
- PagerDuty /
- Der Blog /
- Vorfallmanagement und Reaktion /
- Messung der technischen Schulden mit Incident-Management-Daten
Der Blog
Messung der technischen Schulden mit Incident-Management-Daten
von Christopher Tozzi
14. März 2017 | 6 min Lesezeit
Wären technische Schulden wie Geldschulden, wäre es schwierig, den Überblick zu behalten, es sei denn, man checkt manuell ein. Viele Leute erfahren erst, dass ihr Girokonto kein Geld mehr hat, wenn sie sich einloggen und den Kontostand prüfen – oder, schlimmer noch, wenn ein Scheck platzt oder eine Debitkarte abgelehnt wird.
Die Messung technischer Schulden kann jedoch automatischer erfolgen. Denn im Gegensatz zu Ihrem Bankkonto Die IT-Infrastruktur kann überwacht werden mit speziellen Tools auf dem Laufenden gehalten und Sie können benachrichtigt werden über kritische Gesundheitsmetriken . Sie können wiederum Überwachungsdaten um Informationen über technische Schulden zu erhalten. Mit anderen Worten: Sie müssen keine manuelle Prüfung durchführen, um zu wissen, wenn in Ihrem Rechenzentrum etwas schief läuft. Sie müssen nicht warten, bis ein Server ausfällt, um von einem Problem zu erfahren. Incident-Management-Tools stellen Ihnen diese Informationen zur Verfügung. Darüber hinaus bieten sie Ihnen auch eine Möglichkeit, Ihre technische Schuld zu erfassen, ohne die Dinge mühsam von Hand messen zu müssen.
So kann Ihnen das Vorfallmanagement dabei helfen, technische Schulden im Auge zu behalten und zu beheben, ohne dass Sie zusätzlich investieren müssen.
Definition technischer Schulden
 Lassen Sie mich zunächst erklären, was ich mit technischer Schuld meine. Technische Schuld bezieht sich auf Unvollkommenheiten im Softwarecode oder in der Architektur, die auf lange Sicht Ineffizienzen oder andere Probleme verursachen. Selbst wenn die Unvollkommenheit selbst klein ist, kann sie im Laufe der Zeit viel „Zinsen“ verursachen, da sich ihre Auswirkungen ständig wiederholen.
Lassen Sie mich zunächst erklären, was ich mit technischer Schuld meine. Technische Schuld bezieht sich auf Unvollkommenheiten im Softwarecode oder in der Architektur, die auf lange Sicht Ineffizienzen oder andere Probleme verursachen. Selbst wenn die Unvollkommenheit selbst klein ist, kann sie im Laufe der Zeit viel „Zinsen“ verursachen, da sich ihre Auswirkungen ständig wiederholen.
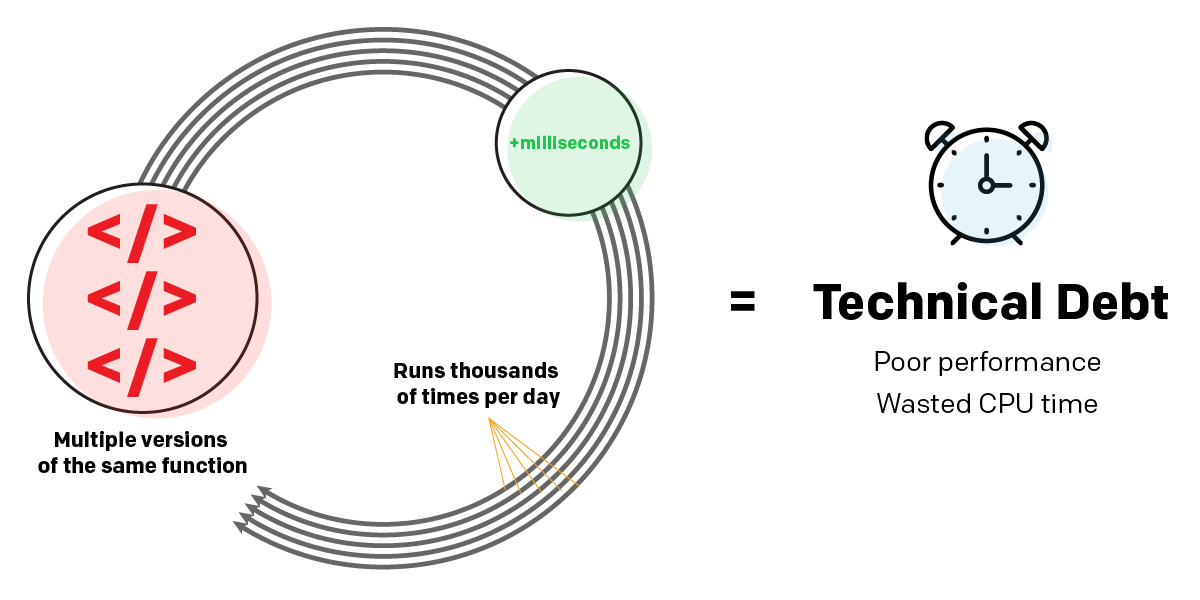
Beispielsweise könnte ein Programm, dessen Code mehrere Versionen derselben Funktionen enthält, anstatt einen modularen Ansatz zu verfolgen, einige Millisekunden länger zum Ausführen brauchen als ein besser geschriebenes Programm. Das ist keine große Sache, wenn Sie es einmal ausführen. Aber wenn es sich um eine serverseitige Webanwendung handelt, die tausende Male am Tag ausgeführt wird, summiert sich der Aufwand schnell in Form von schlechter Leistung und verschwendeter CPU-Zeit.
