
Rétrospective APAC : les enseignements d'une année de turbulences technologiques
par David Ridge
18 décembre 2023 | 6 minutes de lecture
Tout au long de l’année 2023, une chose est devenue évidente : quelle que soit la taille ou le secteur d’activité d’une organisation, les incidents sont inévitables.
Récemment, dans la région Asie-Pacifique, de nombreux organismes de réglementation ont pris des mesures sévères contre les grandes entreprises qui ne fournissent pas un service acceptable, certaines d'entre elles infligeant des sanctions assez sévères. Pour beaucoup, le coût d'un incident ne se résume plus seulement à une perte de revenus et de confiance des clients, mais également à des sanctions financières et à des restrictions commerciales.
Qu'elles soient confrontées à des pannes techniques importantes, à des interruptions des services cloud ou à des menaces de cybersécurité, les entreprises modernes doivent planifier et se préparer de manière proactive aux incidents potentiels.
Dans cette série de blogs, nous examinerons les cinq étapes du cycle de vie d'un incident, offrant un aperçu de ce que les organisations doivent faire pour garantir leur préparation à l'inévitable… leur prochain incident.

——————————–
Partie 1 : Détecter : filtrer le bruit
Au milieu de tout le chaos causé par les pannes et les incidents récents de cette année, nous parierions que quelque part dans tout ce bruit se trouvait l’alerte qui comptait vraiment.
L'observabilité est un élément fondamental de tout système résilient. Bien qu'il soit issu des capacités de surveillance traditionnelles, le terme a considérablement évolué à mesure que les systèmes gagnent en complexité, offrant une vue améliorée des processus métier et des parcours clients. Comprendre les performances de votre entreprise sur des périodes et des charges de travail variables est essentiel non seulement pour l'excellence opérationnelle, mais aussi pour favoriser la croissance de l'entreprise.
Cependant, une surveillance complète a un prix. Avec la baisse du coût de la collecte de données, les applications de surveillance collectent désormais de plus en plus de données. C'est une bonne chose pour l'analyse, mais le problème réside dans le fait que les alertes augmentent au même rythme exponentiel. Les gens deviennent insensibles aux alertes, ce qui les rend moins efficaces.
De nombreuses organisations sont noyées dans le bruit des centaines de mesures générées chaque minute par leurs différentes suites d'outils d'observabilité. Avec une complexité accrue et de vastes dépendances, les étoiles de la mort (nous vous regardons, microservices !), les chances d'être alerté de quelque chose qui se trouve en amont et hors de votre contrôle sont de plus en plus élevées. Alors, comment pouvons-nous résoudre ce problème ?
À un moment donné, chacune de ces nombreuses alertes sera utile et exploitable, nous ne pouvons donc pas simplement désactiver arbitrairement 30 % de nos alertes pour obtenir une réduction du bruit de 30 % ; nous avons besoin d'une vue holistique et nous avons besoin de contexte.
Toutes les alertes ne sont pas égales… cela dépend.
Pour comprendre vos alertes, vous devez comprendre vos systèmes.
Tous les services ne sont pas créés égaux, donc lorsqu'une alerte se déclenche, vous devez réagir avec une réponse appropriée.
Quelle est la réponse appropriée ? Eh bien, cela dépend…
- Quel service est concerné ?
- Quelle heure est-il?
- Ce service offre-t-il une assistance 24h/24 et 7j/7 ou uniquement pendant les heures ouvrables ?
- Quelle est la gravité de l'alerte ?
- De quel type d’alerte s’agit-il ?
- Est-ce quelque chose que je peux supprimer ?
- Avons-nous déjà signalé un incident à ce sujet ?
- Combien de fois cela est-il déjà arrivé ?
- Est-ce lié à autre chose ?
- Est-ce que quelque chose a changé récemment ?
- Est-ce qu’une personne est vraiment nécessaire ?
- est-ce un problème connu?
- Est-ce que le problème se résoudra automatiquement en 2 minutes comme toujours ?
- Pouvons-nous y remédier automatiquement ?
Si vous avez la même politique et le même mécanisme d'alerte pour toutes les alertes et que vous n'avez pas de moyen de filtrer les alertes exploitables et importantes de celles qui ne nécessitent pas une attention immédiate, les personnes qui les reçoivent finiront par se lasser des alertes et se désintéresseront, ne répondant que lorsque l'équipe de gestion des incidents majeurs viendra les appeler.
La réalité est que les entreprises modernes ne peuvent plus se permettre de laisser cette tâche aux mains de la gestion manuelle des événements et des files d'attente de billetterie. Elles ont besoin d'une solution automatisée capable de gérer l'échelle et la complexité des grands systèmes modernes et de garantir que les bons filtres sont en place pour acheminer et corréler les alertes pertinentes, avec la réponse appropriée, à la bonne personne, en quelques secondes.
