Les vendredis de l'échec : quatre ans après
par Éric Sigler
12 juillet 2017 | 4 minutes de lecture
Le 28 juin 2017, nous avons célébré quatre ans de représentation de « Les vendredis de l'échec » chez PagerDuty. Pour récapituler rapidement, les Failure Fridays sont une pratique que nous menons chaque semaine chez PagerDuty pour injecter des défauts dans notre environnement de production de manière contrôlée et sans impact sur le client. Ils ont joué un rôle fondamental pour nous permettre de vérifier nos efforts d’ingénierie de résilience.
Au fil des années, notre processus a évolué, suivant parfois Ingénierie du chaos Des principes, parfois non. Mais la constante de Failure Friday a toujours été de nous aider à identifier et à résoudre les problèmes avant qu'ils n'affectent nos clients. Voici quelques étapes de notre parcours et certaines des leçons que nous en avons tirées :
Chronologie
2013
- Juin :Le premier vendredi d'échec !
2014
- Février : Notre premier Failure Friday axé sur la sécurité. Au lieu de tester la résilience aux pannes d'un seul service individuel via l'isolement, les redémarrages, etc., nous avons testé une variété de cas extrêmes, tels que l'envoi de données non valides aux API et une mauvaise configuration du pare-feu. Cette pratique est toujours utilisée aujourd'hui avec certains Failure Fridays réservés non pas à l'injection de pannes sur un seul service, mais plutôt à la recherche d'anti-modèles à l'échelle de l'infrastructure.
- Avril : Moins d'un an après avoir lancé Failure Fridays, nous avons simulé l'échec complet de l'un des sept Zones de disponibilité Notre infrastructure fonctionnait à l'époque. La première fois que nous avons fait cela, nous avons un peu exagéré avec notre paranoïa et l'avons simulé méticuleusement au cours de quatre sessions distinctes. Maintenant, nous le terminons généralement en une seule session environ.
2015
- Janvier :Après 18 mois et 33 sessions, nous avons finalement automatisé une grande partie des commandes manuelles du message original du Failure Friday dans Basé sur ChatOps outillage. En effectuant les étapes manuellement au début, nous les avons validées et apprises sans avoir à passer beaucoup de temps au préalable. Au fur et à mesure que notre entreprise s'est développée, il est devenu de plus en plus difficile de recruter de nouveaux collaborateurs, nous avons donc fait appel à notre bot d'entreprise :

- Janvier :Une fois que nous nous sommes sentis à l'aise avec l'idée de perdre une seule zone de disponibilité, nous avons intensifié notre jeu pour éliminer une zone entière. Région . Ces exercices nécessitent généralement quelques séances pour être terminés, car ils génèrent toujours de nouveaux apprentissages pour nous.
- Mars :Nous avons réalisé que les Vendredis de l'échec étaient une excellente occasion de faire de l'exercice notre processus de réponse aux incidents , nous avons donc commencé à l'utiliser comme terrain d'entraînement pour nos nouveaux commandants d'incident avant qu'ils n'obtiennent leur diplôme.
- Peut :Au fur et à mesure que nous avons augmenté le nombre de services et d'équipes chargées de leur maintenance, nous avons commencé à conserver une documentation plus formelle sur les pannes prévues, les listes de contrôle pour les sessions futures, les résultats des injections de pannes, etc. « Ce n'est pas de la science si vous ne l'écrivez pas. »

2016
- Avril :Une année de plus et une nouvelle série de tests de pannes à grande échelle du Failure Friday : nous avons commencé à simuler le basculement vers notre infrastructure de reprise après sinistre. En fonctionnement normal, nous validons nos outils de reprise après sinistre avec un petit pourcentage de trafic en direct, mais pendant ces scénarios, nous augmentons ce pourcentage de trafic en direct, en prenant soin de ne pas impacter nos clients.
