
Vendredi échec : comment nous garantissons la fiabilité de PagerDuty
par Kenneth Rose
20 novembre 2013 | 7 minutes de lecture
Demandez à n'importe quel PagerDutonien quelle est l'exigence la plus importante de notre service et vous obtiendrez la même réponse : la fiabilité. Nos clients comptent sur nous pour les alerter lorsque leurs systèmes rencontrent des problèmes ; à temps, à chaque fois, de jour comme de nuit.
Notre code est déployé sur 3 centres de données et 2 fournisseurs de cloud pour garantir que toutes les alertes téléphoniques, SMS, notifications push et e-mail sont envoyées. Les chemins critiques de notre code ont des sauvegardes ; et notre code a des sauvegardes pour les sauvegardes. Cette triple redondance garantit que personne ne s'endort pendant une alerte, ne manque un SMS ou ne reçoit pas d'e-mail.
Nous avons besoin de plus qu’une conception tolérante aux pannes
Bien qu'une conception tolérante aux pannes soit une bonne chose, des problèmes de mise en œuvre peuvent parfois empêcher ces conceptions de fonctionner comme prévu. Par exemple, les sauvegardes qui ne se déclenchent qu'en cas de panne peuvent cacher des bugs ou du code qui fonctionne parfaitement dans un environnement de test mais qui échoue lorsqu'il est exposé à une charge de production. L'hébergement cloud nous oblige à prévoir la défaillance de notre infrastructure à tout moment.
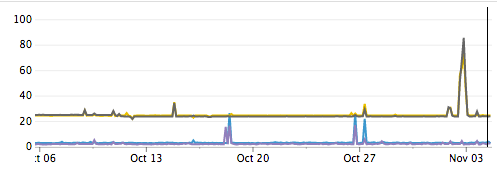
Internet lui-même est une source de défaillances. Nous constatons régulièrement une augmentation spectaculaire de la latence et de la perte de paquets entre les centres de données. Certains de ces événements peuvent être attribués à des problèmes connus comme les attaques DDoS, mais d'autres causes sont inconnues. Dans les deux cas, nous ne pouvons rien faire contre ces événements, à part les contourner.
Latence entre centres de données en millisecondes
Netflix a résolu ces problèmes grâce à son Simian Army : un ensemble d'outils automatisés qui testent la résilience des applications en cas de panne. Chaos Monkey arrête les instances, qui sont régénérées via des groupes de mise à l'échelle automatique. Latency Monkey introduit une latence artificielle dans les appels réseau. Chaos Gorilla arrête une zone de disponibilité entière. Bien que certains de ces outils soient disponibles gratuitement, ils supposent que votre application est déployée uniquement dans AWS à l'aide de groupes de mise à l'échelle automatique, tandis que la nôtre est déployée sur plusieurs fournisseurs.
Ne voulant pas nous embourber dans la production de nos propres outils équivalents, nous avons décidé d'investir dans une méthode simple. Il suffit de planifier une réunion et de le faire manuellement. Nous utilisons des commandes Linux courantes pour tous nos tests, ce qui facilite la mise en route.
Avantages du vendredi sans échec de PagerDuty
Nous avons mis en place Failure Friday ces derniers mois ici à PagerDuty. Nous avons déjà constaté un certain nombre d'avantages :
- Révèle les problèmes de mise en œuvre qui réduisent notre résilience.
- Détecte proactivement les déficiences pour éviter que ces écarts ne deviennent la cause principale d’une panne future.
- Crée une culture d'équipe solide En se réunissant en équipe une fois par semaine pour partager leurs connaissances, les équipes opérationnelles peuvent apprendre comment les équipes de développement corrigent les problèmes de production dans leurs systèmes. Les développeurs acquièrent une meilleure compréhension de la manière dont leur logiciel est déployé. Et c'est un avantage appréciable de former les nouvelles recrues à gérer les pannes à 11 heures le vendredi plutôt qu'à 3 heures le samedi.
- Cela nous rappelle que l’échec est inévitable. L'échec n'est plus considéré comme un événement anormal pouvant être ignoré ou expliqué. Tout le code écrit par les équipes d'ingénierie est désormais testé pour savoir comment il survivra pendant le Failure Friday.
Préparer notre équipe à l'échec vendredi
Avant de commencer le Vendredi des échecs, il est important que nous établissions un ordre du jour de tous les échecs que nous souhaitons introduire. Nous programmons une réunion d'une heure et travaillons sur autant de problèmes que possible.
L'injection d'une défaillance peut entraîner une défaillance plus grave que nous le souhaiterions. Il est donc important que tous les membres de votre équipe adhèrent à l'idée d'introduire une défaillance dans votre système. Pour atténuer les risques, nous veillons à ce que tous les membres de l'équipe soient informés et impliqués.
En prévision de la première attaque, nous allons désactiver toutes les tâches cron programmées pour s'exécuter pendant l'heure. L'équipe dont nous allons attaquer le service sera préparée avec des tableaux de bord pour surveiller ses systèmes pendant que la panne est injectée.
La communication est impérative pendant le Failure Friday. Chez PagerDuty, nous utiliserons une salle HipChat dédiée et une conférence téléphonique afin de pouvoir échanger des informations rapidement. Avoir une salle de discussion est particulièrement utile car elle nous donne un journal horodaté des actions entreprises, que nous pouvons corréler avec les mesures que nous capturons.
