
- PagerDuty /
- Blog /
- Gestion et réponse aux incidents /
- Mesurer la dette technique avec les données de gestion des incidents
Blog
Mesurer la dette technique avec les données de gestion des incidents
par Christophe Tozzi
14 mars 2017 | 6 minutes de lecture
Si la dette technique était comme la dette monétaire, il serait difficile d’en assurer le suivi à moins de la vérifier manuellement. La seule façon pour beaucoup de gens de savoir que leur compte courant est à court de fonds est de se connecter et de vérifier le solde – ou, pire, de voir un chèque sans provision ou une carte de débit refusée.
Mais la mesure de la dette technique peut être plus automatique. En effet, contrairement à votre compte bancaire, votre L'infrastructure informatique peut être surveillée de manière continue avec des outils spécialisés, et vous pouvez être averti sur indicateurs de santé critiques . À votre tour, vous pouvez utiliser Données de surveillance pour obtenir des informations sur la dette technique. En d'autres termes, vous n'avez pas besoin de réaliser un audit manuel pour savoir si quelque chose ne va pas dans votre centre de données. Vous n'avez pas besoin d'attendre qu'un serveur tombe en panne avant d'être informé d'un problème. Les outils de gestion des incidents vous fournissent ces informations. Par extension, ils vous offrent également un moyen de faire le point sur votre dette technique sans avoir à mesurer les choses à la main.
Voici comment la gestion des incidents peut vous aider à suivre la dette technique et à la corriger, sans investissement supplémentaire de votre part.
Définition de la dette technique
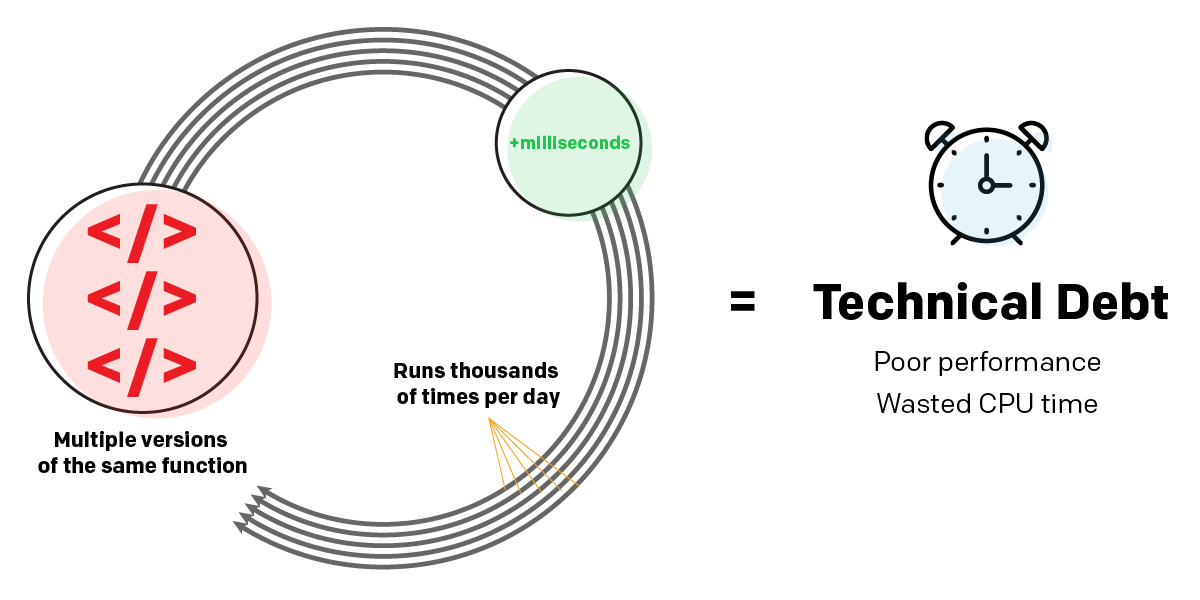 Tout d’abord, permettez-moi d’expliquer ce que j’entends par dette technique. La dette technique fait référence aux imperfections du code ou de l’architecture d’un logiciel qui, à long terme, créent des inefficacités ou d’autres problèmes. Même si l’imperfection elle-même est minime, elle peut générer beaucoup d’« intérêt » au fil du temps, car ses effets se répètent continuellement.
Tout d’abord, permettez-moi d’expliquer ce que j’entends par dette technique. La dette technique fait référence aux imperfections du code ou de l’architecture d’un logiciel qui, à long terme, créent des inefficacités ou d’autres problèmes. Même si l’imperfection elle-même est minime, elle peut générer beaucoup d’« intérêt » au fil du temps, car ses effets se répètent continuellement.
