
- PagerDuty /
- Der Blog /
- Überwachung /
- Intelligente SLO-Warnung mit Wavefront
Der Blog
Intelligente SLO-Warnung mit Wavefront
von Pontus Rydin
7. November 2019 | 9 min lesen
SLOs sind gerade wichtig geworden
In der guten alten Zeit monolithischer Anwendungen verließen sich die meisten Entwickler und Anwendungsbesitzer auf Stammeswissen, um die zu erwartende Leistung zu ermitteln. Obwohl Anwendungen unglaublich komplex sein konnten, war das Verständnis ihrer Funktionsweise normalerweise nur relativ wenigen Mitarbeitern im Unternehmen gegeben. Die Anwendungsleistung wurde informell verwaltet und beiläufig gemessen.
In einer Microservices-Welt funktioniert dieses Modell jedoch nicht mehr. Bei Verwendung informeller Methoden kann sich ein einzelnes Team oder eine kleine Gruppe kein Gesamtbild einer Anwendung mehr verschaffen und daher auch keine Rückschlüsse auf ihre Leistung ziehen. Dies liegt daran, dass die Serviceketten sehr tief sein können und ein mangelndes Verständnis der Leistung der nachgelagerten Komponenten zu unliebsamen Überraschungen führen kann, die sich letztlich sowohl auf die Endbenutzer als auch auf das Unternehmen auswirken.
Was ist also ein SLO?
Bevor wir fortfahren, definieren wir ein Service Level Objective (SLO) sowie einige zugehörige Konzepte und Akronyme.
SLIs sind das, was wir messen
Ein Service Level Indicator (SLI) ist eine Größe, die wir messen, um festzustellen, ob wir ein SLO einhalten. Sehr häufig messen SLIs entweder die Erfolgsrate oder die Leistung eines Vorgangs, aber ein SLI kann auch jede beliebige Metrik sein.
SLOs machen SLIs umsetzbar
Damit ein SLI interessant ist, muss es mit einer Bedingung verknüpft sein. Wir können beispielsweise festlegen, dass 99 % aller Vorgänge erfolgreich abgeschlossen werden müssen oder dass 95 % aller Transaktionen innerhalb einer Sekunde abgeschlossen sein müssen. Wir drücken SLOs häufig als Prozentsatz über einen bestimmten Zeitraum aus. So können wir beispielsweise die Erfolgsrate von 99 % über 24 Stunden messen und die Latenzleistung von 95 % besser als eine Sekunde über eine Stunde.
Ein SLO sollte erreichbar, wiederholbar, messbar, verständlich, sinnvoll, kontrollierbar, erschwinglich und für beide Seiten akzeptabel sein. 1 Beispielsweise ist eine Transaktionserfolgsrate von 99,9999999 % möglicherweise nicht erreichbar, weil handelsübliche Hardware dieses Maß an Zuverlässigkeit nicht bieten kann. Ebenso ist ein SLO, das auf einer obskuren technischen Metrik basiert, für die meisten Benutzer wahrscheinlich weder verständlich noch sinnvoll.
SLAs sind SLOs mit einer „Oder-sonst“-Klausel
Während SLOs einklagbar sind, werden sie durch Service Level Agreements (SLAs) aus rechtlicher Sicht durchsetzbar. SLAs fügen dem SLO in der Regel eine Geldstrafe bei, die beispielsweise besagt, dass wir, wenn wir unser SLO für einen Kunden nicht erfüllen, möglicherweise dazu verpflichtet sind, einen bestimmten Prozentsatz des Geldes zurückzuzahlen, das dieser bei uns ausgegeben hat. Normalerweise müssen wir uns als Techniker nicht so viele Gedanken über SLAs machen, da sich unsere Anwälte darum kümmern.
Implementierung guter SLOs
Wie sich herausstellt, ist die Implementierung eines guten SLO nicht so einfach, wie man auf den ersten Blick denken könnte. Ein naiver Ansatz könnte darin bestehen, die Abweichung vom „Guten“ über einen gewissen Zeitraum zu messen und darauf hinzuweisen. Dieser einfache Ansatz hat jedoch eine ganze Reihe von Nachteilen. Die folgende Diskussion basiert auf Best Practices in der Google SRE-Handbuch . Lassen Sie uns untersuchen, wie diese Ideen verwendet werden können, um nützliche SLOs zu implementieren mit Wellenfront !
