
- PagerDuty /
- Blog /
- Intégrations /
- Surveillance des signaux sociaux pour réduire la fatigue liée aux alertes avec SignalFx et PagerDuty
Blog
Surveillance des signaux sociaux pour réduire la fatigue liée aux alertes avec SignalFx et PagerDuty
par Arijit Mukherji
19 septembre 2018 | 6 minutes de lecture
« J'ai besoin d'être informé si un événement important se produit avec SignalFx. » C’est ce que je dis à mon équipe. Cependant, bien que je sois le directeur technique d’une société de surveillance, créer le bon ensemble d’alertes pour me tenir informé des incidents en cours ou des problèmes potentiels s’est avéré plus difficile qu’il n’y paraissait à première vue.
Pourquoi?
Bien que l'avènement du cloud et des technologies open source nous ait permis de créer des logiciels beaucoup plus rapidement, les environnements d'aujourd'hui sont beaucoup plus complexes à mettre en œuvre. moniteur et gérer pour un certain nombre de raisons, notamment :
- L'explosion du nombre d'instances de calcul à surveiller (hôtes, conteneurs, fonctions).
- Les services émettent rarement des mesures « bien comportées » et changent constamment au fil du temps.
- Le nombre croissant de services devant être surveillés individuellement en raison de l'architecture des microservices.
Pour beaucoup d'entre nous, le résultat est une avalanche de fausses alertes positives ou redondantes. La lassitude des alertes entrave non seulement la capacité de votre équipe à détecter et à résoudre les problèmes en temps réel, mais si elle n'est pas résolue pendant suffisamment longtemps, elle détruit également le moral de l'équipe et entraîne des pannes évitables.
Stratégies pour réduire la fatigue d’alerte
Réduire la fatigue liée aux alertes Il faut commencer par élargir son champ de vision. Si la mesure fine des indicateurs est extrêmement utile lors du dépannage et de l'analyse médico-légale, les alertes les plus exploitables reposent sur une combinaison de signaux qui créent des indicateurs de niveau supérieur de l'état de santé de l'application. Vous devez notamment prendre en compte les éléments suivants :
Suivi des populations, et non des cas individuels
Définissez et abonnez-vous à des indicateurs de santé par service ou par population au lieu d'alerter sur l'état de chaque composant individuel de votre environnement. Par exemple, vous pouvez suivre la latence du 99e centile d'un appel d'API sur plusieurs instances de service, l'utilisation moyenne du processeur pour un cluster de nœuds donné ou la somme des erreurs d'API pour un groupe de conteneurs qui le servent.
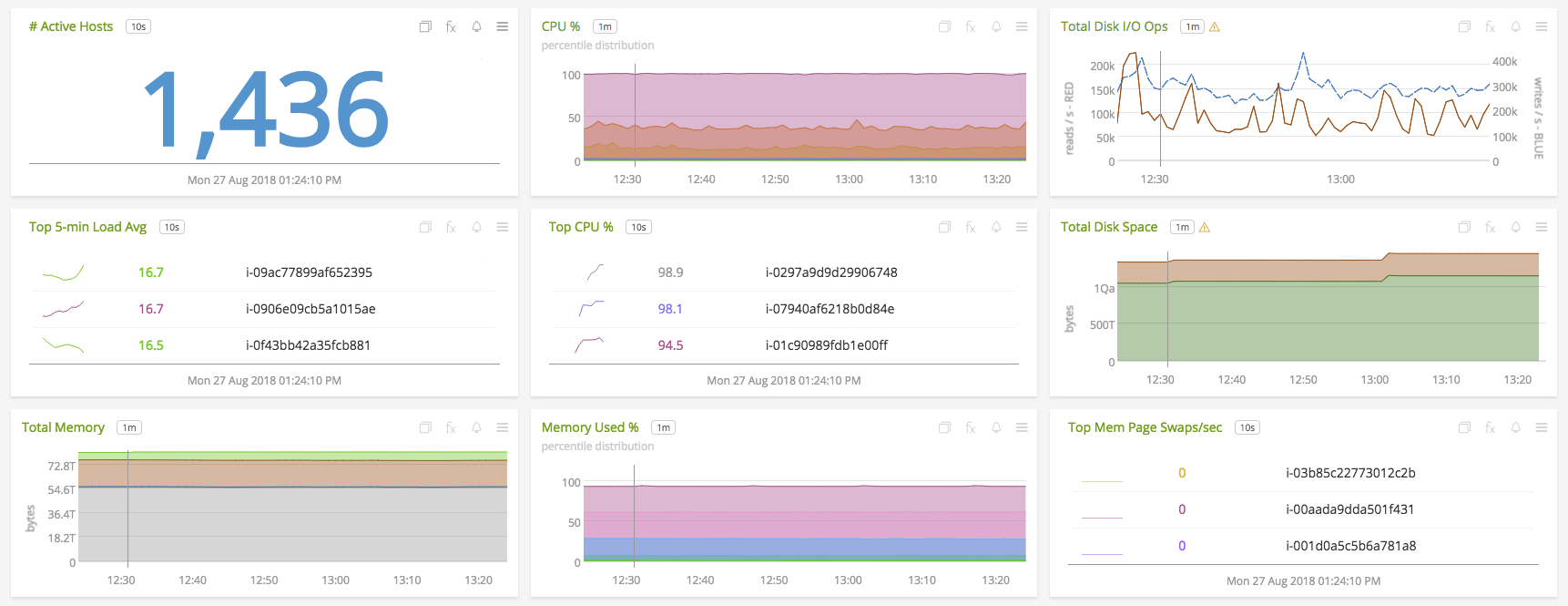
Mesures système agrégées sur 1 436 hôtes
Alerter sur les modèles et les tendances plutôt que sur des seuils numériques fixes
Utilisez des seuils générés par algorithme qui peuvent s'adapter aux environnements changeants. Les systèmes distribués se comportent souvent de manière mystérieuse, ce qui rend extrêmement difficile la détermination de la « bonne » quantité d'utilisation du processeur ou des erreurs d'API qui se produisent avant le déclenchement d'une alerte.
