
- PagerDuty /
- Blog /
- Opérations numériques /
- 10 questions que les équipes devraient poser pour une réponse plus rapide aux incidents
Blog
10 questions que les équipes devraient poser pour une réponse plus rapide aux incidents
par Hannah Culver
13 septembre 2021 | 9 minutes de lecture
2019 et 2020 ont été des années à part. Nos façons de travailler, de vivre, de socialiser et d’apprendre ont changé du jour au lendemain. Au cours des 18 derniers mois, les équipes techniques ont dû redoubler d’efforts pour aider leurs clients à s’adapter à la nouvelle normalité. Dans le même temps, les équipes ont dû effectuer plus de travail imprévu que jamais, alors que les incidents se multipliaient sans cesse.
Pour la première fois, nous avons créé le Rapport sur l'état des opérations numériques qui est basé sur les données de la plateforme PagerDuty . Ce rapport montre la disparité entre les équipes techniques de travail auxquelles ont été confrontées en 2019 par rapport à 2020. Nous avons constaté des changements dans le nombre d'incidents critiques, des mesures courantes telles que Temps moyen de réaction (MTTR) et MTTA, comment la pression supplémentaire épuisement professionnel, attrition, et plus.
Dans le dernier épisode de cette série de blogs , nous passerons en revue certaines de ces conclusions et partagerons 10 questions que les équipes peuvent se poser pour améliorer leur réponse aux incidents.
Qu'est ce qui a changé?
Selon les données de notre plateforme, les incidents critiques ont augmenté de 19 % d'une année sur l'autre de 2019 à 2020. Nous considérons les incidents critiques comme ceux provenant de services hautement urgents, non résolus automatiquement dans les cinq jours.
minutes, mais reconnu dans les quatre heures et résolu dans les 24 heures.
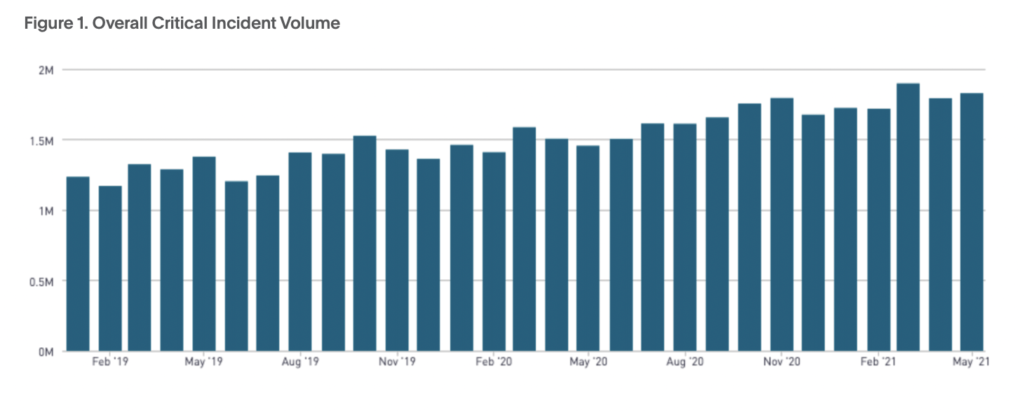
Même si les incidents critiques ont augmenté, le MTTA (temps moyen de reconnaissance) et le MTTR (temps moyen de résolution) ont diminué. Les mesures MTTx ne fournissent pas une image complète de votre processus de réponse aux incidents ou de votre maturité opérationnelle . Mais ils peuvent vous donner un aperçu des performances globales et vous aider à évaluer vos points forts ainsi que vos domaines d’amélioration.
Nous avons constaté que plus une équipe utilisait PagerDuty longtemps, plus le MTTA et le MTTR devenaient faibles. Nous considérons cette MTTA améliorée comme un signe d’une responsabilité accrue. À mesure que le MTTA s'améliore, le pourcentage d'accusé de réception, ou le nombre d'alertes reconnues par l'ingénieur de garde, s'améliore également.