Auswahl des richtigen SLI
Die Auswahl der richtigen Metrik als Grundlage für einen SLI ist eine Kunst für sich und würde einen eigenen Artikel wert sein. In der Regel sollten wir eine Metrik wählen, die für das Unternehmen aussagekräftig und umsetzbar ist. Gute Metriken sind beispielsweise Fehlerraten und die Leistung von Geschäftsdiensten. Schlechte Metriken sind beispielsweise rein technische Metriken und Metriken, die kein umsetzbares Ergebnis liefern. Hier sind einige Beispiele:

Fehlerbudgets
Niemand ist perfekt, deshalb müssen wir uns einen gewissen Spielraum für Fehler einräumen. Ein System mit 100 % Verfügbarkeit ist nicht realistisch, deshalb müssen wir einen Kompromiss zwischen unserem Wunsch, ein zuverlässiges System bereitzustellen, und den verfügbaren Ressourcen finden. Unsere Erwartungen an die Verfügbarkeit zu hoch zu schrauben, ist einer der schlimmsten Fehler, die wir machen können. Das führt zu ständigen Warnungen, die die Leute letztendlich ignorieren und die die wahren Probleme verschleiern.
Wir müssen also bestimmen, wie viel Zeit wir uns innerhalb eines bestimmten Zeitraums erlauben, die Vorschriften nicht einzuhalten. Dies wird normalerweise als Prozentsatz ausgedrückt. Beispielsweise können wir uns erlauben, 1 % unserer Zeit nicht einzuhalten. Normalerweise wandeln wir diesen Prozentsatz in eine Verfügbarkeitszahl um. Bei einem Fehlerbudget von 1 % gehen wir also von einer Verfügbarkeit von 99 % aus.
SLO Windows
Das nächste Problem ist der zu messende Zeitrahmen. Wir nehmen an, dass wir 1 % der Zeit die Vorschriften nicht einhalten dürfen, aber in welchem Zeitraum? Die Auswahl dieses Zeitrahmens erweist sich als schwierig zu lösendes Problem. Wenn wir über einen sehr kurzen Zeitraum messen, sagen wir 10 Minuten, lösen unbedeutende Störungen ständig Warnungen aus. Wenn wir hingegen über einen längeren Zeitraum messen, sagen wir 30 Tage, werden wir zu spät gewarnt und laufen Gefahr, schwerwiegende Ausfälle ganz zu übersehen.
Brennraten
Nehmen wir an, unser Vertrag mit unseren Benutzern sieht eine Verfügbarkeit von 99,9 % über 30 Tage vor. Das entspricht einem Fehlerbudget von 43 Minuten. Wenn wir diese 43 Minuten in kleinen Schritten kleiner Störungen ausnutzen, sind unsere Benutzer wahrscheinlich immer noch zufrieden und produktiv. Aber was passiert, wenn wir zu einem geschäftskritischen Zeitpunkt einen einzelnen Ausfall von 43 Minuten haben? Man kann mit Sicherheit sagen, dass unsere Benutzer mit dieser Erfahrung ziemlich unzufrieden wären!
Um dieses Problem zu lösen, können wir Burn-Raten einführen. Die Definition ist einfach: Wenn wir in unserem Beispiel über 30 Tage hinweg genau 43 Minuten brennen, nennen wir das eine Burn-Rate von eins. Wenn wir doppelt so schnell brennen, z. B. in 15 Tagen, ist die Burn-Rate zwei und so weiter. Wie Sie sehen werden, können wir so die langfristige Compliance verfolgen und auf schwerwiegende, kurzfristige Probleme aufmerksam machen.
Die folgende Grafik veranschaulicht das Konzept mehrerer Burn-Raten. Die X-Achse stellt die Zeit dar und die Y-Achse unser verbleibendes Fehlerbudget.
