
- PagerDuty /
- Der Blog /
- Automatisierung /
- Was ist automatisierte Diagnose und warum ist sie für Sie wichtig?
Der Blog
Was ist automatisierte Diagnose und warum ist sie für Sie wichtig?
von Joseph Mandros
3. Juni 2022 | 6 min Lesezeit
Wie messen Sie die Kosten eines Vorfalls?
Viele Leute in der Technologiebranche betrachten die Kosten eines Vorfalls ausschließlich aus der Perspektive der Ausfallzeit oder der Anzahl der betroffenen Kunden und Mitarbeiter. Und oberflächlich betrachtet ist das oft ein fairer Ansatz. Es macht Schlagzeilen, und der Ruf und das Vertrauen der Kunden sind für den Erfolg eines jeden Unternehmens von entscheidender Bedeutung – das ist klar.
Ein weiterer direkter Kostenfaktor von Vorfällen, der selten berücksichtigt wird, ist die Anzahl der Personen, die bei einem Vorfall eingreifen müssen. Dies kann beispielsweise dazu dienen, die Grundursache zu ermitteln, den Vorfall zu beheben oder zu lösen oder das Team von seiner Verantwortung zu entbinden. Dabei spielt es keine Rolle, ob der Vorfall schwerwiegend genug ist, um Ihre Kunden zu beeinträchtigen.
Laut PagerDuty Daten 50 % von Die Zeit eines Helfers wird damit verbracht, zu bestimmen, wer am besten für zusätzliche Unterstützung hinzugezogen werden kann ( und versuchen herauszufinden, ob es tatsächlich ein Problem gibt ) in einer Umgebung x oder mit einem Dienst y. Angesichts dieser Statistik bedeutet dies, dass 50 % der Lebensdauer eines Vorfalls in den Anfangsphasen eines Vorfalls (Diagnose- und Triage-Phasen) verbracht werden und nicht in tatsächlichen Abhilfemaßnahmen.
Das Endergebnis? Die Kosten für Arbeitsstunden und die Anzahl der manuellen Aktionen pro Vorfall können schnell enorm werden.
Automatisieren Sie Ihre Reaktion auf Vorfälle
Für den Erfolg der letztendlichen Behebung des Vorfalls ist es von entscheidender Bedeutung, die frühen, wiederkehrenden Phasen des Vorfalls automatisiert abzuarbeiten. Dazu gehört auch die Diagnose der Schwere des Vorfalls und das Verständnis der genetischen Struktur dessen, was schief gelaufen ist (und wie).
Automatisierung ist auch aus menschlicher Sicht wichtig, um sicherzustellen, dass Ihre Teams nicht jedes Mal, wenn ein Vorfall eintritt, durch die gleichen, sich wiederholenden Aktionen ausgebrannt werden. Für die Routing-Effizienz und den Gesamtablauf der Vorfallreaktion ist es von größter Bedeutung, sicherzustellen, dass die Diagnosedaten den Ersthelfern zur Verfügung stehen.
Bevor wir fortfahren, definieren wir zunächst Diagnosedaten. Diagnosedaten Ist Daten, die von Einsatzkräften abgerufen werden und die normalerweise spezifischer sind als die von Überwachungstools bereitgestellten Informationen. Während Überwachungstools Sie beispielsweise warnen, wenn es zu einem Anstieg der CPU- oder Speicherlast kommt, untersuchen Einsatzkräfte die Vorgänge, indem sie sich die Prozesse mit dem höchsten CPU- und Speicherverbrauch ansehen. In diesem Fall sind daher die Prozessnamen oder -IDs und der damit verbundene Rechenleistungsverbrauch die „Diagnosedaten“.
Nachdem wir nun die automatische Diagnose definiert haben, warum sollte es dich interessieren? Denn durch die Implementierung eines Verfahrens zur automatischen Diagnose können die Kosten von Vorfällen gesenkt werden, da die Vorfalldauer verkürzt wird und weniger Helfer angefragt werden.
Das Problem mit MTTR
Vielleicht ist „Problem“ hier das falsche Wort, aber hören Sie mich an: MTTR ist als Kennzahl zu allgemein, um detaillierte, umsetzbare Erkenntnisse zu liefern . Die mittlere Reparaturzeit (MTTR) ist seit Jahrzehnten eine grundlegende Wartungsmetrik im IT-Universum. Und obwohl sie viele Anwendungen hat und die allgemeine Wiederherstellungsrate hervorragend erklärt, ist ihre Achillesferse genau das – die Allgemeingültigkeit. Und jetzt, da wir sicher davon ausgehen können, dass 50 % von Da die Zeit, die ein Helfer damit verbringt, zu entscheiden, wer am besten für zusätzliche Unterstützung hinzugezogen werden sollte, haben wir begonnen, andere Kennzahlen innerhalb der MTTR-Zeitleiste zu berücksichtigen, wie etwa MTTT (mittlere Zeit bis zur Triage) oder MTTI (mittlere Zeit bis zur Untersuchung).