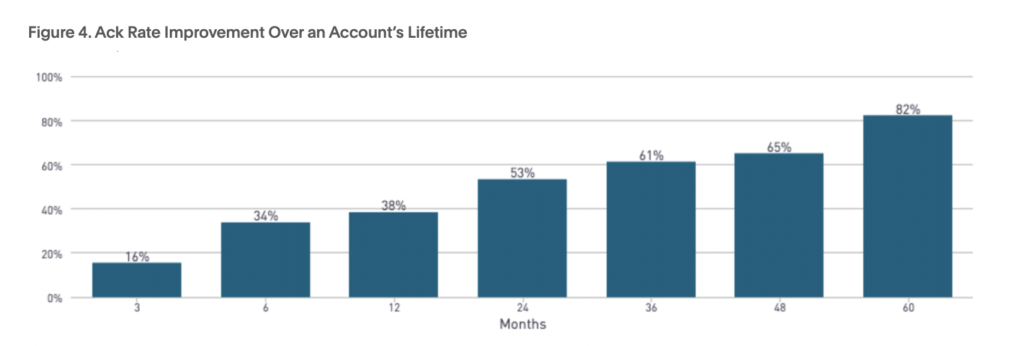
Pourtant, même si le MTTA et le MTTR ont diminué, le temps consacré à la résolution des incidents est toujours en hausse. Les équipes doivent travailler plus intelligemment, et non plus dur. Pour ce faire, elles peuvent identifier les parties du cycle de vie de la réponse aux incidents à optimiser.
10 questions à poser sur votre cycle de vie de réponse aux incidents
Le cycle de réponse aux incidents est un processus qui suit une défaillance de votre système. Il commence par la détection de la défaillance, puis passe à la prévention de l'impact sur le client, à la mobilisation d'une équipe pour répondre, au diagnostic de ce qui se passe, à la résolution du problème et à l'apprentissage de l'expérience. À chaque étape, il existe des opportunités d'affiner vos opérations pour résoudre les incidents plus rapidement et avec moins de travail cognitif.
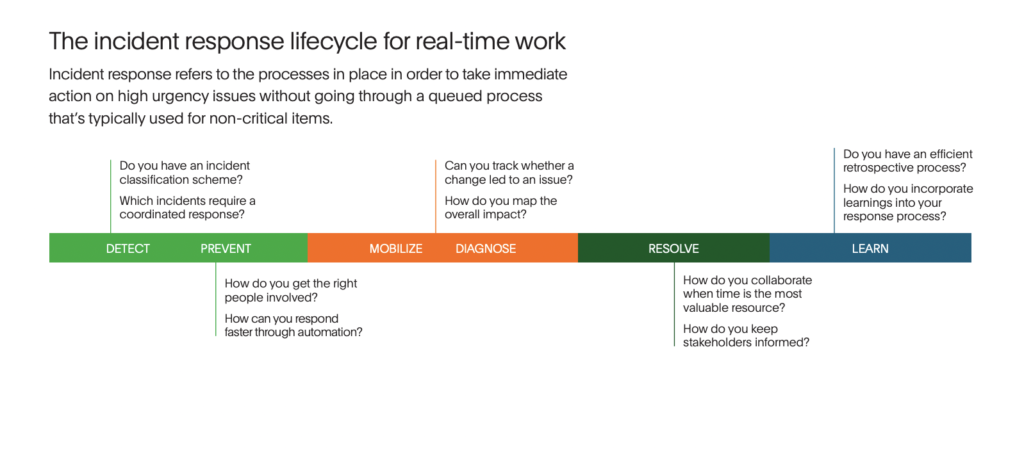
Détecter :Cette étape peut se dérouler de plusieurs manières. Dans le meilleur des cas, votre surveillance vous avertit qu'une anomalie nécessite votre attention. Dans le pire des cas, la détection commence par un client qui doit vous signaler qu'il y a un problème. Dans tous les cas, vous pouvez obtenir une réponse plus rapide en répondant à ces questions à l'avance :
- Quel est le système de classification des incidents de notre organisation ? Certaines équipes aiment utiliser des niveaux de gravité. D'autres les appellent des priorités. Quelle que soit la nomenclature que vous utilisez, assurez-vous que tous les membres de l'équipe comprennent comment classer un incident. Qu'est-ce qui le distingue d'un Sev1 d'un Sev3 ? Comprendre cela à l'avance vous aide à mieux prendre les décisions lorsqu'un incident se produit réellement.
