwachungssystem zu leiten, haben Sie auch die Möglichkeit, Ihre Syslog-Daten an ein Angriffsanalysesystem eines Drittanbieters zu senden, wie AlienVault oder LogRhythmus um Ihre Einbruchstransparenz zu erhöhen und Ihre Protokolldaten zu bereichern, indem Sie umsetzbare Warnungen erstellen. Anschließend können Sie diese Warnungen an Ihr Vorfallmanagementsystem senden (z. B. PagerDuty ), sodass Sie verwandte Symptome gruppieren, die Grundursache verstehen, an den richtigen Experten eskalieren, im richtigen Kontext Abhilfe schaffen und Analysen und Post-Mortem-Analysen anzeigen und erstellen können, um die Reaktion auf zukünftige Sicherheitsvorfälle zu verbessern.
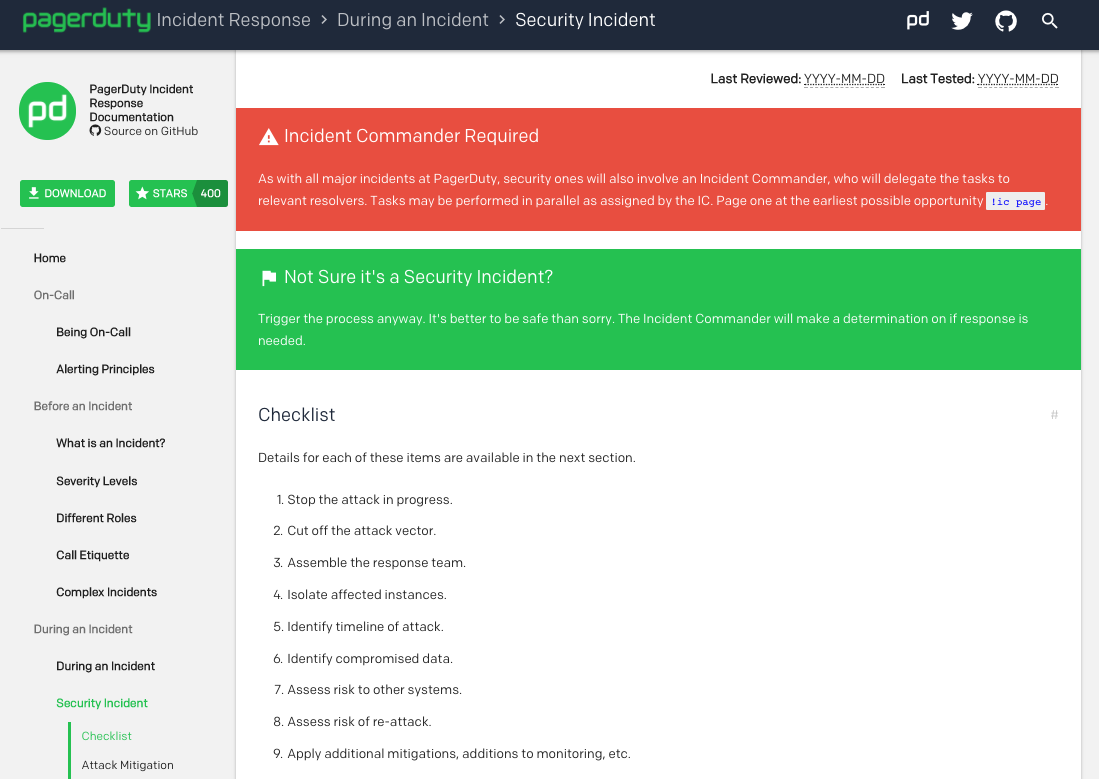
Quelle: PagerDuty Security Incident Response Dokumentation
- Endeffekt: Nutzen Sie Sicherheitstools, um die Bedrohung tatsächlich zu stoppen
- Basisüberwachung: Erstellen Sie eine grundlegende Überwachungs- und Warnrichtlinie
- Anreicherung: Nutzen Sie Tools von Drittanbietern, um Ihre Daten und Bedrohungsinformationen anzureichern
- Vorfallmanagement: Erhalten Sie vollständige Transparenz und stellen Sie sicher, dass Probleme priorisiert, weitergeleitet und eskaliert werden. Verbessern Sie die Lösungszeit mit Workflows und Analysen
Schließlich kann das gleiche Framework für Organisationen mit Hybrid-Cloud- oder Public-Cloud-Ressourcen implementiert werden, obwohl Sie verschiedene Tools von Drittanbietern nutzen müssen, um Ihre Sichtbarkeit und Warnmeldungen zu analysieren und zu verbessern. Zum Beispiel die Nutzung von Azure-Warnungen bei der Nutzung von Microsoft Cloud oder AWS Cloud Watch Wenn Sie die Cloud von Amazon nutzen, können Sie ähnliche Schwellenwerte und Rauschunterdrückung mit der Überwachung und Alarmierung Ihres öffentlichen Cloud-Servers konfigurieren. Die gute Nachricht ist, dass es auch Tools von Drittanbietern gibt, wie z. B. Evident.io Und Bedrohungsstapel das bequem sicherheitsorientierte Analysen Ihrer gesamten Cloud-Infrastruktur durchführt, für jeden mit einer agilen, öffentlichen, hybriden oder bimodalen ITOps-Strategie.
Ganz gleich, welche Tools und Systeme Sie bei der Entwicklung umfassender Incident-Management-Prozesse für Ihr SecOps-Team einsetzen möchten: Die Grundprinzipien Einfachheit, Transparenz, Rauschunterdrückung und Umsetzbarkeit sind für den Erfolg von größter Bedeutung. ITOps- und SecOps-Teams befinden sich in sehr ähnlichen Situationen, in denen die Anforderungen des Unternehmens häufig im Widerspruch zur Fähigkeit dieser Teams stehen, einen sicheren und effizienten Zugriff auf eine ständig wachsende Liste von Geräten, Diensten und anderen Endpunkten zu gewährleisten.
Weitere Informationen zu Best Practices für die Reaktion auf Sicherheitsvorfälle finden Sie unter PagerDutys Open-Source-Dokumentation , die wir intern verwenden. Sie erhalten eine umsetzbare Checkliste und Einblicke, wie Sie Angriffsvektoren abschneiden, Ihr Reaktionsteam zusammenstellen, mit kompromittierten Daten umgehen und vieles mehr. Wir hoffen, dass diese Ressourcen Ihnen einen Vorsprung beim Aufbau eines soliden Rahmens zur Optimierung von SecOps mit effektivem Vorfallmanagement verschaffen, denn das wird Ihr Erfolgsrezept sein.