
Rétrospective APAC, partie 2 : Mobiliser : du signal à l'action
par David Ridge
4 janvier 2024 | 7 minutes de lecture
Poursuivons notre série sur Enseignements de la région Asie-Pacifique en 2023 , il est de plus en plus évident que les incidents dans les organisations ne sont pas une question de « si » mais de « quand », quelle que soit leur taille ou leur secteur d'activité.
Récemment, la région APAC a vu les organismes de réglementation prendre des mesures plus strictes à l'encontre des grandes entreprises pour des services de qualité inférieure. , ce qui entraîne des pénalités importantes. Outre la perte immédiate de revenus et de confiance des clients, ces organisations sont désormais confrontées à des conséquences financières et opérationnelles importantes.
Les entreprises sont aujourd’hui confrontées à un large éventail de problèmes, allant des défaillances techniques majeures aux interruptions de services cloud et aux menaces de cybersécurité. Les entreprises doivent être en état d'alerte et de préparation constant. Dans cette deuxième partie de notre série de blogs, nous explorerons plus en détail les étapes critiques du cycle de vie d'un incident, en mettant l'accent sur la manière dont les organisations peuvent se préparer à l'inévitable : leur prochain incident.

Partie 2 : Mobilisation : du signal à l'action
TL;DR La gestion des incidents exige que les organisations répondent aux divers besoins des parties prenantes. La mise en œuvre de systèmes de gestion des astreintes automatisés et conviviaux est essentielle pour réduire le temps moyen d'accusé de réception (MTTA) et accélérer les réponses initiales. En cas d'incident majeur, La mobilisation simultanée de groupes d'intervenants ciblés garantit une efficacité temporelle au moment le plus important. De plus, la rationalisation des mises à jour de l'état des incidents avec des détails appropriés pour chaque personne améliore l'efficacité de la communication, permettant à l'organisation de gérer le récit et de tenir toutes les parties informées de manière fiable.
Selon un rapport et enquête récents menés par EMA Research , la plupart des répondants estiment que les pannes informatiques et les incidents importants augmentent (40 %) ou restent à peu près identiques (27 %). Cependant, 15 % des participants ont reconnu avoir constaté une augmentation, mais affirment qu'ils « peuvent réduire l'impact grâce à l'AIOps et à l'automatisation ». Selon le rapport, avec le coût croissant et la généralisation des pannes imprévues, les organisations ne peuvent pas se permettre d'adopter des solutions et des processus de gestion des incidents « suffisamment bons » pour gérer leurs opérations.
Même si nous aimerions pouvoir nous débarrasser des incidents grâce à l’automatisation et à l’IA, les personnes seront toujours au centre de la gestion des incidents. De par leur nature même, les incidents sont des tâches non planifiées que nous n’avons pas prévues ou prises en compte et qui (du moins en dehors des problèmes connus) nécessitent la mobilisation de personnes capables de contribuer à les gérer et à les résoudre. En fonction de l’impact et de la gravité de l’incident, la taille du groupe requis peut changer radicalement. Qu’il s’agisse d’appeler l’ingénieur d’astreinte qui crée et exécute sa propre application, le cadre ITIL classique de niveau 1, 2, 3+ ou un incident majeur géré de manière centralisée avec une équipe de dizaines de personnes, informer les bonnes personnes d’un incident et leur faire réagir peut souvent être la plus grande source de perte de temps dans le cycle de vie.
Concevoir le chemin de moindre résistance
La première cause de cette perte de temps ? Les gens.
Plus précisément, les processus manuels et les dossiers obsolètes. Lorsqu'ils sont laissés à eux-mêmes, les gens vont souvent Choisissez la solution de moindre résistance : le cerveau humain est programmé pour cela. Dans ce scénario, il suffit d'appeler manuellement la personne que vous connaissez, ou la personne qui a réglé le problème la dernière fois, ou même simplement le responsable de l'équipe et de les laisser décider qui appeler. Cela peut sembler être la solution la plus rapide et la plus simple pour mobiliser une réponse, mais c'est une victoire à court terme qui s'effondrera à la moindre tension et complexité.
-
- Quelle équipe possède le système affecté ?
- Qui est actuellement de garde dans cette équipe ?
- Que se passe-t-il s'ils ne répondent pas ?
- Combien de temps attendez-vous ?
- Qui d’autre devriez-vous appeler ?
- Et s'ils sont en congé ?
- Est-ce que quelqu’un d’autre devrait être mis au courant ?
Toutes ces questions nécessitent du temps pour y répondre et des étapes à exécuter manuellement.
Même si ces processus sont en place, les employés ont besoin de flexibilité. Ils partent en congé, tombent malades ou ont des urgences personnelles qui les rendent indisponibles à court terme. Ces événements quotidiens sont des choses simples qui mettent à rude épreuve une approche manuelle ou basée sur des feuilles de calcul pour la gestion des astreintes.
Fondamentalement, pour qu’un processus centré sur l’humain fonctionne, nous devons nous assurer que le chemin de moindre résistance est également la bonne chose à suivre.
Les organisations modernes ont besoin d'une solution automatisée pour mobiliser la réponse appropriée à un incident. Ce système doit être conscient du modèle de propriété du service au sein de l'organisation, mais également suffisamment flexible pour faire face au rayon d'explosion en constante évolution de l'incident. En outre, il doit s'adapter aux personnes qui utilisez-le, avec un changement facile des points de contact, des escalades automatisées et plusieurs modes de communication.