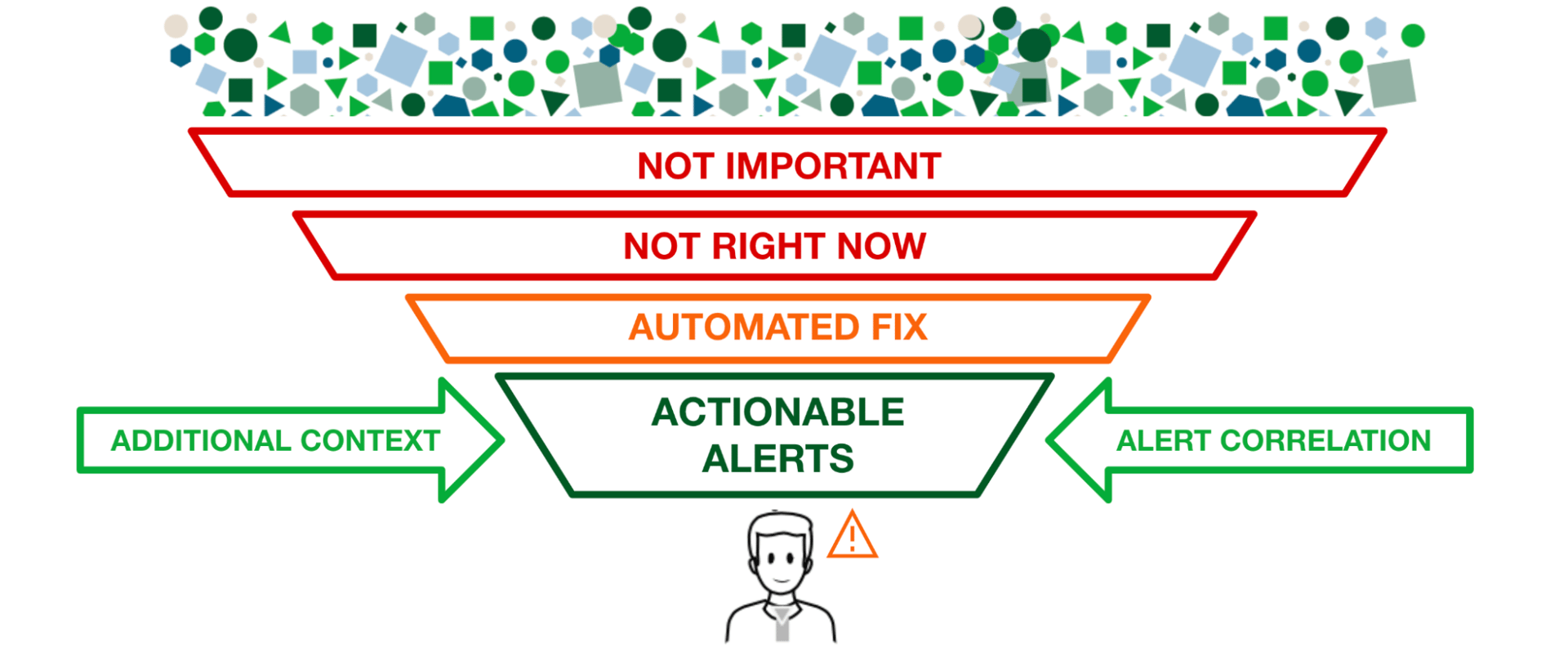
Le contexte et la pertinence sont essentiels à la gestion des alertes.
L’évolution de la gestion des événements de base vers l’AIOps moderne a apporté avec elle un nouvel ensemble de fonctionnalités qui permettent aux organisations de comprendre leurs alertes dans le contexte d’un ensemble de données en constante augmentation. Les algorithmes d’apprentissage automatique peuvent comprendre si une alerte est en fait une anomalie en fonction des modèles historiques, ainsi que la fréquence à laquelle cette même alerte se produit. De même, une vue holistique de toutes les alertes et incidents pertinents et actifs, enrichie du contexte de leurs dépendances, peut ajouter une perspective bien nécessaire à une alerte unique, montrant potentiellement une défaillance en cascade à partir d’une origine probable ou une défaillance de dépendance directe.
Que vous soyez un ingénieur DevOps unique d'astreinte pour votre propre application, un ingénieur de support de niveau 1 chargé d'évaluer les alertes de plusieurs systèmes ou un gestionnaire d'incidents majeurs essayant d'évaluer le rayon d'action d'un changement ayant échoué, avoir un contexte immédiat sur ce qui se passe d'autre dans l'organisation et sur ceux qui sont spécifiquement pertinents pour votre incident peut vous faire gagner des minutes cruciales (voire des heures) au début d'un incident pour vous assurer de vous concentrer sur les bons signaux et de ne pas vous laisser égarer par des faux positifs.
L’objectif des organisations est de passer d’un processus réactif à un processus proactif et, idéalement, à un processus préventif. Cependant, cela nécessite de modifier la réponse aux incidents, en passant des incidents majeurs ayant un impact connu sur le client, à la réponse aux principaux indicateurs de défaillance ou de dégradation des performances et à la résolution du problème avant même qu’il n’y ait un impact sur le client. Cela ne peut être accompli qu’avec une certaine forme de renseignement ou de capacité AIOps pour comprendre les éléments plus larges impliqués, fournir un contexte pertinent immédiat et, en fin de compte, filtrer le bruit.
Dans la deuxième partie : Mobiliser, nous verrons comment les organisations peuvent optimiser l'élément de réponse humaine du cycle de vie des incidents. Des premiers intervenants et des gestionnaires d'incidents majeurs jusqu'aux parties prenantes de l'entreprise et même au public, nous examinerons en détail ce qui est requis à chaque niveau de communication sur les incidents.
Vous souhaitez en savoir plus ?
Nous organiserons également une série de webinaires en 3 étapes. Ces webinaires porteront sur le P&L et sur la manière dont il a aidé les clients à se concentrer sur la croissance et l'innovation. Cliquez ci-dessous pour en savoir plus et vous inscrire :
7 février 2024 : Partie 1 : Optimisation de la gestion des incidents : accroître la productivité pour un meilleur retour sur investissement
21 février 2024 : Partie 2 : Remodelage et optimisation de la réponse aux incidents avec l'IA et l'automatisation
26 au 29 février 2024 : PagerDuty101 (Les inscriptions ouvriront bientôt)