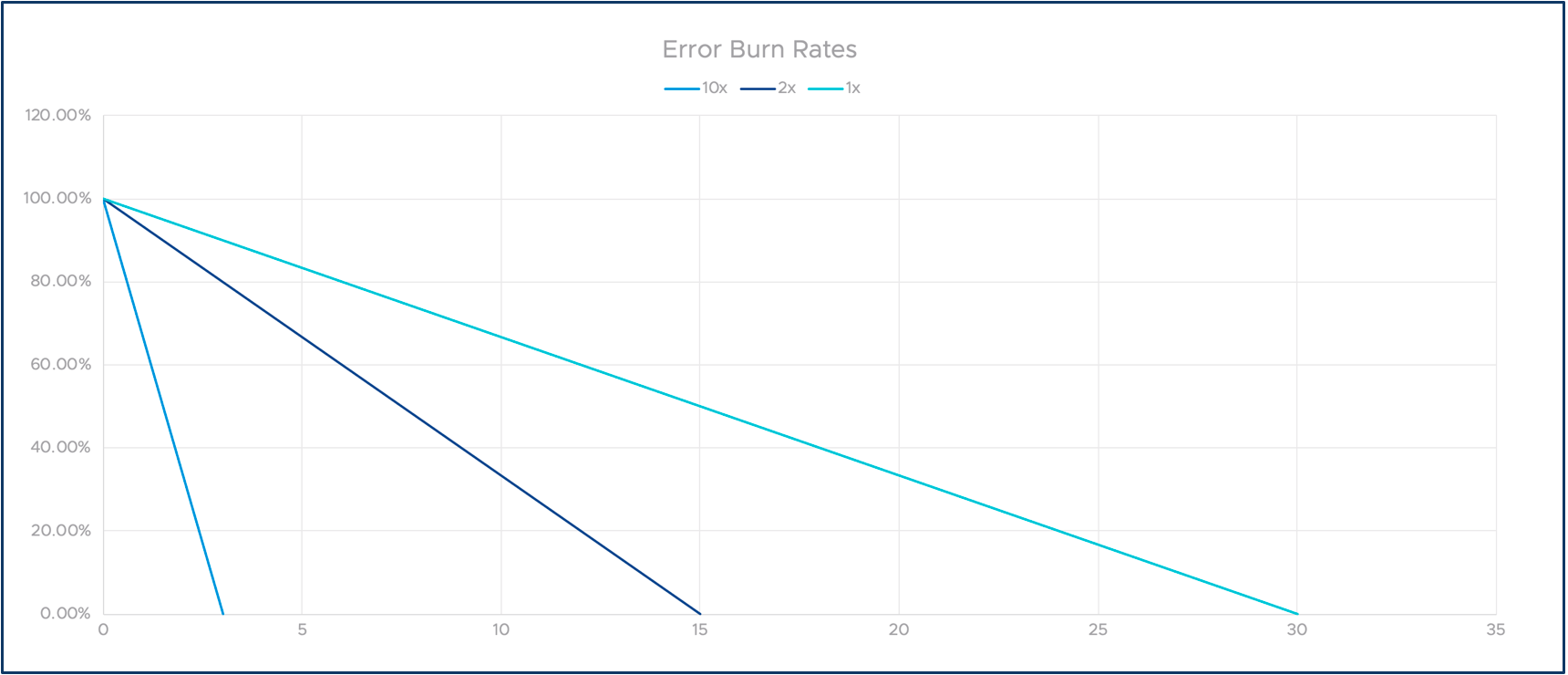
Alles zusammenfügen
Lassen Sie uns nun das gerade Erklärte nehmen und es zu einer nützlichen Lösung für SLO-Überwachung und -Alarmierung zusammenfassen!
Wir haben gelernt, dass die langfristige Überwachung eines SLO-Trends und die kurzfristige Alarmierung mit unterschiedlichen Methoden erfolgen müssen. Wir haben auch das Konzept der Burn-Rates vorgestellt. Wie können wir daraus also eine großartige SLO-Alarmierungslösung machen?
Mehrere Fenster?
Eine Idee besteht darin, mehrere Zeitfenster für sofortige Warnungen und längerfristige Trendbeobachtungen zu verwenden. Das Problem besteht darin, dass bei Auswahl eines einstündigen Fensters bei einem 99 %-Ziel nur 36 Sekunden Nichteinhaltung möglich sind. Bei einem 99,9 %-Ziel sinkt diese Zahl auf 3,6 Sekunden! Dies würde zu vielen lauten Warnungen bei kleineren Störungen führen.
Mehrere Fenster, mehrere Brennraten
Eine Möglichkeit, dieses Problem zu lösen, besteht darin, die oben besprochenen Burn-Raten zu verwenden. Wenn wir ein kürzeres Zeitfenster betrachten, messen wir anhand einer schnelleren Burn-Rate. Dadurch können wir Warnungen auslösen, wenn ein Dienst für einen längeren Zeitraum nicht verfügbar war. Wenn wir über ein längeres Zeitfenster überwachen, verwenden wir eine langsamere Burn-Rate, um besorgniserregende Trends zu erkennen. Die folgende Tabelle zeigt, wie dies erreicht werden kann.