MTTI/MTTT : Die durchschnittliche Zeit zwischen der Erkennung eines IT-Vorfalls und dem Zeitpunkt, an dem die Organisation mit der Untersuchung seiner Ursache und Lösung beginnt. Dies bezeichnet die Zeit zwischen MTTD (mittlere Zeit bis zur Erkennung) und dem Beginn von MTTR (mittlere Zeit bis zur Reparatur).
Bei PagerDuty messen wir dies als die Zeitspanne zwischen der „Bestätigung“ Ihres Ersthelfers und der „Bestätigung“ Ihres Resolvers. Diese Kennzahl hilft uns dabei, herauszufinden, was während eines Vorfalls tatsächlich unter der Oberfläche passiert. Nach der Beobachtung unserer eigenen Daten konnten wir schlussfolgern, dass MTTI einer der zeitaufwändigsten Faktoren von MTTR ist. Und wenn in modernen Unternehmen eine Aufgabe Zeit und Aufmerksamkeit von Ingenieuren erfordert, ist diese Aufgabe für das Unternehmen kostspielig. Wirklich teuer.
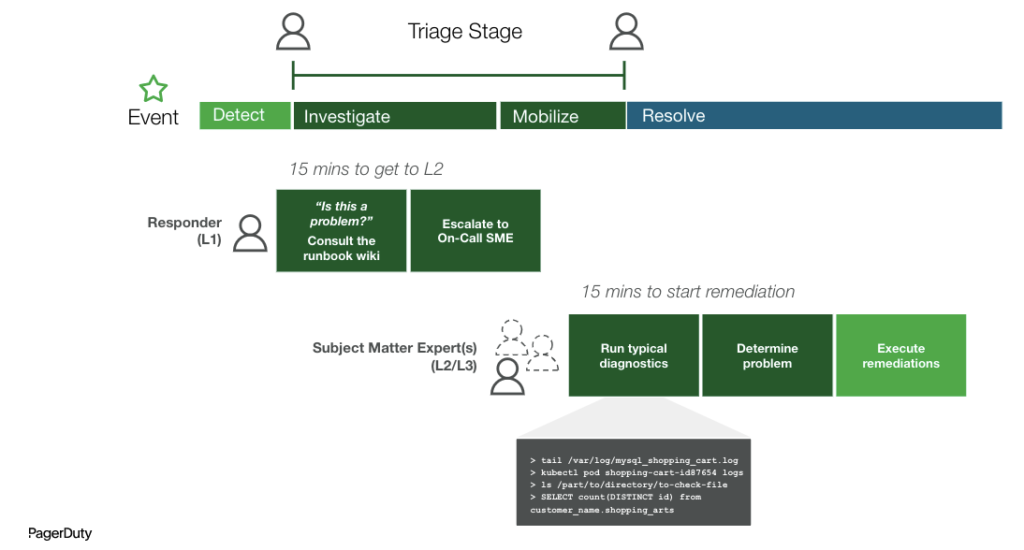
Verwenden der automatisierten Diagnose
Kommen wir nun zurück zu MTTI und automatisierter Diagnose. MTTI wird nicht nur durch die technischen Aufgaben der Einsatzkräfte verlängert, die manuell Diagnosedaten abrufen und herausfinden müssen, an welches Team sie sich bei x-Dienst und y-Vorfall wenden müssen. Es geht auch um die Menschen und ihre Einschränkungen, je nach der spezifischen Expertise, die zur Lösungsfindung erforderlich ist. In vielen Fällen weiß der Ersthelfer beispielsweise nicht, wie er das Problem aus der Datenbank- oder Netzwerkperspektive untersuchen soll. Das kann an fehlenden Fähigkeiten (Hintergrund in Datenbanken oder Netzwerken), Zugriffsproblemen oder Stammeswissen liegen (z. B. dass eine bestimmte App-Komponente von einer komplexen Integration mit einem Drittanbieterdienst abhängt).