Par exemple, un programme dont le code contient plusieurs versions des mêmes fonctions, plutôt que d'adopter une approche modulaire, pourrait prendre quelques millisecondes de plus à s'exécuter qu'un programme mieux écrit. Ce n'est pas un gros problème si vous l'exécutez une fois. Mais s'il s'agit d'une application Web côté serveur qui s'exécute des milliers de fois par jour, la dette s'accumule rapidement sous la forme de performances médiocres et de temps CPU gaspillé.
La dette technique a beaucoup de causes potentielles . Parfois, vous pouvez sciemment acquérir une dette technique parce que vous devez mettre en œuvre quelque chose rapidement, vous n'avez pas le temps de suivre les meilleures pratiques et vous décidez que la dette en vaut la peine (à ce moment-là du moins). Parfois, même les administrateurs les plus pointilleux ont du mal à éviter la dette technique. À moins que vous ne puissiez voir l'avenir (par exemple, vous ne saviez probablement pas qu'un commutateur vieux de dix ans que vous utilisez encore aujourd'hui parce que vous ne pouvez pas vous permettre de le mettre à niveau ne fonctionnerait pas bien avec les outils de pare-feu modernes). Dans ce cas, la dette technique est tout simplement normale dans un monde imparfait.
Suivi de la dette technique
Bien que la dette technique ait de nombreuses origines, l’avantage de la gestion des incidents pour la mesurer est qu’elle permet de suivre facilement les problèmes, quelle qu’en soit la cause. Là encore, au lieu de procéder à un audit manuel fastidieux de vos systèmes pour rechercher des inefficacités, vous pouvez exploiter vos données de gestion des incidents comme un proxy pour évaluer l’étendue de la dette technique et la cibler.
Pour comprendre comment, examinons quelques exemples de différents types de données de gestion des incidents suivies par PagerDuty , et ce que cela peut révéler sur votre dette technique.
Pour commencer, prenez le nombre brut d'alertes générées par vos outils. Il s'agit d'une mesure très basique, qui peut être affectée par un certain nombre de facteurs. Mais en supposant que vos systèmes de gestion des incidents soient correctement configurés et que vous n'apportiez aucun changement majeur à votre infrastructure, il est probable qu'il existe une relation entre la taille de votre dette technique et le nombre d'incidents signalés par vos outils. En effet, une dette plus importante signifie des performances plus faibles, ce qui déclenche à son tour des alertes lorsque les temps de réponse ou les niveaux de ressources atteignent certains seuils. Ainsi, une diminution constante d'un mois à l'autre de l'occurrence des alertes pourrait signifier que votre dette technique diminue parce que votre code est devenu plus efficace.
Délai moyen de résolution Le MTTR (Mesure moyenne de temps de réponse) est une autre mesure de gestion des incidents qui offre un aperçu de votre dette technique. L'une des causes courantes d'un MTTR médiocre est un code trop complexe. Par exemple, pour reprendre l'exemple ci-dessus, un code écrit à la hâte et contenant des fonctions redondantes sera difficile à comprendre rapidement pour un administrateur. Cela signifie un temps de résolution plus long dans le cas où il doit lire et modifier ce code afin de répondre à un incident.
Le taux d'escalade dans vos données de gestion des incidents est également une mesure utile de la dette technique. Les escalades se produisent lorsque le premier intervenant sur un incident n'est pas en mesure de résoudre le problème et doit faire appel à une aide supplémentaire. Des escalades fréquentes signifient probablement l'une des deux choses suivantes. Tout d'abord, vos administrateurs ne sont peut-être pas bons dans leur travail, mais si c'est le cas, vous le sauriez déjà bien avant d'examiner vos données de gestion des incidents. La deuxième cause principale d'escalade est un code trop complexe pour être traité facilement par la personne qui répond à un incident. Si c'est le type de code auquel vos administrateurs sont confrontés lorsqu'ils répondent aux alertes, il y a de fortes chances que le code ait été mal écrit et soit une source de dette technique.
Trouver la source de la dette technique
En plus de vous aider à retracer les tendances générales concernant votre dette technique, les données de gestion des incidents sont également utiles pour identifier la source d'un problème.
Par exemple, si votre MTTR pour les incidents liés à un certain programme est supérieur à votre MTTR moyen, il y a de fortes chances que le programme en question génère une dette technique. De même, si les serveurs exécutant un type de système d'exploitation génèrent un nombre disproportionné d'alertes, il y a probablement une faille de code ou de configuration en jeu. Il s'agit d'une dette technique que vous pouvez régler.
L'avantage de l'utilisation des données de gestion des incidents pour localiser et traiter la dette technique est qu'elle ne nécessite pas de travail supplémentaire important. Vous avez déjà Systèmes de surveillance en place, avec (espérons-le) un centre d'opérations et de reporting central comme PagerDuty. Tirer parti de ces ressources pour trouver et corriger la dette technique ne nécessite pas d'outils ou d'investissements supplémentaires. Cela vous aide à rendre proactivement votre code et vos opérations plus efficaces, en utilisant le logiciel que vous avez déjà en place.
Vous aimerez peut-être aussi ceux-ci...

