
- PagerDuty /
- Blog /
- Automatisation /
- Capture d'état de débogage pour les infrastructures et applications traditionnelles
Blog
Capture d'état de débogage pour les infrastructures et applications traditionnelles
par Justin Roberts
25 mai 2023 | 5 minutes de lecture
Dans nos blogs précédents sur Capture de l'état de l'application et en utilisant Conteneurs éphémères pour le débogage de Kubernetes , nous avons discuté de l’intérêt de pouvoir déployer des outils spécifiques pour recueillir des diagnostics en vue d’une analyse ultérieure, tout en fournissant à l’intervenant en cas d’incident les moyens de résoudre les problèmes d’infrastructure ou d’application.
Cela crée un équilibre entre la nécessité de restaurer un service le plus rapidement possible, en plus de garantir que suffisamment de données de débogage sont disponibles pour une résolution permanente ultérieure, tout en permettant à une équipe de développement de maintenir un conteneur en fonctionnement léger et performant.
En capturant à la fois l'état de l'application et de l'environnement lorsque l'incident se produit, tout intervenant ou propriétaire de service passe moins de temps à basculer entre les outils, les informations d'identification et les environnements, ce qui permet des réponses et une résolution des problèmes plus précises et plus rapides.
Les techniques abordées dans les blogs précédents de cette série se concentraient sur les plateformes cloud natives modernes comme Kubernetes et sur les approches uniques nécessaires aux conteneurs, en particulier les conteneurs qui ne sont pas livrés nativement avec des outils de débogage.
Tout le monde n’est pas capable ou disposé à déplacer toutes ses applications vers le cloud natif, et beaucoup d’entre nous travaillent encore dans un scénario hybride d’applications conteneurisées et traditionnelles.
Même sans la nature éphémère des conteneurs et les politiques strictes relatives aux images de conteneurs, il est toujours nécessaire de capturer des preuves instantanées pour aider à l'analyse des causes profondes afin d'éviter de futures occurrences d'incidents.
Examinons des cas d’utilisation décrivant la capacité à capturer automatiquement l’état en cas de panne ou de diminution des performances, et choisissons quelques scénarios intéressants dans lesquels approfondir notre analyse.
Il s’agit d’une liste non exhaustive, mais voici quelques exemples de la manière dont la capture d’état de débogage est utilisée dans les environnements d’application traditionnels :
Infrastructure et réseau
- Processus les plus consommateurs de ressources sur un ou plusieurs composants d'infrastructure
- Vidage TCP ; vidage thread/mémoire/core
Base de données
- Requêtes les plus consommatrices de ressources
- État actuel de la requête
- Exécution de requêtes spécifiques à l'application
Spécifique à l'application
- Java – Exécutez un vidage de thread/de tas avec des outils comme jstack
- Windows – Vidage de procédure
- Python – Exécution d'un vidage de thread
- Tous – Fichiers journaux spécifiques à l’application
Fichiers journaux supplémentaires
La capture de l'état de débogage peut récupérer des journaux entiers ou partiels à partir de n'importe quel fichier qui peut ne pas être capturé par un agrégateur de journaux.
PagerDuty Process Automation fournit de nombreux modèles de flux de travail prédéfinis pour capturer l'état de l'application et de l'environnement dans le cadre de projet de diagnostic automatisé Ces flux de travail sont flexibles et extensibles afin qu'ils puissent être personnalisés pour fonctionner dans des cas d'utilisation particuliers.
Plonger plus profondément
Examinons de plus près quelques exemples spécifiques de capture de l’état de l’environnement qui pourraient s’avérer utiles pour identifier la solution à long terme en cas d’incident.
Cas d'utilisation 1 – Rassembler les données de débogage de la base de données
Nous pouvons utiliser l'étape SQL RUN dans l'automatisation des processus pour ajouter une instruction en ligne ou exécuter un script existant. Comme mon application est MariaDB (un fork de MySQL), je peux utiliser les paramètres suivants pour exécuter la requête MySQL :
AFFICHER LA LISTE COMPLÈTE DES PROCESSUS ;
( Note : les informations d'identification proviennent de mon magasin externe existant et sont transmises en toute sécurité lorsque j'exécute l'étape dans le cadre d'un flux de travail, afin que je puisse déléguer en toute sécurité sans exposer d'informations)

Je transmets la sortie à ma plateforme d'incident (dans mon cas, PagerDuty, bien sûr) et je configure le travail pour qu'il collecte automatiquement si un incident se produit dans le service de base de données.