Nous gardons également nos alertes PagerDuty activées pour confirmer que nous recevons des alertes et voir à quelle vitesse elles arrivent par rapport à la panne introduite.
Introduction de l'échec dans notre système
Chaque attaque que nous lançons contre notre service dure cinq minutes. Entre chaque attaque, nous remettons toujours le service dans un état entièrement fonctionnel et confirmons que tout fonctionne correctement avant de passer à l'attaque suivante.
Pendant l'attaque, nous vérifions nos tableaux de bord pour comprendre quelles mesures indiquent le problème et comment ce problème affecte les autres systèmes. Nous gardons également une note dans notre salle de discussion indiquant quand nous avons été contactés et à quel point cette communication nous a été utile.
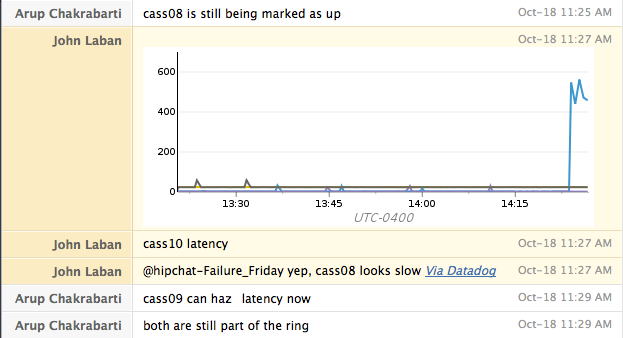
Pour chaque attaque, nous commençons par attaquer un seul hôte. Si cette attaque se comporte comme prévu, nous répétons le test sur l'ensemble d'un centre de données. Pour les services hébergés uniquement sur AWS, nous testons si un service survit à la perte d'une zone de disponibilité entière.
Attaque n°1 : Échec du processus
Notre première attaque est assez simple : nous arrêtons le service pendant 5 minutes. En général, c'est aussi simple que « sudo service cassandra stop ». Nous nous attendons à ce que le service dans son ensemble continue de traiter le trafic malgré la perte de cette capacité. Nous découvrirons également souvent si nos alarmes identifient correctement ce service comme étant indisponible. Pour le redémarrer, nous exécutons « sudo service cassandra start ».
Attaque n°2 : redémarrer les hôtes
Après avoir confirmé avec succès que nous pouvons survivre à la perte d'un seul nœud et d'un centre de données entier, nous passons au redémarrage des machines. Cette attaque confirme qu'au redémarrage, la machine démarre correctement tous les services requis. Elle nous aide également à trouver les cas où notre surveillance est liée à la machine exécutant le service, afin que nous ne soyons pas alertés lors de son arrêt.
Attaque n°3 : Isolation du réseau
Lors des deux attaques précédentes, les services ont été arrêtés proprement, puis les machines ont été redémarrées. L'attaque suivante vérifie notre résilience face à une panne inattendue. Nous bloquons la connectivité réseau via iptables. Nous abandonnons les paquets entrants et sortants. Ce test vérifie que les clients ont configuré des délais d'attente raisonnables et ne dépendent pas d'arrêts de service propres.
| sudo iptables -I ENTRÉE 1 -p tcp –dport $NUMÉRO_PORT -j SUPPRIMER |
| sudo iptables -I OUTPUT 1 -p tcp –sport $PORT_NUMERO -j DROP |
Pour réinitialiser le pare-feu une fois que nous avons terminé, nous le rechargeons simplement à partir du disque :
| sudo reconstruire-iptables |
Attaque n°4 : Lenteur du réseau
Notre dernière attaque teste la manière dont le service gère la lenteur. Nous simulons un service lent au niveau du réseau en utilisant tc.
| sudo tc qdisc add dev eth0 root netem délai 500 ms 100 ms perte 5 % |
Cette commande ajoute 400 à 600 millisecondes de retard à l'ensemble du trafic réseau. Il y a également une perte de paquets de 5 % pour faire bonne mesure. Avec cet échec, nous nous attendons généralement à une certaine dégradation des performances. Idéalement, les clients peuvent contourner le retard. Un client Cassandra, par exemple, peut choisir de communiquer avec les nœuds les plus rapides et d'éviter d'envoyer du trafic au nœud altéré. Cette attaque testera la capacité de nos tableaux de bord à identifier le nœud lent. Gardez à l'esprit que cela a également un impact sur toutes les sessions SSH en direct.
Le retard est facilement réversible.
| sudo tc qdisc del dev eth0 root netem |
Pour conclure
Une fois que nous avons terminé avec Failure Friday, nous publions un message de fin d'exécution et réactivons nos tâches cron. Notre dernière étape consiste à prendre toutes les leçons exploitables et à les attribuer à l'un des membres de notre équipe dans JIRA.
Le programme Failure Friday nous permet d'aller au-delà de la résolution des problèmes et nous aide à les empêcher de se produire. La fiabilité de PagerDuty est extrêmement importante pour nous et la participation de notre équipe au programme Failure Friday est notre façon de la maintenir.
Vous voulez en savoir plus ? Vous pouvez regarder Doug Barth donner une conférence sur Failure Friday filmée ici même au siège de PagerDuty !
4 ans plus tard
N'oubliez pas de consulter notre article de blog de suivi : « Les vendredis de l'échec : 4 ans après « pour voir comment notre processus a évolué au fil des années.

