
- PagerDuty /
- Blog /
- Partenariats /
- Utiliser l'IA/ML pour dynamiser la livraison continue avec Harness et PagerDuty
Blog
Utiliser l'IA/ML pour dynamiser la livraison continue avec Harness et PagerDuty
par Steve Burton
7 septembre 2018 | 4 minutes de lecture
À première vue, l’application de l’apprentissage automatique à Livraison continue Cela peut sembler un peu comme casser une cacahuète avec un marteau-pilon. Je veux dire, à quel point l'automatisation du déploiement peut-elle être difficile ?
Il s’avère que c’est bien plus complexe qu’on ne le pense.
Le passage d’un nouveau déploiement en production a généralement deux conséquences :
- Le service reste opérationnel et nous pensons que tout va bien.
- Le service ne reste pas opérationnel et l'enfer se déchaîne.
La réalité est que ces deux points ci-dessus représentent la manière dont 95 % des organisations mesurent le succès du déploiement (en hausse = bon, en baisse = mauvais). Ceux d'entre vous qui sont des clients satisfaits de PagerDuty connaîtront mieux le résultat n°2 (de la tempête d'alertes/incidents qui ont frappé votre téléphone portable). Cependant, le scénario n°1 est également trompeur car un service qui reste opérationnel n'implique pas automatiquement la santé, les performances ou la qualité.
Inconvénients des contrôles de santé de déploiement manuel
Une chose que nous avons apprise de nos 25 premiers clients chez Harnais est que la plupart des organisations ont généralement 3 à 5 ingénieurs qui passent chacun au moins une heure à vérifier manuellement les déploiements de production. Par exemple, l'un de nos clients, Build.com , avait l'habitude d'avoir 5 à 6 chefs d'équipe qui passaient chacun une heure à analyser manuellement les données de Nouvelle relique et Logique Sumo —ce qui signifie généralement avoir plusieurs fenêtres de console/navigateur ouvertes et basculer entre les scripts bash, la surveillance des performances des applications et les outils d'analyse des journaux.
Étant donné que le cerveau humain ne peut se concentrer que sur 8 à 10 éléments dans la mémoire à court terme et avec toutes les données entrantes provenant de divers systèmes, il est assez facile pour les humains en 2018 de passer à côté de certaines choses. L'analyse manuelle et les contrôles de santé sont des défis lorsque vous avez plusieurs centaines de milliers de mesures de séries chronologiques et quelques millions d'entrées de journal à examiner après le déploiement.
Laissez l'IA/l'apprentissage automatique vous aider dans vos contrôles de santé
Chez Harness, nous n'automatisons pas seulement le déploiement d'artefacts logiciels en production ; nous automatisons également les contrôles de santé à l'aide de l'IA et du ML. Nous appelons cela Vérification continue .
Nous utilisons principalement des algorithmes d'apprentissage automatique non supervisés tels que les modèles de Markov cachés, la représentation agrégée symbolique, le clustering KMeans et certains réseaux neuronaux pour automatiser la détection d'anomalies et de régressions à partir des données APM et des journaux.
Quelques secondes après le déploiement d'un nouvel artefact logiciel, Harness peut se connecter à n'importe quel APM ou outil de journalisation et générer automatiquement un modèle de comportement de l'application du point de vue des performances (temps de réponse/débit) et de la qualité (erreur/exception/événements).
Harness compare ensuite ces modèles avec les déploiements précédents et signale instantanément toute nouvelle anomalie ou régression. Ce qui prend des heures à traiter et à analyser par des humains ne prend que quelques secondes avec les algorithmes de machine learning.
Par exemple, les captures d'écran ci-dessous proviennent de la vérification Harness des données AppDynamics APM :

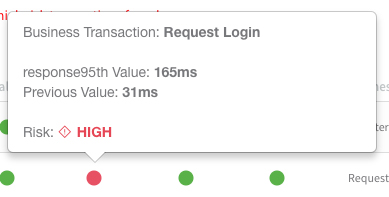
Dans l'image ci-dessus, vous pouvez voir que Harness a signalé deux régressions des performances des transactions commerciales après le déploiement. En lien avec cela, l'image ci-dessous montre qu'une transaction, « Demander une connexion », a en fait augmenté de 31 ms à 165 ms en temps de réponse. Toutes ces analyses sont automatisées grâce à l'IA/ML.
Voici un autre exemple de détection d'anomalies d'erreur/exception par Harness dans les journaux d'application de Splunk :
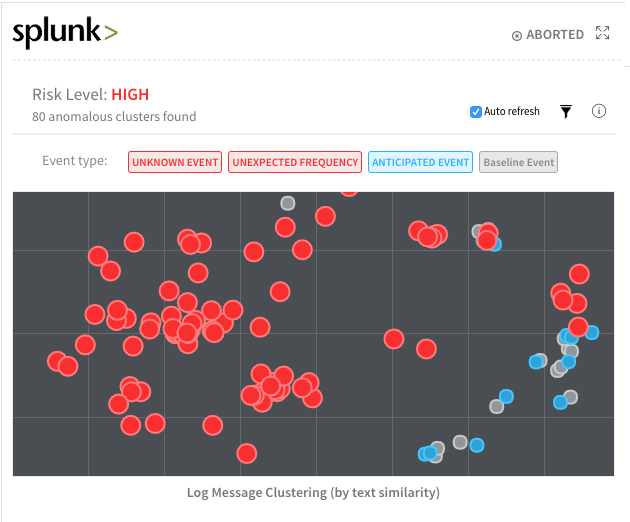
Les points rouges indiquent les nouvelles erreurs introduites dans les journaux d'application à partir du déploiement. Les points gris et bleus représentent les événements de base ou les erreurs/exceptions qui sont normalement observés à chaque déploiement.
Harness utilise le clustering KMeans avec quelques calculs de distance Jacard et Cosine pour générer ces visuels. Cliquer sur n'importe quel point affiche également la trace de la pile et la cause première de l'événement.
Automatisez la restauration avec l'intelligence artificielle/machine learning
Harness peut également automatiser la restauration des déploiements à l'aide de l'intelligence de sa vérification continue. Considérez Harness comme un filet de sécurité qui permet aux équipes Dev/DevOps de déployer plus rapidement, puis de revenir en arrière dès que de nouvelles anomalies ou régressions sont détectées.
Avec la prise en charge prochaine par Harness de PagerDuty, les organisations pourront utiliser PagerDuty comme canal de notification ainsi que comme source de vérification. Par exemple, Harness peut interroger le pré-déploiement de PagerDuty pour voir s'il y a des incidents actifs en production. La dernière chose que les équipes Dev/DevOps souhaitent faire est de déployer dans un environnement chaud.
En résumé, Harness propose Livraison continue en tant que service qui aide les organisations à automatiser le déploiement et la livraison de logiciels aux utilisateurs finaux en production. Nous aidons les clients à évoluer rapidement sans rien casser.
Steve Burton est CI/CD et DevOps Evangelist chez Harness.io. Avant Harness, Steve a travaillé comme Geek chez AppDynamics, Moogsoft et Glassdoor. Il a commencé sa carrière en tant que développeur Java en 2004 chez Sapient. Lorsqu'il ne joue pas avec la technologie, il regarde généralement la F1 ou fait des recherches sur les voitures sur Internet.

