
- PagerDuty /
- Blog /
- Surveillance /
- Alerte SLO intelligente avec Wavefront
Blog
Alerte SLO intelligente avec Wavefront
par Pont Rydin
7 novembre 2019 | 9 minutes de lecture
Les SLO sont devenus importants
À l'époque des applications monolithiques, la plupart des développeurs et propriétaires d'applications s'appuyaient sur des connaissances tribales pour savoir quelles performances attendre. Bien que les applications puissent être incroyablement complexes, la compréhension de leur fonctionnement interne résidait généralement chez un nombre relativement restreint de personnes au sein de l'organisation. Les performances des applications étaient gérées de manière informelle et mesurées de manière informelle.
Cependant, ce modèle s'effondre dans un monde de microservices. En utilisant des méthodes informelles, une seule équipe ou un petit groupe ne peut plus avoir une vue d'ensemble d'une application et, par conséquent, ne peut pas en déduire les performances. En effet, les chaînes de services peuvent être très profondes et un manque de compréhension des performances des composants en aval peut entraîner des surprises désagréables qui affectent à la fois les utilisateurs finaux et l'entreprise.
Alors, qu'est-ce qu'un SLO ?
Avant d’aller plus loin, définissons un objectif de niveau de service (SLO), ainsi que quelques concepts et acronymes associés.
Les SLI sont ce que nous mesurons
Un indicateur de niveau de service (SLI) est une quantité que nous mesurons pour déterminer si nous respectons un SLO. Très souvent, les SLI mesurent soit le taux de réussite, soit les performances d'une opération, mais un SLI peut être n'importe quelle mesure.
Les SLO rendent les SLI exploitables
Pour qu'un SLI soit intéressant, il doit être associé à une condition. Par exemple, nous pouvons indiquer que 99 % de toutes les opérations doivent être terminées avec succès ou que 95 % de toutes les transactions doivent être terminées en une seconde. Nous exprimons souvent les SLO sous forme de pourcentage sur une certaine période. Par exemple, nous pouvons mesurer le taux de réussite de 99 % sur 24 heures et les performances de latence de 95 % supérieures à une seconde peuvent être mesurées sur une heure.
Un SLO doit être atteignable, répétable, mesurable, compréhensible, significatif, contrôlable, abordable et mutuellement acceptable. 1 Par exemple, un taux de réussite de transaction de 99,9999999 % peut ne pas être atteignable car le matériel disponible dans le commerce ne peut pas offrir ce niveau de fiabilité. De même, un SLO basé sur une mesure technique obscure n'est probablement ni compréhensible ni significatif pour la plupart des utilisateurs.
Les SLA sont des SLO avec une clause « Ou-Sinon »
Si les SLO sont applicables, les accords de niveau de service (SLA) les rendent applicables d'un point de vue juridique. Les SLA associent généralement une pénalité financière au SLO, stipulant par exemple que si nous ne respectons pas notre SLO pour un client, nous pouvons être tenus de rembourser un certain pourcentage de l'argent qu'il a dépensé avec nous. En règle générale, en tant que technologues, nous n'avons pas à nous soucier autant des SLA, car c'est quelque chose dont nos avocats s'occupent.
Mettre en œuvre de bons SLO
Il s’avère qu’un bon SLO n’est pas aussi simple à mettre en œuvre qu’on pourrait le penser à première vue. Une approche naïve pourrait consister à mesurer l’écart par rapport au « bon » sur une certaine période et à émettre une alerte à ce sujet. Cette approche simple souffre de toute une série d’inconvénients. La discussion suivante s’inspire des meilleures pratiques dans le domaine Manuel SRE de Google . Explorons comment ces idées peuvent être utilisées pour mettre en œuvre des SLO utiles avec Front d'onde !
Choisir le bon SLI
Choisir la bonne métrique comme base d'un SLI est un art en soi et mérite un article séparé. En règle générale, nous devons choisir une métrique qui est significative pour l'entreprise et exploitable. Les bonnes métriques incluent les taux d'erreur et les performances des services commerciaux. Les mauvaises métriques incluent les métriques purement techniques et les métriques qui ne correspondent pas à un résultat exploitable. Voici quelques exemples :

Budgets d'erreur
Personne n'est parfait, il faut donc se laisser une marge d'erreur. Un système avec une disponibilité de 100 % n'est pas réaliste, il faut donc faire un compromis entre notre volonté de fournir un système fiable et les ressources disponibles. Fixer des attentes trop élevées en matière de disponibilité est l'une des pires erreurs que nous puissions commettre. Cela entraîne des alertes constantes que les gens finissent par ignorer et qui masquent les vrais problèmes.
