
- PagerDuty /
- Blog /
- Intégrations /
- Comment obtenir une visibilité en temps réel sur les applications sans serveur
Blog
Comment obtenir une visibilité en temps réel sur les applications sans serveur
par Steve Gross
1er mai 2019 | 5 minutes de lecture
En tant que PDG et cofondateur d'IOpipe, Adam Johnson travaille avec des développeurs individuels et des équipes d'ingénierie d'entreprises mondiales pour obtenir une visibilité en temps réel sur les comportements détaillés de leurs applications sans serveur.
Selon Le livre électronique 2018 de The New Stack L'adoption du sans serveur a augmenté de 75 % depuis 2017, mais les développeurs continuent de citer des inquiétudes concernant les performances, les risques et la surveillance des applications comme des inconvénients à la construction d'une architecture sans serveur.
Malgré les progrès réalisés dans les outils d'observabilité au cours de l'année écoulée, les alertes concernant les anomalies de performances et les perturbations des utilisateurs constituent un élément crucial, mais encore négligé, pour que les équipes d'ingénierie puissent fournir des applications sans serveur en toute confiance. Dans cet esprit, Adam a partagé certains des défis auxquels il a été confronté dans ce secteur, ainsi que les meilleures pratiques et des conseils techniques dans cette séance de questions-réponses.
Q : En quoi la surveillance des applications sans serveur diffère-t-elle de celle des architectures traditionnelles ?
UN: La principale différence avec la surveillance sans serveur est que l'accent est davantage mis sur la logique métier qui circule dans le système et que l'aspect infrastructure est moins important. Avec les architectures sans serveur, les problèmes d'infrastructure échappent en grande partie à votre contrôle et sont gérés par les fournisseurs de cloud qui exécutent la plateforme FaaS (Function-as-a-Service). Les entreprises peuvent ainsi se concentrer sur l'impact de l'activité.
Par exemple, certaines des principales marques de commerce électronique utilisant IOpipe créent des alertes en fonction des volumes de commandes attendus, de sorte que lorsqu'il y a une baisse (ou un pic) inattendue des commandes, elles peuvent être averties en quelques secondes si quelque chose sort de l'ordinaire.
Bien que la mise en œuvre d'une solution sans serveur offre des avantages en termes de rapidité et de coût, de nombreux développeurs ont encore du mal à obtenir une visibilité sur le comportement de leurs applications sans serveur. Par exemple, comment tracer des millions d'appels pour trouver les utilisateurs impactés par un problème de performances ? Si un problème survient, comment isoler rapidement la ou les fonctions responsables pour minimiser les perturbations de l'activité ?
La surveillance traditionnelle n'est pas nécessairement configurée pour gérer les différents défis des architectures sans serveur ou maximiser les chances des développeurs et des équipes DevOps de traduire les mesures d'infrastructure en informations commerciales lorsqu'ils transfèrent les charges de performances et de mise à l'échelle aux fournisseurs de cloud.
Q : Quels sont les avantages et les inconvénients des applications sans serveur par rapport aux applications monolithiques ?
UN: Le plus grand avantage du serverless par rapport aux applications monolithiques est qu'il permet aux développeurs de se concentrer entièrement sur la création et la livraison de la logique métier. Cela permet aux entreprises de fournir de la valeur à leurs clients, plus rapidement. Les développeurs n'ont plus besoin de passer du temps à se concentrer sur le codage et la configuration de l'infrastructure pour planifier les événements de mise à l'échelle. La mise à l'échelle est prise en charge dès la mise en service. En plus d'une livraison plus rapide, vous ne payez que ce que vous utilisez en serverless. Il y a donc généralement des avantages de coûts significatifs, les entreprises signalant des économies allant jusqu'à 90 % lorsqu'elles abandonnent les machines virtuelles et les conteneurs.
Le principal inconvénient est que, à moins de définir votre niveau de concurrence sur 1, vous exécutez un système distribué. Cela peut créer de nouveaux défis, en particulier lorsqu'il s'agit d'obtenir une observabilité autour de ces systèmes. Heureusement, il existe une multitude d'outils de nouvelle génération qui fournissent des informations détaillées sur les applications sans serveur, améliorant même la visibilité par rapport aux applications monolithiques existantes.
Q : Quels sont les principaux problèmes de performances sur une architecture sans serveur ?
UN: L’un des problèmes les plus discutés autour des performances sans serveur concerne démarrages à froid , ce qui se produit lorsqu'il y a un petit retard dans le démarrage d'un nouveau conteneur. Heureusement pour des langages tels que Node.js et Python, les impacts du démarrage à froid ont été considérablement réduits à quelques millisecondes dans AWS Lambda. Pour d'autres langages comme Java, les démarrages à froid peuvent toujours avoir un impact significatif sur les performances.
Cependant, les outils d'observabilité sans serveur comme IOpipe peuvent fournir une visibilité sur les performances de démarrage à froid. Cela aide les utilisateurs à comprendre l'impact réel et à déterminer s'il vaut la peine d'optimiser quelque chose.
Q : Pour une entreprise ou un développeur novice en matière de solutions sans serveur, quelles sont les alertes standard qu'ils devraient mettre en œuvre dès le départ ?
UN: La première alerte que les clients d'IOpipe configurent généralement concerne les échecs d'application. De nombreux clients configurent des alertes sur le taux d'erreur de leurs applications sans serveur, afin d'être avertis dès que le taux d'erreur dépasse leur seuil de confort.
