- PagerDuty /
- Der Blog /
- Alarmierung /
- Erstellen von Titeln für die intelligente Gruppierung von Warnmeldungen
Der Blog
Erstellen von Titeln für die intelligente Gruppierung von Warnmeldungen
von Quintessenz Anx
27. Januar 2022 | 7 min Lesezeit
Mitautor: Chris Bonnell, PagerDuty Data Scientist VI
Wir machen mit unserem dritten Beitrag weiter, in dem es darum geht, wie Sie Ihr Intelligent Alert Grouping (IAG) nutzen und verbessern können! Falls Sie es verpasst haben, haben wir Ihnen in unserem ersten Beitrag die Funktion Intelligent Alert Grouping vorgestellt. ( Hier ). Im zweiten Beitrag haben wir erklärt, wie IAG das Zusammenführen verwendet, um Warnmeldungen zu gruppieren (Hier) . Wir haben Ende letzten Jahres auf den heutigen Beitrag angespielt: Heute besprechen wir, wie man mithilfe von Alarmtiteln IAG-Übereinstimmungen verbessern kann.
Wo Sie den Alarmtitel sehen – eine Auffrischung
Wenn auf unserer Plattform ein Alarm ausgelöst wird, kann die Benachrichtigung über mehrere Wege erfolgen: E-Mail, SMS oder Push-Benachrichtigung aus der App selbst. Unabhängig vom Pfad werden mindestens folgende Informationen angezeigt: Alarmnummer, Dienst und Alarmtitel. Diese werden an einigen wichtigen Stellen angezeigt. Je nachdem, wie Sie Erhalten Sie Ihre Benachrichtigungen , einige oder alle davon kommen Ihnen vielleicht bekannt vor. Beachten Sie, dass die Dringlichkeitsstufe (z. B. hoch) zwar verwendet wird, um zu bestimmen, wie Sie erreicht werden, sie wird jedoch nicht sichtbar angezeigt (steht aber in den Vorfalldetails).
Telefon-Push- und Textbenachrichtigungen
Schauen wir uns beispielsweise den Sperrbildschirm eines iPhones an (zusätzlich zur Textbenachrichtigung und zum Telefonanruf für denselben Vorfall):
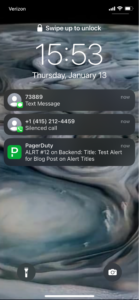
In diesem Fall habe ich die Benachrichtigung für den Blogbeitrag an alle Kanäle gesendet. Hier können Sie sehen, dass der Benachrichtigungstitel, die Nummer und der Dienst angezeigt werden. Eine Textnachricht sieht ähnlich aus:

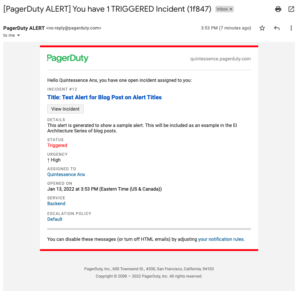
E-Mail Benachrichtigungen
Diese sehen etwas anders aus. Der Betreff der E-Mail enthält nicht viele Details, aber die vollständigen Alarmdetails sind im Nachrichtentext enthalten:
Warum überprüfen wir, wo Warnmeldungstitel angezeigt werden?
Wenn Sie wie ich sind, haben Sie beim Schreiben von Warnmeldungstiteln und -beschreibungen für reale Situationen und reale Dienste wahrscheinlich auf das menschliche Gehirn hin optimiert. Sie können Artefakte davon sogar oben sehen. Der Warnmeldungstitel liest sich eher wie eine Art Blogbeitragstitel und enthält plump den Bezeichner „Titel“ im Titel selbst, um hervorzuheben, wo er erscheint. Dies ist für Menschen – wenn Sie diese Bilder überfliegen, möchte ich Ihre Aufmerksamkeit auf bestimmte Bereiche lenken.
Was wäre, wenn ich für Nicht-Menschen designen würde? Was wäre zum Beispiel, wenn ich auf maschinellem Lernen aufbaue? Ich würde wahrscheinlich alles, was ich über maschinelles Lernen weiß oder gelernt habe, nehmen und anfangen, die Botschaft zu verzerren, um es zu begünstigen.
Aus all dem möchte ich Ihnen Folgendes mit auf den Weg geben: Vergessen Sie nicht, dass Sie auch den Menschen im Auge behalten müssen, wenn Sie beginnen, Ihr Wissen über maschinelles Lernen einzubringen, um Ihre Erfahrung mit Intelligent Alert Grouping zu verbessern.
So nutzen Sie Ihren Alarmtitel zu Ihrem Vorteil
Wenn Sie den Alarmtitel für Personen erstellen, beachten Sie Folgendes:
- Seien Sie präzise. Wie Sie sehen, haben sowohl Push- als auch Textbenachrichtigungen eine kurze Zeichenbegrenzung.
- Es gibt unterschiedliche Beschränkungen je nach Betriebssystem und Webbrowser. Beispielsweise hat Android eine Zeichenbeschränkung von 65 Zeichen für Push-Titel und eine zusätzliche Beschränkung von 240 Zeichen für eine Beschreibung, während iOS eine kombinierte Zeichenbeschränkung von 178 Zeichen für Titel und Beschreibung hat.
- Seien Sie klar. Seien Sie nicht so kurz, dass der Titel verwirrend ist oder nichts aussagt.
- Bevorzugen Sie nicht das Titelfeld und vernachlässigen Sie die anderen Felder.