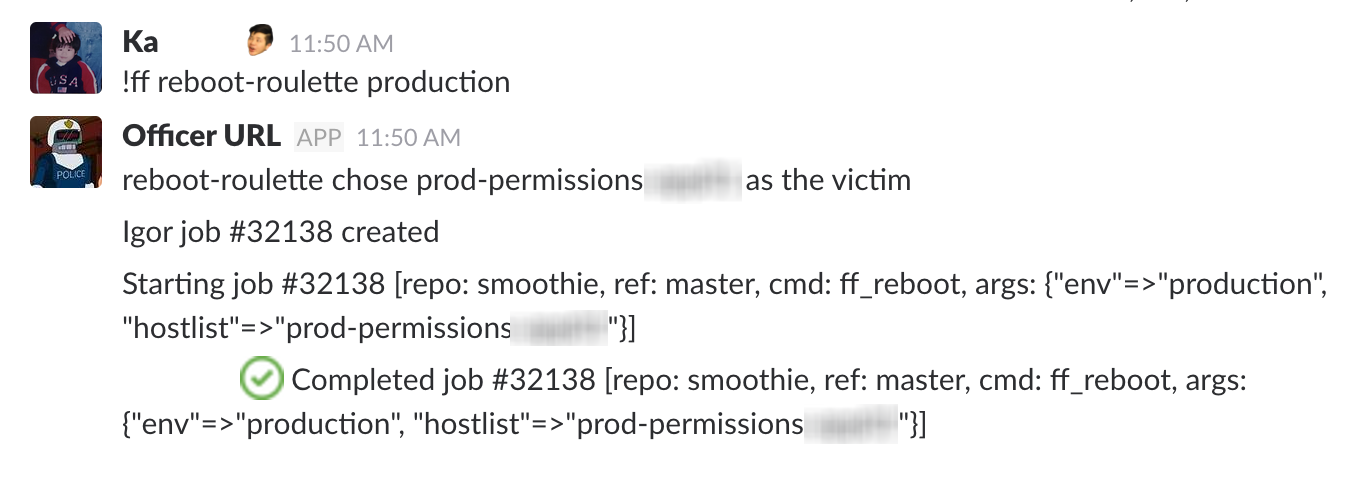
- Juin :Nous avons introduit « Reboot Roulette » dans notre suite d'automatisation, en sélectionnant aléatoirement les hôtes (avec pondération pour différentes catégories d'hôtes) à injecter avec une erreur (le redémarrage était la première erreur parmi plusieurs ajoutées, à cause de l'allitération bien sûr).
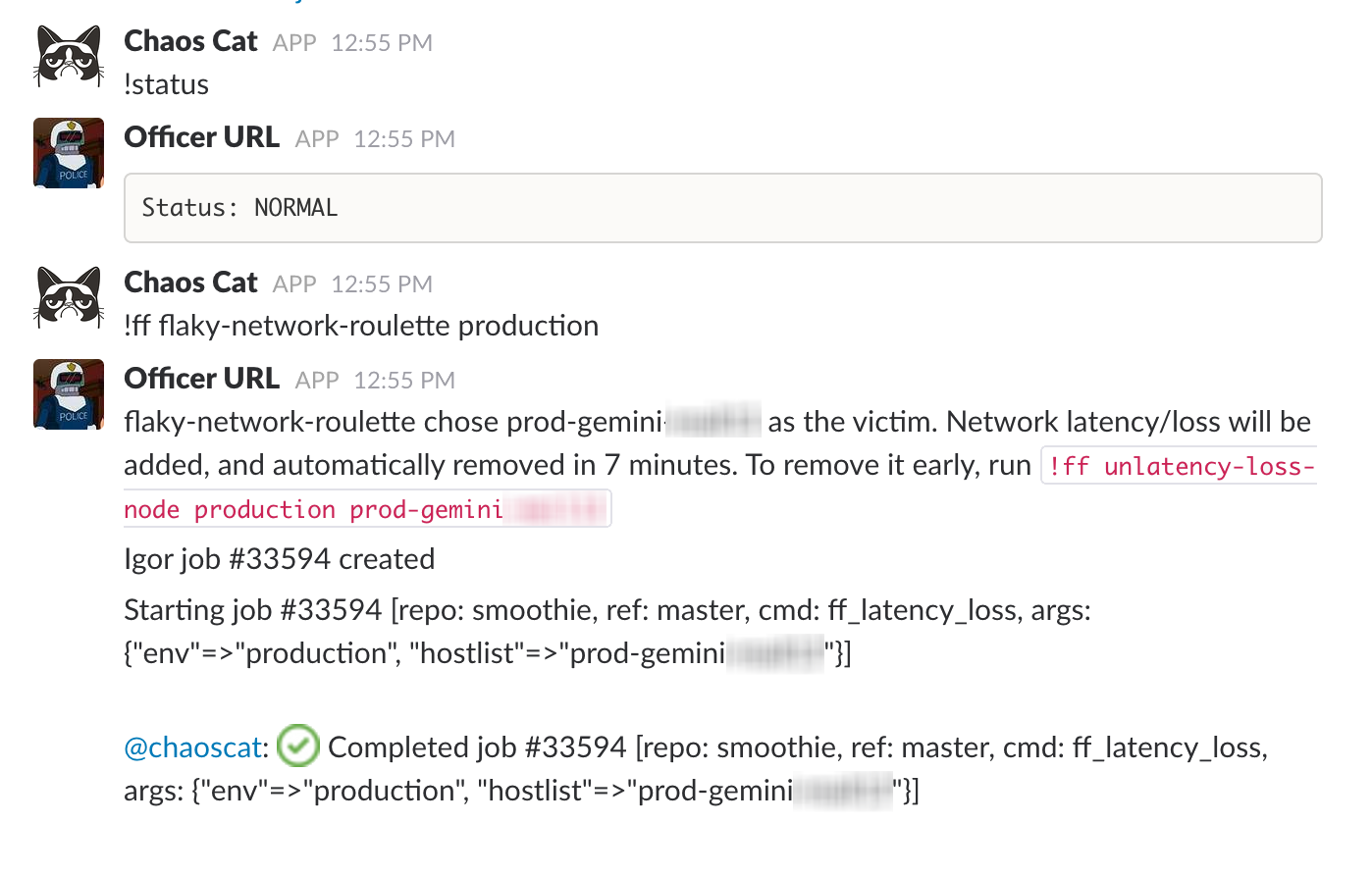
- Septembre :Lors d'un Hackday, Chaos Cat est introduit , en utilisant tous les outils existants pour automatiser l'injection de pannes (à un moment différent de notre fenêtre normale de Failure Friday).
2017
- Juillet : Nous avons formé une guilde interne d'ingénieurs au sein de PagerDuty au sein de plusieurs équipes, toutes intéressées par l'ingénierie du chaos.
Statistiques
En revenant sur nos enregistrements du Failure Friday, voici quelques mesures du 28 juin 2013 au 28 juin 2017 :
- Séances du vendredi en cas d'échec : 121
- Tickets créés pour résoudre les problèmes identifiés lors du Failure Friday : plus de 200
- Défauts injectés : 644
- Injections de fautes ayant donné lieu à une autopsie publique : 3
- Pannes AZ complètes simulées (désactiver tous les services dans une AZ donnée) : 4
- Pannes de région complètes simulées (désactiver tous les services dans une région donnée) : 3
- Simulation de reprise après sinistre partielle (envoyer tout le trafic vers une autre région) : 2
- Services distincts au sein de PagerDuty pour lesquels des erreurs ont été injectées : 47
Conclusions
L’injection d’échecs et l’amélioration continue de notre infrastructure nous ont non seulement aidés à fournir de meilleurs logiciels, mais aussi à renforcer la confiance et l’empathie en interne. Les tests de résistance de nos systèmes et processus nous aident à comprendre comment améliorer nos opérations — et Tu peux le faire aussi .