Das bedeutet, dass wir einen kritischen Alarm auslösen sollten, wenn wir unser Fehlerbudget innerhalb eines einstündigen Zeitfensters mit einer Rate von 14,4 aufbrauchen. Wir wählen 14,4, weil dies einer Aufbrauchrate von 2 % über eine Stunde entspricht.
Wenn wir andererseits über einen längeren Zeitraum ein langsames Brennen beobachten, hat dies möglicherweise keine schwerwiegenden Auswirkungen auf die Benutzer, bedeutet aber, dass wir auf dem besten Weg sind, unser SLO über einen längeren Zeitraum zu verletzen. Die erste Warnung sollte dazu führen, dass jemand sofort angepiept wird, während die zweite eine Warnung mit niedrigerer Priorität sein kann, die sich jemand ansehen kann, wenn er Zeit hat.
Wie Wavefront hilft
Wie wir gesehen haben, ist die Implementierung eines guten SLO relativ schwierig. Sie müssen eine Menge rechnen und komplexe Entscheidungen treffen. Dafür benötigen Sie ein Tool mit einer erweiterten Analyse-Engine, einer umfangreichen Abfragesprache und flexiblen Funktionen zur Erstellung von Warnmeldungen. Mit anderen Worten: Sie brauchen Wavefront!
Nehmen wir an, wir haben einen SLI für die Antwortzeit eines Dienstes. Hier ist die Zeitreihe für unsere SLI-Metrik.
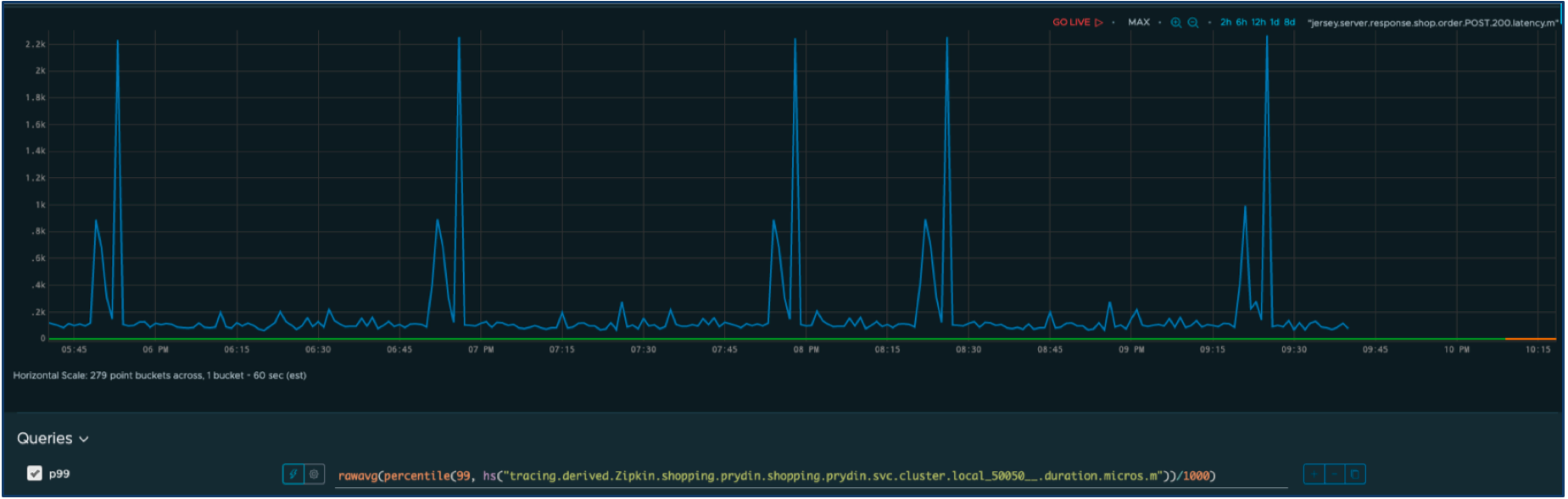
Definieren wir eine akzeptable Leistung als eine Reaktionszeit von weniger als einer Sekunde. Alles andere wird als Ausfall betrachtet, der sich negativ auf die Benutzer auswirkt. Wir können die Abfrage leicht ändern, um Folgendes herauszufiltern: nur die Ausfälle.