Nous devons donc déterminer pendant combien de temps, sur une période donnée, nous nous autorisons à ne pas être en conformité. Cela s'exprime généralement sous forme de pourcentage. Par exemple, nous pouvons nous autoriser à passer 1 % de notre temps en dehors de la conformité. En général, nous transformons ce pourcentage en un chiffre de disponibilité. Ainsi, dans le cas d'un budget d'erreur de 1 %, nous disons que nous nous attendons à une disponibilité de 99 %.
Fenêtres SLO
Le problème suivant est celui de la période de mesure. Nous disons que nous nous autorisons à ne pas être en conformité 1 % du temps, mais sur quelle période de temps ? Le choix de cette période s'avère être un problème difficile à résoudre. Si nous mesurons sur une période très courte, disons 10 minutes, des problèmes insignifiants déclencheront constamment des alertes. À l'inverse, si nous mesurons sur une période plus longue, disons 30 jours, nous serons alors alertés trop tard et risquons de passer à côté de pannes graves.
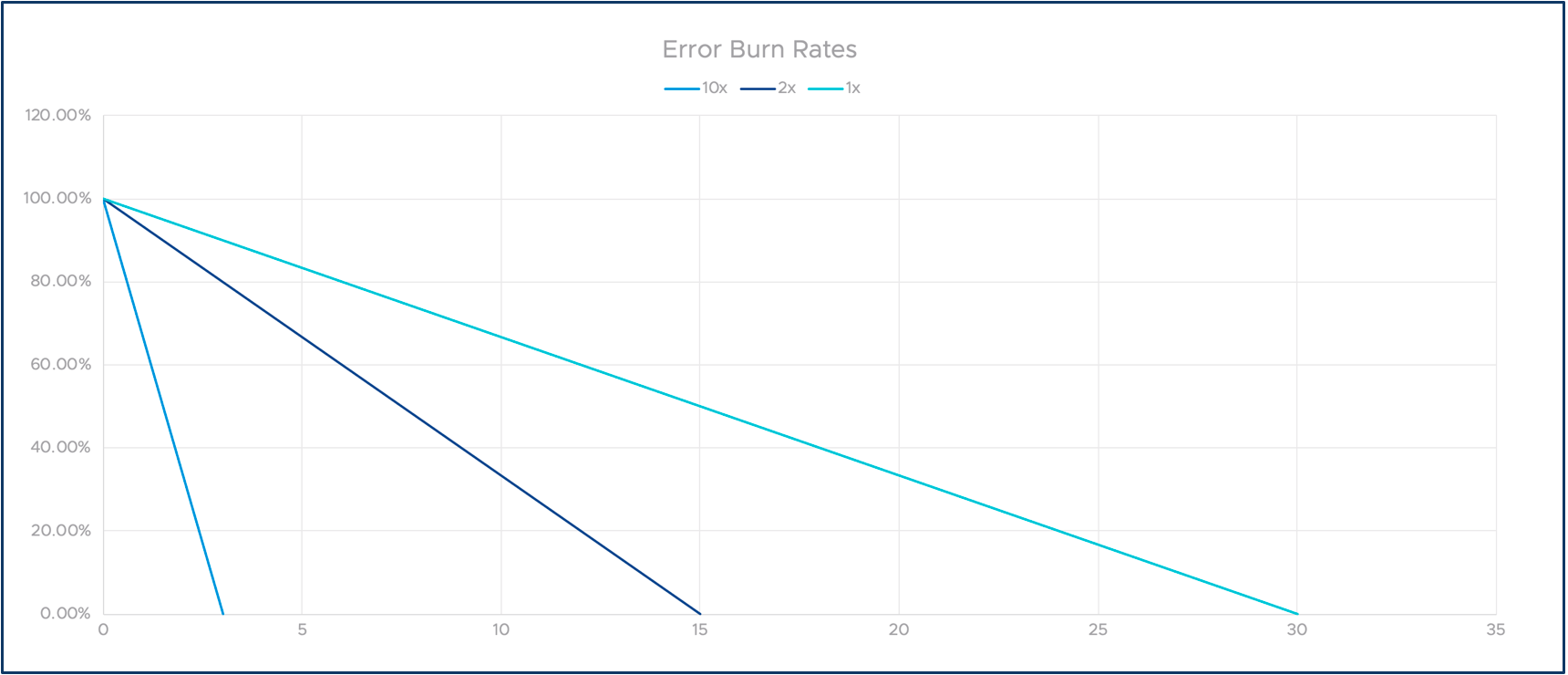
Taux de combustion
Supposons que notre contrat avec nos utilisateurs stipule une disponibilité de 99,9 % sur 30 jours. Cela correspond à un budget d'erreur de 43 minutes. Si nous exploitons ces 43 minutes en petites quantités de problèmes mineurs, nos utilisateurs sont probablement toujours satisfaits et productifs. Mais que se passe-t-il si nous avons une seule panne de 43 minutes à un moment critique pour l'entreprise ? Il est sûr de dire que nos utilisateurs seraient assez mécontents de cette expérience !