Technische Schulden haben viele mögliche Ursachen . Manchmal machen Sie bewusst technische Schulden, weil Sie etwas schnell implementieren müssen, Ihnen die Zeit fehlt, Best Practices zu befolgen, und Sie entscheiden, dass die Schulden die Kosten wert sind (zumindest zu diesem Zeitpunkt). Manchmal ist es selbst für den pingeligsten Administrator schwierig, technische Schulden zu vermeiden. Es sei denn, Sie konnten in die Zukunft sehen (Sie wussten beispielsweise wahrscheinlich nicht, dass ein zehn Jahre alter Switch, den Sie heute noch verwenden, weil Sie sich kein Upgrade leisten konnten, mit modernen Firewall-Tools nicht gut funktioniert). In diesem Fall sind technische Schulden einfach Teil des Lebens in einer unvollkommenen Welt.
Technische Schulden verfolgen
Technische Schulden haben zwar viele Ursachen, aber das Schöne an der Messung mithilfe des Incident Managements ist, dass sich die Probleme mit diesem Ansatz ganz einfach verfolgen lassen, unabhängig von ihrer Ursache. Anstatt eine zeitaufwändige manuelle Prüfung Ihrer Systeme durchzuführen, um nach Ineffizienzen zu suchen, können Sie Ihre Incident-Management-Daten als Anhaltspunkt für die Bewertung und Eingrenzung des Ausmaßes technischer Schulden nutzen.
Um zu verstehen, wie das geht, schauen wir uns einige Beispiele für verschiedene Arten von Vorfallmanagementdaten, die PagerDuty verfolgt und was es über Ihre technische Schuld aussagen kann.
Betrachten Sie zunächst die reine Anzahl der Warnmeldungen, die Ihre Tools generieren. Dies ist eine sehr grundlegende Kennzahl, die von einer Reihe von Faktoren beeinflusst werden kann. Vorausgesetzt jedoch, dass Ihre Systeme zur Meldung von Vorfällen richtig konfiguriert sind und Sie keine größeren Änderungen an Ihrer Infrastruktur vornehmen, besteht wahrscheinlich ein Zusammenhang zwischen der Größe Ihrer technischen Schulden und der Anzahl der von Ihren Tools gemeldeten Vorfälle. Denn mehr Schulden bedeuten eine schlechtere Leistung, was wiederum Warnmeldungen auslöst, wenn Reaktionszeiten oder Ressourcenlevel bestimmte Schwellenwerte erreichen. Ein stetiger Rückgang der Warnmeldungen von Monat zu Monat könnte also bedeuten, dass Ihre technischen Schulden sinken, weil Ihr Code effizienter geworden ist.
Mittlere Zeit bis zur Lösung (MTTR) ist eine weitere Kennzahl für das Vorfallmanagement, die einen Einblick in Ihre technische Schuld bietet. Eine häufige Ursache für eine schlechte MTTR ist zu komplexer Code. Um beispielsweise das obige Beispiel noch einmal zu verwenden: Code, der hastig geschrieben wurde und redundante Funktionen enthält, ist für einen Administrator schwer schnell zu verstehen. Das bedeutet eine längere Lösungszeit für den Fall, dass er diesen Code lesen und ändern muss, um auf einen Vorfall zu reagieren.
Die Eskalationsrate in Ihren Vorfallmanagementdaten ist auch ein nützliches Maß für technische Schulden. Eskalationen treten auf, wenn der Ersthelfer bei einem Vorfall das Problem nicht lösen kann und zusätzliche Hilfe anfordern muss. Häufige Eskalationen bedeuten wahrscheinlich eines von zwei Dingen. Erstens sind Ihre Administratoren möglicherweise nicht gut in ihrem Job, aber wenn das der Fall ist, wissen Sie das bereits lange, bevor Sie Ihre Vorfallmanagementdaten überprüfen. Die zweite Hauptursache für Eskalationen ist Code, der zu komplex ist, um von demjenigen, der auf einen Vorfall reagiert, problemlos gehandhabt zu werden. Wenn dies die Art von Code ist, mit dem Ihre Administratoren es zu tun haben, wenn sie auf Warnungen reagieren, besteht eine gute Chance, dass der Code schlecht geschrieben wurde und eine Quelle technischer Schulden darstellt.
Die Quelle technischer Schulden finden
Daten zum Vorfallmanagement helfen Ihnen nicht nur dabei, allgemeine Trends hinsichtlich Ihrer technischen Schulden zu erkennen, sondern sind auch praktisch, um die Ursache eines Problems zu ermitteln.
Wenn beispielsweise Ihre MTTR für Vorfälle im Zusammenhang mit einem bestimmten Programm höher ist als Ihre durchschnittliche MTTR, besteht eine gute Chance, dass das betreffende Programm technische Schulden verursacht. Wenn Server, auf denen ein bestimmter Betriebssystemtyp ausgeführt wird, für eine unverhältnismäßig hohe Anzahl von Warnmeldungen verantwortlich sind, liegt wahrscheinlich ein Code- oder Konfigurationsfehler vor. Das ist eine technische Schuld, die Sie beheben können.
Das Tolle an der Verwendung von Incident-Management-Daten zur Lokalisierung und Behebung technischer Schulden ist, dass dafür kein nennenswerter Mehraufwand erforderlich ist. Sie haben bereits Überwachungssysteme vorhanden, zusammen mit (hoffentlich) einem zentralen Betriebs- und Berichtszentrum wie PagerDuty. Die Nutzung dieser Ressourcen zum Auffinden und Beheben technischer Schulden erfordert keine zusätzlichen Tools oder Investitionen. Es hilft Ihnen, Ihren Code und Ihre Abläufe proaktiv effizienter zu gestalten, indem Sie die Software verwenden, die Sie bereits installiert haben.