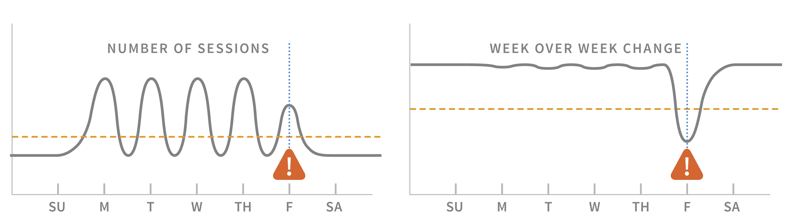
Alerte sur le nombre brut de sessions par rapport à l'évolution d'une semaine à l'autre
En tenant compte des modèles réguliers (par exemple, un trafic plus élevé en semaine) ou en émettant des alertes prédictives (alerte lorsqu'un cluster est sur le point de manquer d'espace disque dans les N prochains jours), vous pouvez faire une meilleure distinction entre le comportement normal du système et quelque chose qui justifie une réponse.
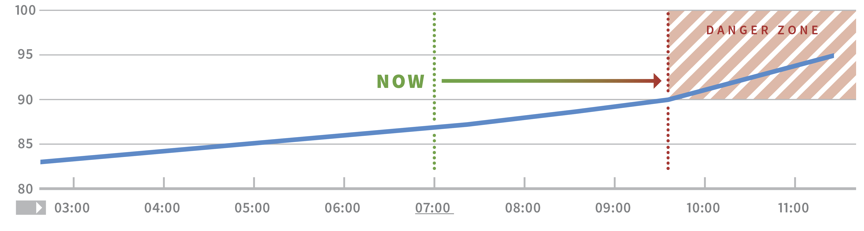
Graphique affichant une tendance métrique en fonction de la capacité
Définition des mesures globales de performance des applications
Combinez les mesures de différents microservices pour obtenir des signaux et des alertes de niveau supérieur. Deux possibilités sont possibles : le nombre de chargements de pages par utilisateur connecté ou le nombre d'erreurs d'API mesuré en pourcentage du total des appels d'API. L'un de nos clients combine les mesures de tous ses microservices pour créer un « score de santé » pour les versions de déploiement qui indique si les performances de l'application se sont améliorées dans leur ensemble.
Mesurer les signaux sociaux
Malgré le fait que nous utilisons toutes ces techniques chez SignalFx, je recevais encore trop d'alertes faussement positives. Gardez à l'esprit les points suivants :
- En tant que responsable technique, je n'ai pas besoin d'alertes aussi précises qu'un propriétaire de service ou un ingénieur d'astreinte. Il est également peu pratique de suivre uniquement un sous-ensemble d'alertes, car cette liste d'abonnement devient rapidement obsolète sans une vigilance constante.
- Bien que notre organisation utilise PagerDuty, je ne suis pas toujours sur le chemin d'escalade d'astreinte .
- Bien que je puisse filtrer les problèmes mineurs en consultant des sources telles que la page d'état de SignalFx, cela enverrait des alertes trop tard (après qu'un problème de site soit en plein essor plutôt qu'avant) pour que je puisse contribuer activement à la réponse aux incidents.