Pour résoudre ce problème, nous pouvons introduire des taux de consommation. La définition est simple : si nous consommons exactement 43 minutes dans notre exemple sur 30 jours, nous appelons cela un taux de consommation de 1. Si nous consommons deux fois plus vite, par exemple en 15 jours, le taux de consommation est de deux, et ainsi de suite. Comme vous le verrez, cela nous permet de suivre la conformité à long terme et d'alerter sur les problèmes graves à court terme.
Le graphique suivant illustre l'idée de taux de combustion multiples. L'axe des X représente le temps et l'axe des Y notre marge d'erreur restante.
Mettre tous ensemble
Prenons maintenant ce qui vient d’être expliqué et rassemblons-le dans une solution utile pour la surveillance et l’alerte SLO !
Nous avons appris que la surveillance à long terme d'une tendance SLO et les alertes à court terme doivent être effectuées à l'aide de méthodes différentes. Nous avons également introduit l'idée des taux de combustion. Alors, comment pouvons-nous transformer cela en une excellente solution d'alerte SLO ?
Plusieurs fenêtres ?
Une idée consiste à utiliser plusieurs fenêtres temporelles pour les alertes immédiates et les observations de tendances à plus long terme. Le problème est que si nous sélectionnons une fenêtre d'une heure, un objectif de 99 % n'autorise que 36 secondes de non-conformité. Pour un objectif de 99,9 %, ce nombre tombe à 3,6 secondes ! Cela entraînerait de nombreuses alertes bruyantes pour des problèmes mineurs.
Plusieurs fenêtres, plusieurs taux de combustion
Une façon de surmonter ce problème consiste à utiliser les taux de consommation dont nous avons parlé précédemment. Si nous examinons une fenêtre temporelle plus courte, nous mesurons par rapport à un taux de consommation plus rapide. Cela nous permet de déclencher des alertes lorsqu'un service est indisponible pendant une durée significative. Lorsque nous surveillons une fenêtre temporelle plus longue, nous utilisons un taux de consommation plus lent pour détecter les tendances inquiétantes. Le tableau suivant illustre comment cela peut être réalisé.

Cela signifie que si nous consommons notre budget d'erreur à un taux de 14,4 sur une fenêtre horaire, nous aurions dû déclencher une alerte critique. Nous sélectionnons 14,4 car cela représente une consommation de 2 % sur une heure.
En revanche, si nous observons une lente dégradation sur une période plus longue, cela n'aura peut-être pas d'impact grave sur les utilisateurs, mais cela signifie que nous sommes sur la bonne voie pour dépasser notre SLO sur une période plus longue. La première alerte doit entraîner un appel immédiat à une personne, tandis que la seconde peut être une alerte de moindre priorité que quelqu'un peut consulter lorsqu'il en a le temps.
Comment Wavefront peut vous aider
Comme nous l’avons vu, la mise en œuvre d’un bon SLO est relativement difficile. Il faut faire pas mal de calculs et prendre des décisions complexes. Pour cela, il vous faut un outil doté d’un moteur d’analyse avancé, d’un langage de requête riche et de capacités de création d’alertes flexibles. En d’autres termes, vous avez besoin de Wavefront !
Supposons que nous ayons un SLI pour le temps de réponse d'un service. Voici la série chronologique de notre métrique SLI.