- Quels incidents nécessitent une réponse coordonnée ? Maintenant que vous avez déterminé à quoi ressemblent ces niveaux de gravité, vous devez établir un plan pour le type de personnes qui doivent être impliquées pour chaque problème. Par exemple, un problème de gravité 3 peut être parfaitement géré par un seul ingénieur d'astreinte. En revanche, un problème de gravité 1 peut nécessiter la participation de tous, y compris de la direction. Planifier cela vous aide à éviter l'indécision lors des moments critiques de la mission.
Prévenir l’impact client : À ce stade, vous essayez de limiter l'impact possible sur le client. Pour ce faire, vous devez impliquer les bonnes personnes dès que possible et rechercher des possibilités d'automatisation. Cela peut réduire de plusieurs minutes vos temps de réponse. Posez-vous les questions suivantes pour comprendre comment vous pouvez vous améliorer :
- Comment impliquer les bonnes personnes ? Nous avons déjà mentionné qu'il est essentiel de déterminer les types de personnes à contacter en fonction de la gravité de l'incident. Nous réfléchissons ici à la manière d'impliquer le plus tôt possible les personnes concernées par l'incident. Une façon d'y parvenir consiste à confier l'intégralité des services à un service et à établir une rotation détaillée des astreintes. Lorsque tous vos services sont cartographiés et qu'une équipe est affectée à chacun d'eux, il est plus facile de savoir quelle équipe est responsable de la résolution de l'incident. De plus, grâce à une planification détaillée des astreintes, l'alerte pour le service en question doit être acheminée vers l'ingénieur précis qui lancera le processus de réponse.
- Comment pouvez-vous réagir plus rapidement grâce à l’automatisation ? Ici, Nirvana est capable de remédier automatiquement aux incidents sans intervention humaine. Bien que vous puissiez le faire pour les incidents les plus courants que vous rencontrez, il est plus probable que vous adoptiez une approche similaire à celle du client PagerDuty. Parsons , qui automatise les petites tâches et enchaîne ensuite des séquences plus complexes au fil du temps.
Diagnostiquer :Cette étape consiste à comprendre le problème auquel vous êtes confronté, y compris les causes potentielles et les services dépendants impactés. Au fur et à mesure que vous essayez d'identifier la cause de l'incident, vous pouvez examiner les changements qui pourraient avoir eu un impact sur les services dont vous êtes responsable et la manière dont l'ensemble de l'écosystème est affecté. Plus tôt vous comprendrez ce qui se passe, plus vite vous pourrez y remédier. Réfléchissez à des questions telles que :
- Pouvez-vous savoir si un changement a entraîné un problème ? La cause la plus courante d'un incident est un changement dans la base de code. Si vous avez un outil de gestion des événements de changement , vous pouvez consulter les déploiements récents et trouver un éventuel coupable plus rapidement. Bien que cela ne puisse généralement pas vous donner une solution affirmative à 100 %, cela peut vous fournir une direction à suivre. Assurez-vous de suivre les changements et que tous les ingénieurs d'astreinte disposent de ces informations pour les services auxquels ils répondent.
- Comment cartographiez-vous l’impact global ? Il est important de comprendre comment votre service affecte les autres, à la fois techniques et commerciaux. Pour ce faire, vous devez cartographier les dépendances de votre service et les services dont il dépend. graphique de service peut vous aider à visualiser cela. Au-delà des aspects techniques, réfléchissez à l'impact de votre service sur l'entreprise et faites correspondre vos fonctions technologiques au niveau de l'entreprise. Pour comprendre comment gérer les incidents commerciaux avec cette approche intégrée, consultez cette Guide des opérations.