Durch die Automatisierung dieser Untersuchungs- und Fehlerbehebungsaufgaben und die Möglichkeit, diese Aktionen an Teams und Einsatzkräfte zu delegieren, erzielen Sie einen positiven Kaskadeneffekt auf MTTI und schließlich MTTR.
Warum also sollten Sie sich für die automatisierte Diagnose interessieren?
Mithilfe der automatisierten Diagnose können Sie:
- Reduzieren Eskalationen an die wenigen Experten durch die Entwicklung von Wegen, um den Ersthelfern Informationen bereitzustellen, die normalerweise manuell erfasst werden müssten
- Verteilen Fachkompetenz in allen Reaktionsteams
- Aufrufen sichere Automatisierung hinter Firewalls und VPCs
- Fehlerbehebung und schneller lösen, ohne dass eine menschliche Intervention erforderlich ist
- Verbessern die Geschwindigkeit der Einarbeitung neuer Ingenieure und die Gewährleistung optimaler Effizienz auf allen Ebenen der Incident-Response-Organisation
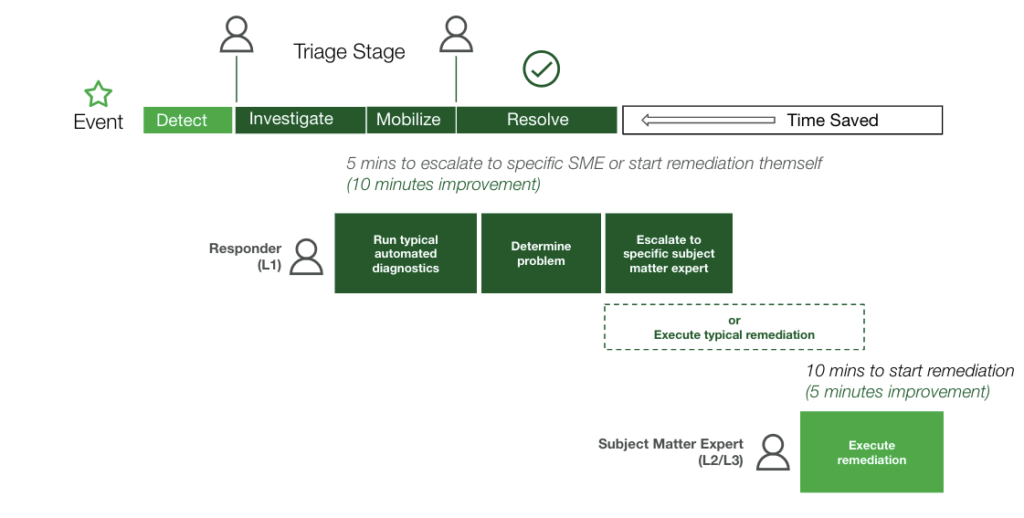
Erste Schritte
Sie haben Ihre Entscheidung getroffen. Jetzt ist es an der Zeit, den Weg zu ebnen, aber wo fangen Sie an?
Um es mit einem Marketing-Slang auszudrücken: Versuchen Sie nicht, das Meer zu übertreiben. Testen Sie einige Aktionen, die sowohl wenig komplex als auch wenig riskant sind. Das könnte ein genauerer Blick auf einige Ihrer geräuschvollsten Dienste sein, oder Sie könnten einige einfache Datenabfragen aus verschiedenen Überwachungsanwendungen, Festplattennutzung usw. ausführen. Aber es ist wichtig, eine Strategie für die langfristige Einführung und Vision dieser Funktionalität zu haben. Natürlich können Sie ein Skript schreiben, das Daten aus zahlreichen Quellen abruft und diese an einen Vorfall anhängt. Aber das ist alles andere als skalierbar.
Es ist wichtig, dass Denken Sie an die verschiedenen Infrastrukturkomponenten und Tools, aus denen Sie Diagnosedaten abrufen möchten. Sie benötigen einen standardisierten Ansatz für die Schnittstelle zu Ihren heterogenen und dynamischen Umgebungen.
Um mehr über automatisierte Diagnosen zu erfahren, schauen Sie sich einige unserer How-to-Artikel , die wir das ganze Jahr über veröffentlichen werden. Außerdem können Sie sich auf eine Sitzung von Jake Cohen zu allen Themen rund um die automatisierte Diagnose freuen, die im PagerDuty Summit nächste Woche !
Weitere Informationen zum Prozessautomatisierungsportfolio von PagerDuty finden Sie unter Besuchen Sie diese Seite Und Kontaktieren Sie Ihren Account Manager Heute.
Haben Sie Fragen? Stellen Sie sie gerne auf Twitter @sordnam