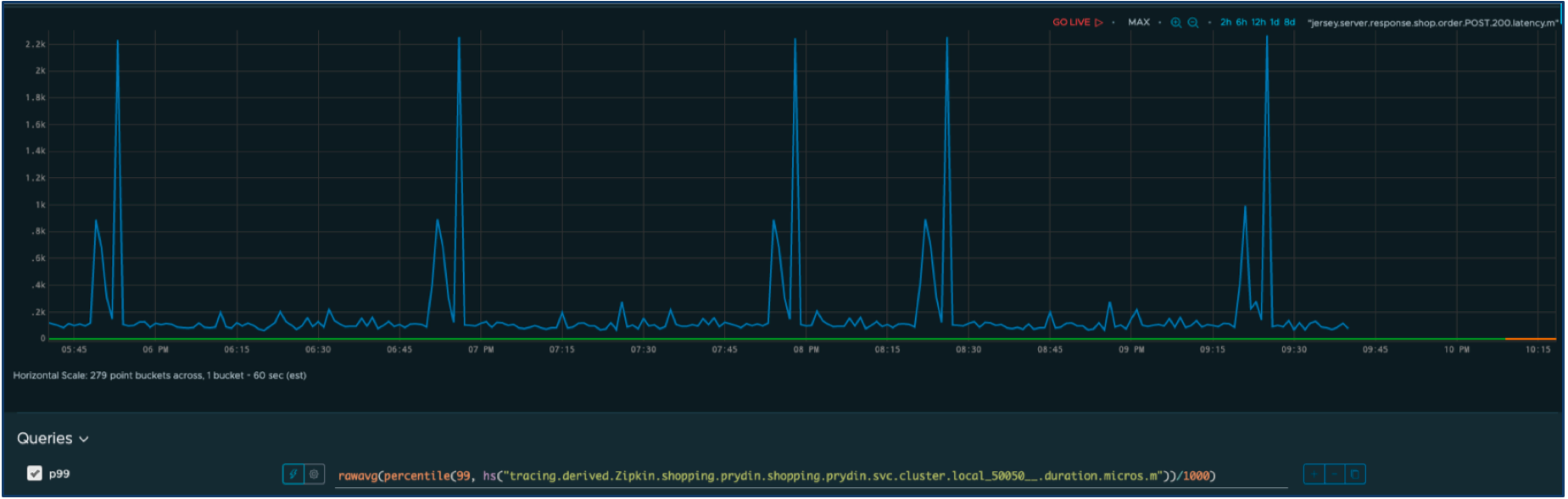
Définissons les performances acceptables comme un temps de réponse inférieur à une seconde. Tout autre temps sera considéré comme une panne ayant un impact négatif sur les utilisateurs. Nous pouvons facilement modifier la requête pour filtrer seulement les pannes.
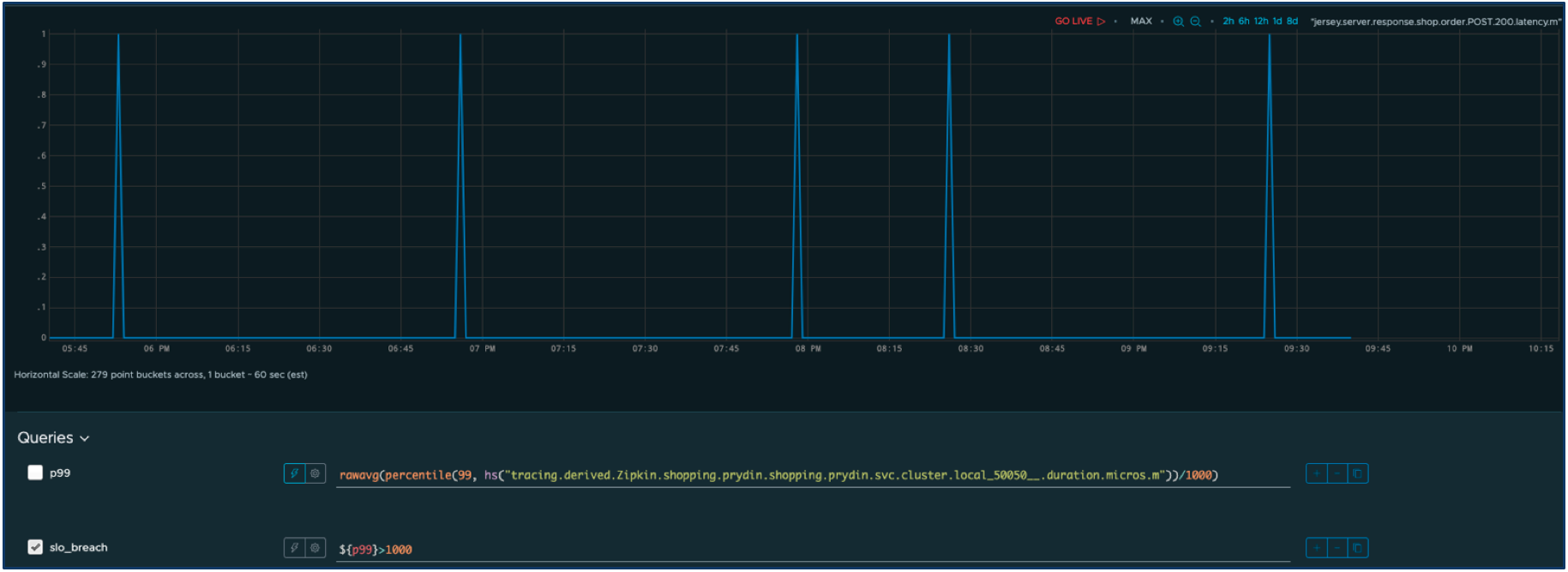
Nous définissons maintenant deux fenêtres : une fenêtre à court terme avec un taux de combustion agressif et une fenêtre à plus long terme avec un taux de combustion plus lent. Nous pouvons maintenant calculer le taux de combustion ajusté au fil du temps pour les deux fenêtres.