Une autre alerte fortement recommandée est l'invocation de fonctions qui doivent être exécutées un certain nombre de fois par période. Ainsi, s'ils s'attendent à ce qu'une fonction s'exécute au moins une fois par jour, ils doivent configurer une alerte pour les avertir lorsque la fonction ne s'exécute pas ce jour-là.
Pour les applications sans serveur qui traitent un flux ou des lots de données dont le volume est assez prévisible, la configuration d'alertes sur les seuils supérieurs et inférieurs du nombre d'appels est un moyen utile d'identifier quand il y a un problème dans le pipeline de données.
Q : Comment les développeurs ou les équipes DevOps doivent-ils gérer le débogage face au volume accru de journaux de fonctions inhérent au sans serveur ?
UN: Investir du temps dans l'instrumentation d'applications sans serveur avec des journaux et des étiquettes structurés peut éliminer complètement le besoin de fouiller dans les fichiers journaux. Un petit effort initial peut vous faire gagner des heures, voire des jours, de temps de débogage précieux lorsqu'un problème survient.
Q : Comment les développeurs intègrent-ils la surveillance sans serveur à leur compte PagerDuty existant ?
UN: IOpipe propose une intégration native avec PagerDuty. En quelques clics, les développeurs peuvent être avertis via PagerDuty chaque fois que leurs alertes sont déclenchées.
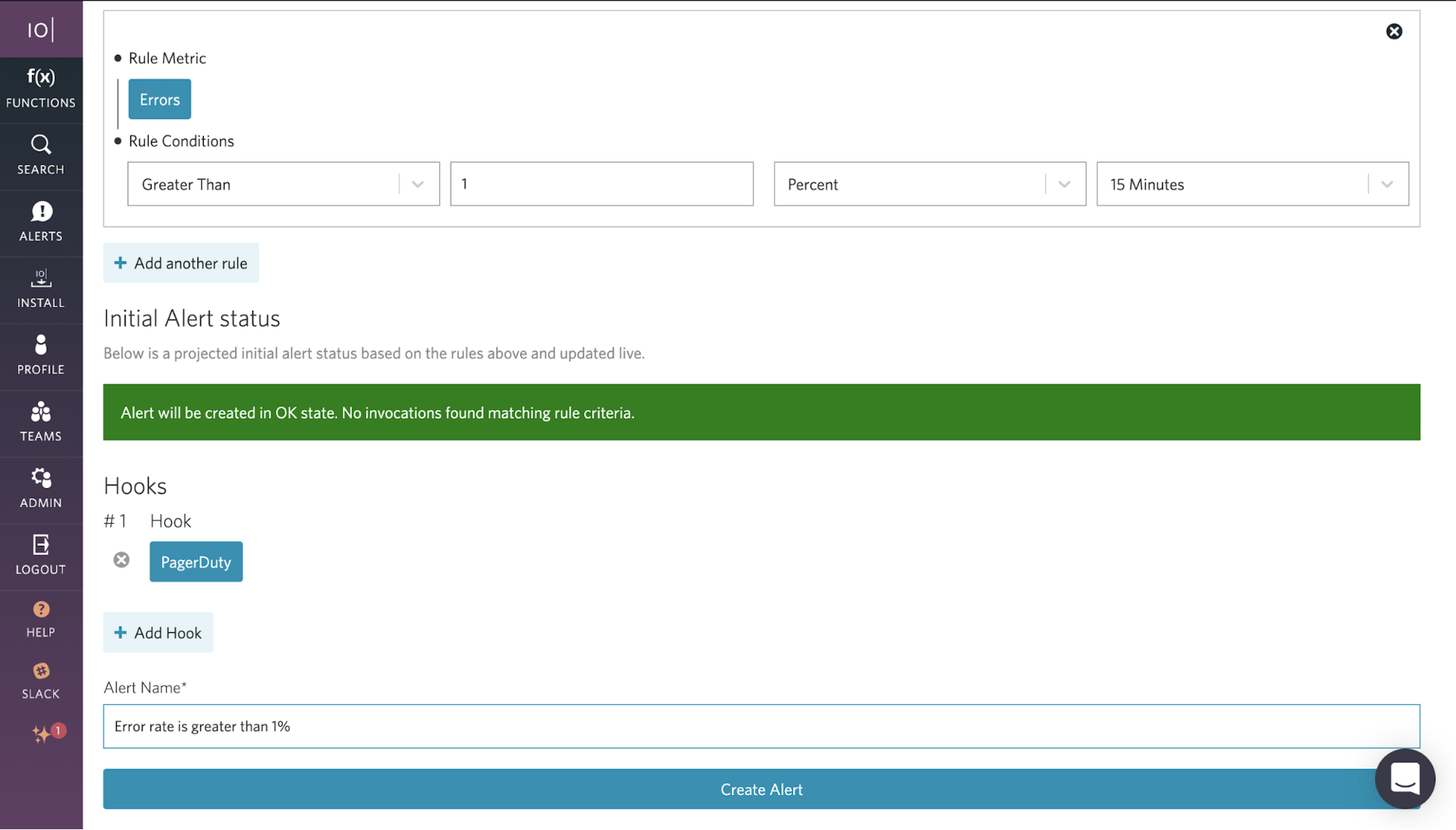
En partenariat avec PagerDuty et en fournissant une observabilité et une surveillance sans serveur à des organisations telles que Rackspace, Matson et Comic Relief, IOpipe a récemment publié une refonte de ses fonctionnalités d'alertes sans serveur pour les environnements d'exécution Python, Node.JS, Go et Java sur AWS Lambda.
Vous voulez en savoir plus ? Découvrez le PagerDuty – Guide d'intégration IOpipe.