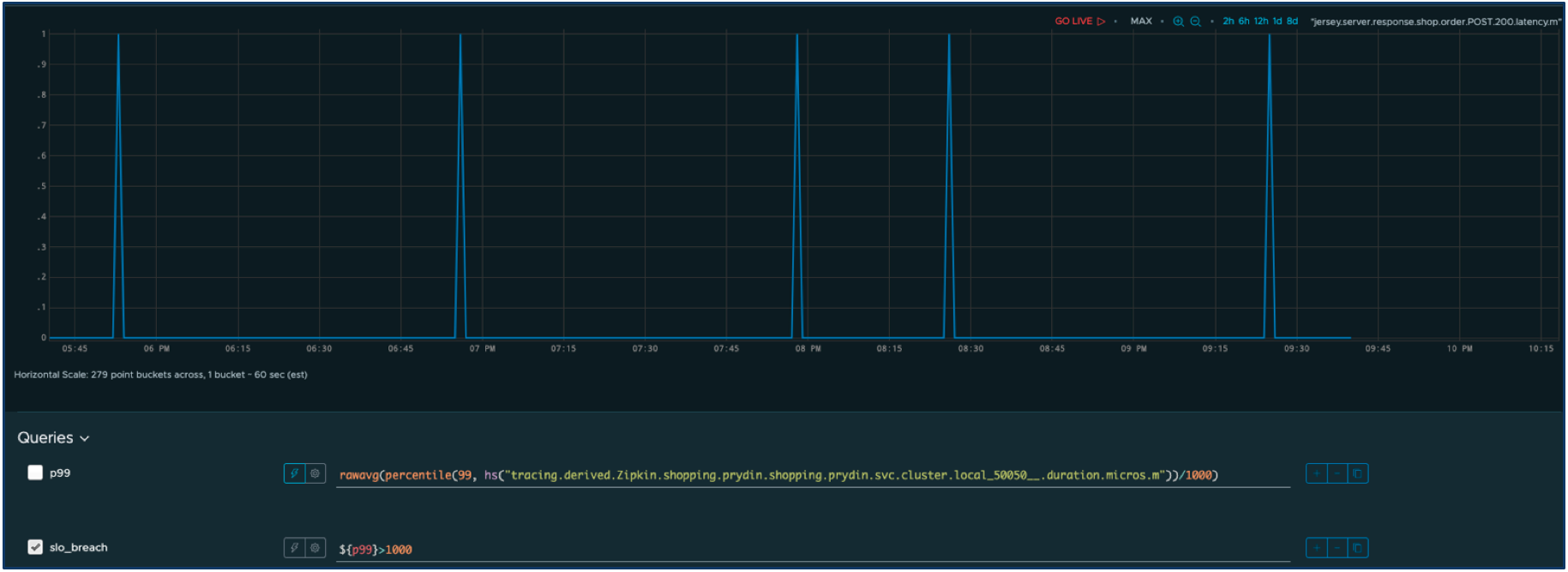
Nun definieren wir zwei Fenster – ein kurzfristiges Fenster mit einer aggressiven Burn-Rate und ein längerfristiges Fenster mit einer langsameren Burn-Rate. Wir können nun die angepasste Burn-Rate im Zeitverlauf für beide Fenster berechnen.