Ces exigences sont encore plus cruciales pour l’entreprise en cas d’incident majeur que pour réveiller un ingénieur DevOps à 2 heures du matin. Sans solution automatisée, les responsables des incidents majeurs doivent suivre ce processus pour chaque représentant de l’équipe concernée. Et comme nous l’avons vu à plusieurs reprises au cours de l’année écoulée, le temps est un facteur essentiel. Il est essentiel de réunir les bonnes personnes le plus rapidement possible pour lancer le processus de réponse aux incidents dans les premières minutes d’un incident. Être capable d’anticiper une panne potentielle avant qu’elle n’ait d’impact sur le client peut souvent faire la différence entre une journée normale d’exploitation et une nouvelle qui fait la une des journaux du matin.
Par conséquent, disposer de scénarios prédéfinis ou de flux de travail automatisés spécifiques au système qui peuvent être déclenchés lors de la déclaration d'un incident majeur peut transformer les 30 premières minutes d’un incident en 30 premières secondes.
Pas de nouvelles, mauvaises nouvelles
L’une des leçons à tirer de l’année écoulée est que le silence ne se termine pas toujours bien. Il est indispensable de tenir régulièrement les différents groupes de parties prenantes informés. Sans cela, les parties prenantes cherchent leurs propres mises à jour et le canal officiel perd le contrôle du récit. Spéculations et histoires parallèles devenir la dernière mise à jour, et la perception de l’incident peut devenir plus grande que l’incident lui-même.
UN La clé de la gestion du récit de l'incident réside dans une communication simplifiée avec les parties prenantes, c'est-à-dire la possibilité de disposer de canaux de communication personnalisés pour les parties prenantes internes et externes. Les parties prenantes doivent avoir la possibilité de s'abonner aux systèmes et services qui les intéressent (elles peuvent également recevoir des notifications !), mais les gestionnaires d'incidents doivent également avoir la possibilité de transmettre une mise à jour à toute personne qui, selon eux, doit en être informée.
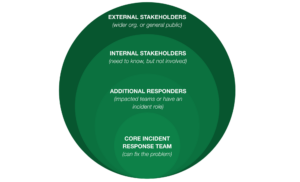
C'est là qu'entrent en jeu nos cercles de communication toujours plus nombreux. Différentes parties prenantes peuvent exiger différents niveaux de détail. Certains termes internes et noms de système peuvent ne pas être traduits en externe. De même, une mise à jour d'un canal Slack ou Teams peut ne pas être appropriée pour l'e-mail hautement formaté et structuré qui est envoyé à l'équipe de direction.
Les modèles de communication basés sur les personnages peuvent remplir automatiquement les données statiques répétables, mais aussi utiliser l'IA générative pour créer une mise à jour de statut appropriée pour approbation. Ils peuvent aider les organisations modernes à réduire le travail des gestionnaires d'incidents majeurs afin qu'ils puissent se concentrer sur la restauration du service. De plus, le fait que cette mise à jour soit automatiquement envoyée directement à un spécialiste des communications externes, qui peut l'adapter et l'approuver pour les parties prenantes externes et/ou le grand public via des mises à jour de la page d'état externe, est un moyen de garantir que les communications sur les incidents sont cohérentes et régulières.
En résumé, il est important pour les organisations de comprendre les besoins des différents groupes en matière de notifications et de communications d’incidents. Disposer d’un système automatisé et convivial de gestion des astreintes peut réduire considérablement le temps moyen d’accusé de réception (MTTA) pour les premiers intervenants. En étendant cette méthode pour mobiliser simultanément plusieurs groupes ciblés d’intervenants lors d’incidents majeurs, on peut s’assurer de ne pas perdre un temps précieux au moment le plus important. Enfin, en rationalisant les mises à jour du statut des incidents afin que chaque personne obtienne le niveau de détail approprié, l’organisation pourra gérer le récit et tenir tout le monde informé de manière fiable.
Un regard vers l'avenir
Dans la partie 3 : Triage, je vais me plonger dans les différentes tâches, actions et manuels d'exécution qui sont utilisés lors d'un incident pour voir comment les organisations peuvent démocratiser en toute sécurité leurs connaissances tribales et permettre aux équipes de niveau 1 et aux ingénieurs juniors de réduire la taille et la durée d'un incident. Nous examinerons également certaines façons de rationaliser le processus d'incident en automatisant complètement certains des manuels d'exécution.
Vous voulez en savoir plus ?
Nous serons également Nous organisons une série de webinaires en trois parties qui se concentre sur le compte de résultat et sur la façon dont il a aidé les clients à se concentrer sur la croissance et l'innovation. Cliquez sur les liens ci-dessous pour en savoir plus et vous inscrire :
- 7 février 2024 : Partie 1 : Optimisation de la gestion des incidents : accroître la productivité pour un meilleur retour sur investissement
- 21 février 2024 : Partie 2 : Remodelage et optimisation de la réponse aux incidents avec l'IA et l'automatisation
- 26 au 29 février 2024 : PagerDuty101 (Les inscriptions ouvriront bientôt)