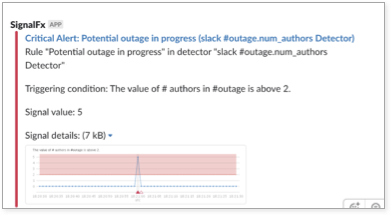
Quels autres signaux puis-je mesurer ? Chez SignalFx, nous avons un canal Slack que nous avons nommé #outage et qui est spécifiquement destiné à discuter des incidents. Ce canal reçoit également des notifications d'alertes critiques de PagerDuty afin de préserver le contexte de ces discussions. Sachant que les problèmes importants poussent souvent plusieurs utilisateurs à collaborer sur Slack et à remonter via PagerDuty, j'ai décidé de recueillir des mesures sur l'activité humaine dans #outage. Le résultat ressemblait à ceci :
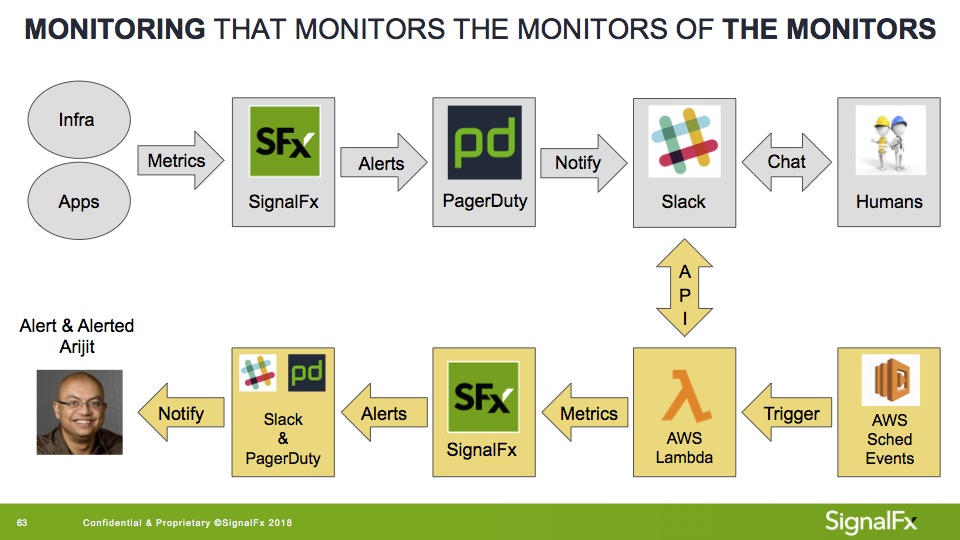
Gris : flux de travail d'alerte SignalFx « normal »
Jaune : Alerte avec signaux sociaux
J'ai utilisé un AWS Lambda configuré pour interroger et classer les messages (par exemple, générés par un humain ou par un robot), puis les publier sur SignalFx. Ensuite, j'ai créé un détecteur d'alerte qui m'a averti lorsque plus de trois auteurs humains uniques saisissaient #outage pendant une période de cinq minutes ou plus. Les alertes étaient envoyées sur mon téléphone via PagerDuty et un message direct dans Mou .
Notification d'une panne potentielle en cours
Cela a fonctionné étonnamment bien : même si j’ai encore reçu quelques faux positifs, le nombre est tombé à presque zéro et j’ai été averti pour chaque incident qui m’intéressait. Il est intéressant de noter que j’ai également été informé de quelques incidents potentiels pour lesquels je n’avais pas d’alertes actives définies, mais que nos ingénieurs avaient découverts dans le cadre de leur observation générale du service.
Ne cessez pas de surveiller le matériel et les logiciels
Au début, j’ai été déçu de ne pas pouvoir créer l’alerte « parfaite » en me basant uniquement sur les mesures d’application et d’infrastructure, mais c’était peut-être une attente naïve. Pour créer l’alerte appropriée, il faut non seulement comprendre votre environnement, mais aussi la façon dont votre organisation réagit aux incidents.
Mesurer le comportement humain était suffisant pour mon cas d’utilisation spécifique, mais étant donné l’interopérabilité et l’indépendance des données de nombreux outils actuels, il existe une multitude d’autres signaux que nous pourrions potentiellement intégrer dans notre surveillance.
Intégrer la détection des problèmes à la gestion des incidents
Les activités en temps réel nécessitent une intelligence opérationnelle en temps réel, et les technologies actuelles émettent bien plus de données que ce que les outils de surveillance traditionnels peuvent gérer. SignalFx collecte des mesures en continu de chaque composant de votre environnement pour fournir des analyses et des alertes en quelques secondes, afin que vous puissiez trouver et résoudre les problèmes avant qu'ils n'affectent les clients.
Avec SignalFx et PagerDuty , vous pouvez ouvrir automatiquement des incidents dans PagerDuty lorsqu'un détecteur d'alerte est déclenché dans SignalFx, mapper différentes politiques d'escalade en fonction de l'alerte et marquer automatiquement les incidents résolus lorsque les choses reviennent à la normale.
Chez SignalFx, nous aidons les organisations à surveiller tous les signaux importants, en temps réel, à n'importe quelle échelle, et leur donnons la confiance nécessaire pour innover plus rapidement que jamais.
Arijit Mukherji est CTO chez SignalFx et passionné par la surveillance. Il a été l'un des développeurs originaux de la solution de mesures de Facebook (ODS) et a ensuite géré le développement des outils de mise en réseau, de visualisation des données et d'autres logiciels de surveillance des infrastructures de Facebook. Bien qu'il se soit concentré sur le domaine de la surveillance pendant plus d'une décennie, sa carrière diversifiée de plus de 20 ans couvre également la téléphonie IP, la conférence VoIP et la virtualisation des réseaux.