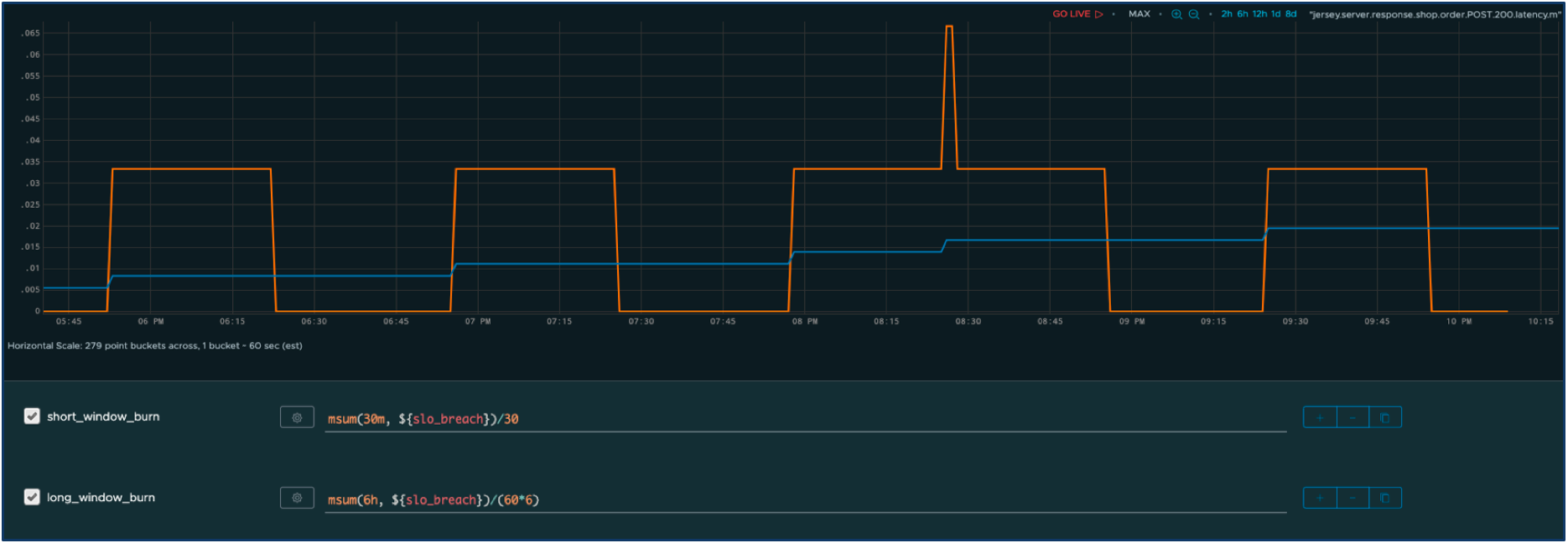
Die orangefarbene Reihe stellt die kumulierte Ausfallzeit über das kürzere Fenster dar und die blaue Reihe über das längere Fenster. Wie Sie sehen, haben die Spitzen in den Antwortzeiten unmittelbare Auswirkungen auf das kurze Fenster, tragen aber auch zu einer langsamen inkrementellen Änderung der längerfristigen Auslastung bei. Darüber hinaus unterdrücken wir dank des Burn-Rate-Multiplikators Warnungen, die durch unbedeutende Störungen verursacht werden.
Klicken wir in der Wavefront-Benutzeroberfläche auf die Schaltfläche „Alarm erstellen“ und definieren einen Alarm, der ausgelöst wird, wenn eines der Fenster sein zugewiesenes Fehlerbudget überschritten hat.
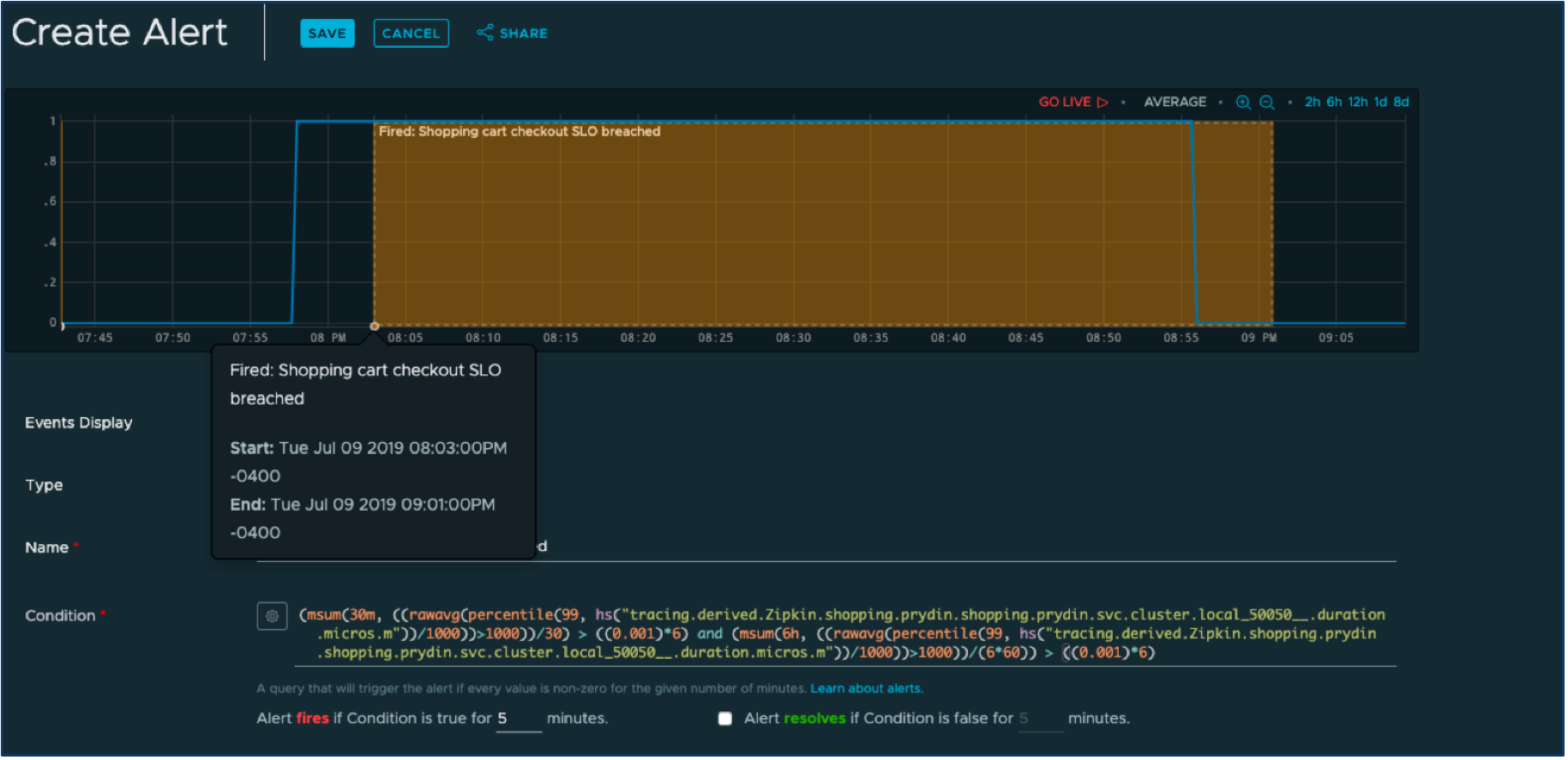
Die komplex aussehende Abfrage unten ist aus den viel einfacheren Abfragen synthetisiert, die wir bereits definiert haben. Jetzt müssen wir nur noch den Alarmbenachrichtigungsmechanismus auswählen, z. B. PagerDuty (es gibt eine großartige sofort einsatzbereite Integration zwischen Wavefront und PagerDuty ), und wir werden es wahrscheinlich schnell herausfinden, wenn die Gefahr besteht, dass wir unsere SLOs nicht mehr einhalten.
Abschluss
In diesem Blog haben wir gesehen, dass die Alarmierung bei einem SLO ziemlich komplex ist. Aber dank der Abfragesprache und Alarmierungsmechanismen in Wavefront können wir in wenigen Minuten intelligente SLO-Alarme erstellen.