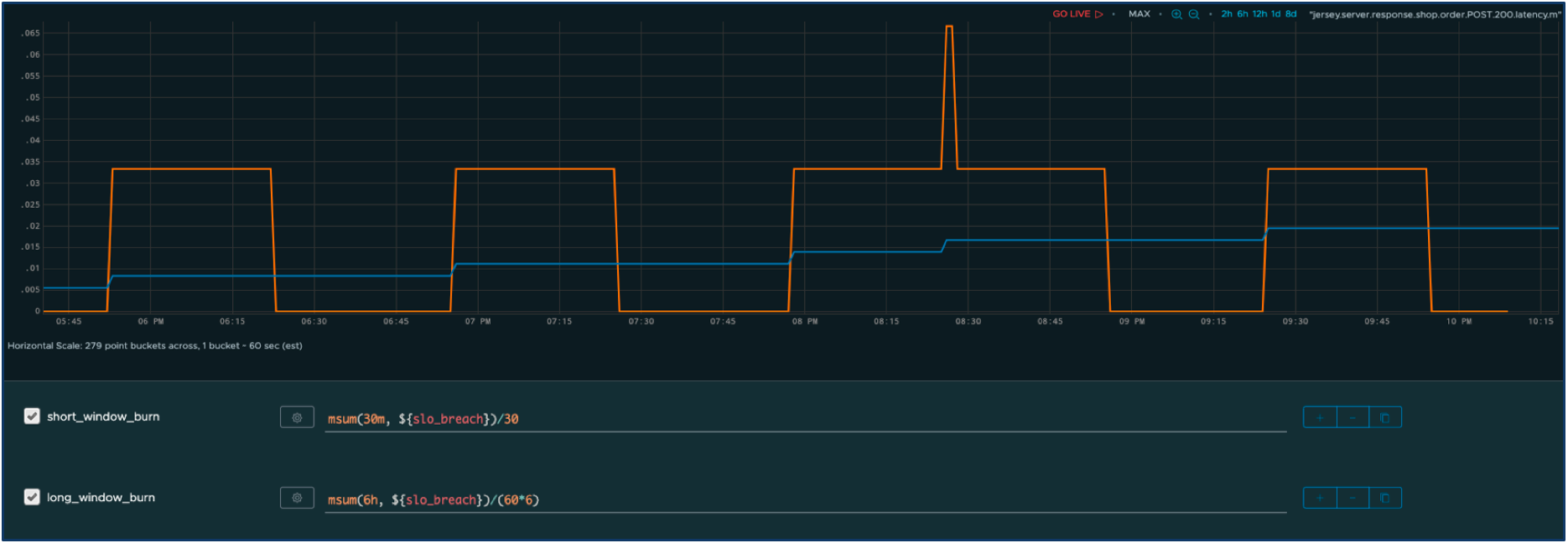
La série orange représente le temps de panne cumulé sur la fenêtre la plus courte et la série bleue sur la fenêtre la plus longue. Comme vous pouvez le constater, les pics de temps de réponse ont un impact immédiat sur la fenêtre courte, mais ils contribuent également à un changement progressif lent sur la consommation à long terme. De plus, grâce au multiplicateur de taux de consommation, nous supprimons les alertes résultant de problèmes mineurs.