Ces informations sont désormais automatiquement disponibles pour mon intervenant dans son application, son outil Chatops ou dans n'importe quelle analyse post-mortem. Dans ce cas, je peux voir que quelqu'un exécute un test d'évaluation au moment de l'incident ! Comme pour les articles de blog précédents, il serait également facile de publier des versions plus complexes de ces informations dans un environnement de stockage comme un compartiment AWS S3 pour une analyse ultérieure.
Cas d'utilisation 2 – Rassembler les données de débogage de l'application
Mon outil d'observabilité me permet très rapidement de savoir QUAND une application a échoué, mais pas toujours d'indiquer POURQUOI elle a échoué. Ce deuxième cas d'utilisation exécutera une commande ad hoc pour mon application Python afin d'utiliser py-spy, un profileur d'échantillonnage pour mon application, en conjonction avec l'un de nos plugins d'automatisation pour déplacer les fichiers en toute sécurité vers S3 pour une récupération ultérieure.
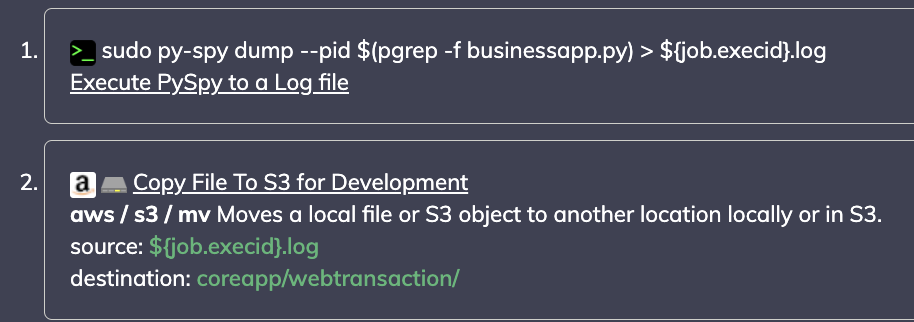
Sortie des données directement vers mon stockage S3 :

Cet exemple met en évidence les états de travail de mon application Python au niveau du thread, directement entre les mains de mon développeur, et stocké aussi longtemps qu'il pourrait être nécessaire de s'y référer.
Bien sûr, ces commandes ne sont pas exclusives, et je pourrais facilement enchaîner plusieurs vérifications pour offrir une vue plus large.
Cas d'utilisation 3 – Capture de l'état de débogage de l'infrastructure traditionnelle
Pour le troisième cas d'utilisation, je dois déployer un ensemble de commandes bash sur une machine distante et les exécuter à nouveau lors de l'événement déclencheur. Cela fait principalement apparaître des diagnostics tels que les fichiers ouverts et les connexions réseau, mais cela exécute également bpftrace , un outil qui peut être utilisé pour tracer des appels spécifiques :
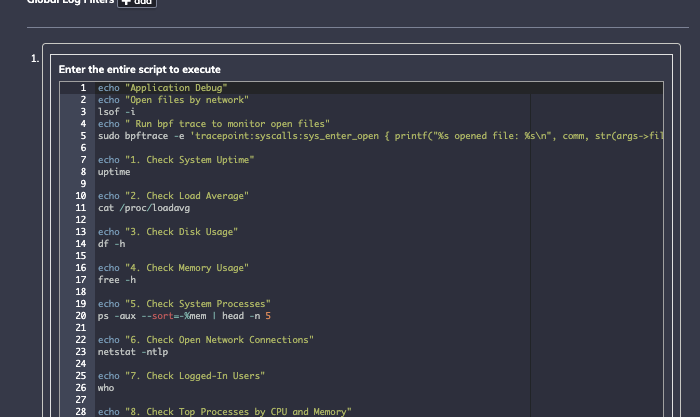
L'automatisation des processus me permet de définir et de déployer un script complet et de stocker la sortie pour recueillir un instantané de l'état de mon environnement :
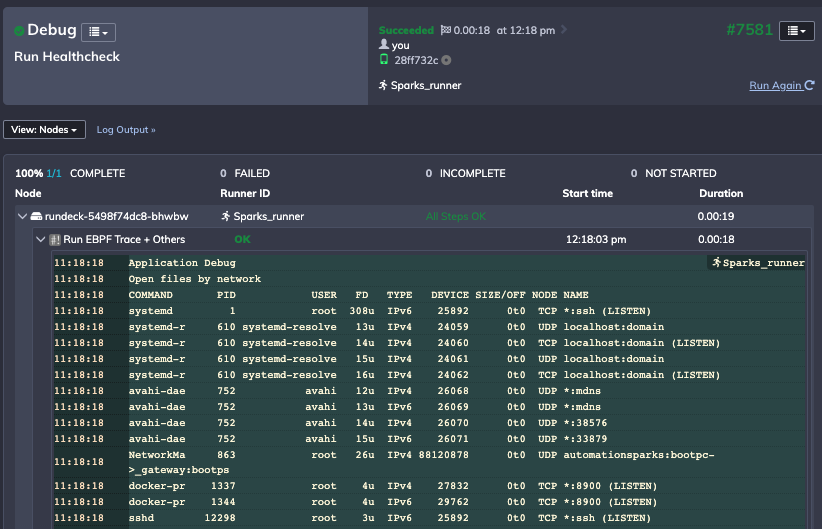
Conclusion
Les signaux provenant des outils de surveillance, même dans les environnements traditionnels, bénéficient d'une visibilité plus large pour permettre à tout intervenant, ingénieur DevOps ou SRE, de prendre des décisions rapides et sûres. Les développeurs ont également souvent besoin d'informations supplémentaires et de la capacité de capturer l'état lorsque des problèmes surviennent, car ils peuvent ne pas être disponibles immédiatement.
Debug State Capture permet cela, en fournissant un contexte supplémentaire pour un intervenant, en réduisant le temps passé à fouiller dans différents outils et en offrant la possibilité de collecter des ensembles de données plus approfondis pour une analyse ultérieure.
Vous souhaitez en savoir plus ? Commencez dès aujourd'hui avec un essai de Automatisation du livre d'exécution .