Résoudre :C'est la partie du processus à laquelle la plupart des gens pensent lorsqu'ils imaginent la réponse à un incident. Une équipe de personnes talentueuses qui pensent savoir quel est le problème et comment le résoudre. À ce stade, vos experts en la matière (quel que soit leur nombre, en fonction de la gravité) travaillent à rétablir le service aux clients. Plus vite cela sera terminé, moins cet incident aura d'impact sur l'entreprise. Mais avant de vous lancer dans les détails, il est important de souligner ces deux éléments.
- Comment collaborer lorsque le temps est la ressource la plus précieuse ? Assurez-vous, avant les incidents, que vous comprenez quels rôles requiert chaque gravité d'incident et quelle est la responsabilité de ces rôles. Par exemple, le commandant d'incident ne peut être utilisé que dans les incidents de niveau 2 et supérieur. Cette personne prendra la tête du processus de réponse. Le scribe, quant à lui, documentera toutes les découvertes importantes durant cette période. Les rôles et responsabilités de PagerDuty sont détaillé ici pour plus de lecture.
- Comment tenez-vous les parties prenantes informées ? La façon dont les équipes communiquent en interne est importante, mais vous devez également réfléchir à la façon de communiquer avec les autres parties prenantes du secteur d'activité, comme le service client, les ventes, les relations publiques et la haute direction. Assurez-vous que votre plan de communication est défini en fonction de la gravité du problème. Pour plus d'informations sur la façon de communiquer avec les parties prenantes, vous pouvez Consultez ce guide.
Apprendre :Une fois l'incident terminé, il est trop tard pour accélérer le temps de résolution de cette défaillance. Cependant, les enseignements tirés de chaque incident peuvent vous aider à mieux résoudre un incident similaire à l'avenir. Essayez de prendre le temps d'examiner tous les incidents critiques et de procéder à une analyse approfondie. Pour analyser la façon dont votre équipe apprend, vous pouvez poser les questions suivantes :
- Avez-vous un processus rétrospectif efficace ? Lorsque vous effectuez une rétrospective, vous devez vous préparer à l'avance et être prêt à discuter de l'incident. Vous devrez créer une chronologie, documenter l'impact, analyser l'incident, créer des éléments d'action, rédiger des messages externes et avoir une discussion approfondie sur ce qui s'est passé. Plus important encore, vous devrez faire en sorte que ce processus soit exempt de toute responsabilité. Il est essentiel de l'aborder dans une perspective d'apprentissage plutôt que de pointer du doigt. Pour en savoir plus sur les autopsies, vous pouvez consulter ce guide .
- Comment intégrez-vous les apprentissages dans votre processus de réponse ? Après une bonne analyse, vous aurez appris quelque chose de nouveau sur votre système. Vous pouvez hiérarchiser les éléments d'action et corriger les bogues pour rendre le service concerné plus fiable à l'avenir. De plus, vous pouvez améliorer votre processus de réponse. Cela vous aide à être plus efficace et mieux préparé. Recherchez les éventuelles pannes de communication, les possibilités d'automatisation ou les moyens d'améliorer votre documentation.
Ces 10 questions peuvent aider votre équipe à mieux comprendre où vous vous situez en termes de maturité en matière de réponse aux incidents. Au fur et à mesure que vous investissez pour améliorer les processus, vous constaterez que vous êtes mieux à même de gérer le nombre toujours croissant d'incidents.
Et après?
Les effectifs ne sont pas en mesure de répondre au nombre d'incidents auxquels les équipes sont confrontées. Et, avec la Grande Démission qui approche, il est important de travailler efficacement jusqu'à ce que les nouveaux coéquipiers soient formés. Si l'augmentation des ressources est un élément à prendre en compte pour aider les équipes à mieux équilibrer la charge de travail, vous pouvez également améliorer la façon dont vous détectez les incidents, prévenez l'impact sur les clients, diagnostiquez et résolvez le problème et tirez les leçons des échecs.
PagerDuty peut aider votre équipe dans ces initiatives. Pour constater par vous-même, inscrivez-vous à votre Essai gratuit de 14 jours. Ou, si vous êtes curieux d'en savoir plus sur les résultats de nos données de plateforme, vous pouvez lire l'intégralité Rapport sur l'état des opérations numériques .