In einem realen Szenario gibt es zusätzliche Techniken, mit denen die Warnungen noch weiter verfeinert werden können. Beispielsweise möchten wir möglicherweise mehrere Fenster pro Burn-Rate verwenden. Wenn Sie mehr darüber erfahren möchten, ist das Google SRE-Handbuch ein guter Ausgangspunkt.
Weitere Informationen zur Wavefront Enterprise Observability Platform finden Sie in unserem Kostenlose Testphase Heute.
1. Rick Sturm, Wayne Morris „Grundlagen des Service Level Managements“, April 2000, Pearson
Über den Autor
Pontus Rydin hat in den letzten zehn Jahren mit IT-Management- und Betriebslösungen gearbeitet und verfügt über einen umfassenden Hintergrund in Softwareentwicklung und Anwendungsmanagement. Derzeit ist er Technology Evangelism Director und Developer Advocate für Wavefront von VMware. Seine übergeordnete Mission besteht darin, Entwicklern und SREs zu helfen, Einblick und Kontrolle über ihre Anwendungen zu gewinnen, um die Geschäftsleistung zu steigern und gleichzeitig das Risiko zu verringern. Pontus verbringt seine Tage mit der Arbeit an allem möglichen, von Open-Source-Beiträgen über direkte Gespräche mit Kunden bis hin zu Konferenzen, wo er über verschiedene digitale Kanäle seine Meinungsführerschaft teilt.
Das könnte Ihnen auch gefallen ...