- Die PagerDuty -Mobil-Apps sowie die Weboberfläche verfügen über alle Vorfallinformationen, einschließlich anderer Vorfälle, ihrer Dienste und ihrer Beschreibungen. Laden Sie keine Informationen in das Titelfeld, nur weil es zuerst angezeigt wird.
Weitere Informationen hierzu finden Sie in unserer Benachrichtigung von Auftraggebern Seite in unserem Incident Response Ops Guide.
Beachten Sie beim maschinellen Lernen Folgendes:
- Nutzen Sie Einzigartigkeit und Häufigkeit zu Ihrem Vorteil.
- Datenmodelle können nicht lesen (im selben Sinne wie Menschen).
- Datenmodelle können nicht auf Absichten schließen.
Der Grund hierfür ist das Verständnis, wie Maschinen die sogenannte „natürliche Sprachverarbeitung“ durchführen. Die natürliche Sprachverarbeitung ermöglicht es einer Rechtschreib- oder Grammatikprüfung, zwischen „it's“ und „its“ zu unterscheiden und den Autor entsprechend zu benachrichtigen, oder ermöglicht der Autokorrektur, zu erkennen, welches Wort und welche Konjugation und welche Form (Konjugation, Deklination) vorgeschlagen werden soll. Die natürliche Sprachverarbeitung gilt für Alarmtitel: Titel werden anonymisiert (mehr dazu gleich), in sogenannten „Satz-Tokenisierung“ bzw. „Wort-Tokenisierung“ in Sätze und dann in Wörter zerlegt, dann werden die Wörter lemmatisiert und das Endergebnis wird verwendet, um die Häufigkeit zu bestimmen und nach Korrelationen mit anderen Alarmen zu suchen.
Beginnen wir mit der Anonymisierung: Ziel ist es, ansonsten zu einzigartige Informationen durch das Muster dieser Informationen zu ersetzen, z. B. eine bestimmte IP-Adresse durch xx.xx.xx.xx zu ersetzen. Dieser Text wird nicht vollständig entfernt, um zu vermeiden, dass potenziell relevanter Kontext vollständig entfernt wird, sondern um zu verhindern, dass die einzigartigen Informationen dazu führen, dass Titel nicht korreliert werden, obwohl sie korreliert werden sollten. Lemmatisierung ist der Prozess der Vereinfachung konjugierter oder deklinationsfähiger Wörter in eine Grundform, ein sogenanntes Lemma. Wieder als Beispiel: {„dogs“, „dog's“, „dogs'“, „dog“} würden alle zu „dog“ lemmatisiert und ebenso {„is“, „are“, „be“, „were“} zu „be“. Das bedeutet, dass Sätze wie „The dog's bones.“ und „The dogs' bones.“ in dieser Phase beide zu {„the“, „dog“, „bone“, „.“} lemmatisiert werden.
An diesem Punkt verwendet das Modell „Intelligent Alert Grouping“ sowohl N-Gramme (Gruppen von N Wörtern) als auch unser Wissen über die Sprachmuster von Vorfällen, um Informationen aus dem Alarmtitel zu extrahieren und sinnvolle Korrelationen herzustellen. Werfen wir noch einmal einen Blick auf die Beispiele, die ich in meinem vorherigen Post :
- Erstes Muster:
- Hoher Speicherverbrauch (> N %) auf Server $NAME in Region $REGION
- Zweites Muster:
- Die Speichernutzung auf dem Host ist hoch (> N %)
Ich habe mit N % und $NAME bereits ein wenig anonymisiert, aber gehen wir nun die Tokenisierung der Inhalte dieser Titel durch:
- Tokenisiertes und lemmatisiertes erstes Muster:
- {„Speicher“, „Verwendung“, „hoch“, „(“, „>“, „N“, „%“, „)“, „auf“, „Server“, „$NAME“, „in“, „Region“, „$REGION“}
- Tokenisiertes und lemmatisiertes zweites Muster:
- {„Speicher“, „verwenden“, „auf“, „Host“, „sein“, „hoch“, „(“, „>“, „N“, „%“, „)“}
Wenn wir die Auswirkungen der Bedeutung der Muster berücksichtigen, ist in der zweiten Warnung der einzige Begriff, der variiert, N, abhängig vom dort eingegebenen Wert. Wenn der Schwellenwert konsistent ist und nicht die aktuelle Speichernutzung, variiert N möglicherweise überhaupt nicht oder hat nur einen oder zwei Werte, die im Titel erscheinen. Im Gegensatz dazu ist der Titel der ersten Warnung eindeutiger, was den Namen des Servers und seiner Region betrifft. Das sind also drei variierende Begriffe statt einem oder keinem. Was den Sprachprozessor betrifft, ist es daher viel wahrscheinlicher, dass Warnungen des zweiten Musters korreliert sind als die des ersten.
Wie geht es weiter?
Es ist wichtig, beim Erstellen Ihrer Alarmtitel sowohl menschliches als auch maschinelles Lernen zu berücksichtigen. leicht Schiefe zur Optimierung des maschinellen Lernens, da Benutzer die vollständigen Alarm- und Vorfalldetails nutzen können, um zusätzlichen Kontext und Informationen zu erhalten, während bei der intelligenten Alarmgruppierung nur das Titelfeld verwendet wird. Weitere Informationen zu den Grundlagen der Verarbeitung natürlicher Sprache finden Sie in Einführung in die natürliche Sprachverarbeitung für Text Blogbeitrag im Towards Data Science-Blog. Best Practices dazu, welche Informationen in Warnmeldungen und Vorfällen im Allgemeinen relevant sind, finden Sie in unserem Leitfaden für Incident Response Ops .