Cliquons sur le bouton « Créer une alerte » dans l'interface utilisateur de Wavefront et définissons une alerte qui se déclenche lorsqu'une des fenêtres a épuisé son budget d'erreur alloué.
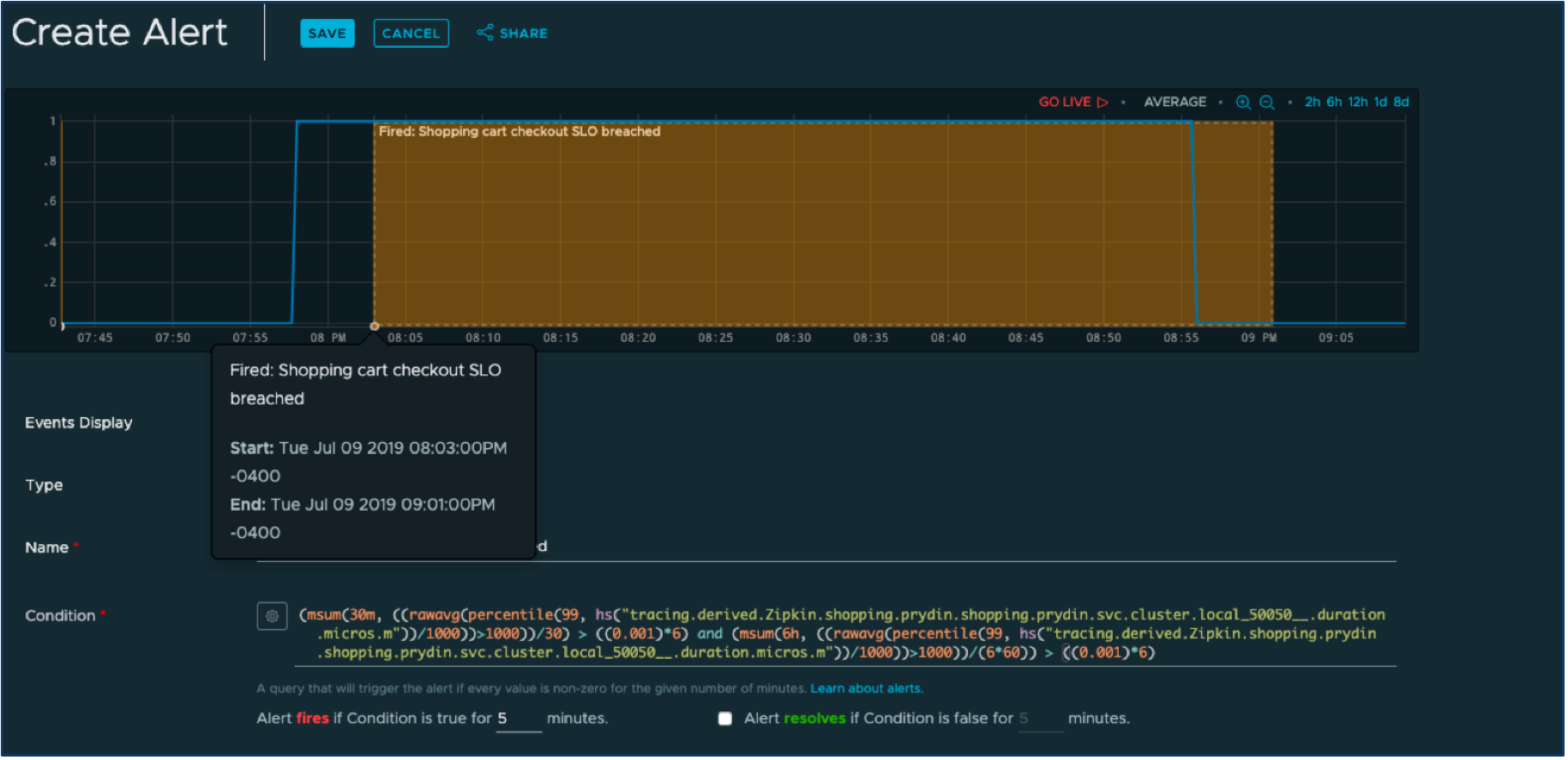
La requête d'apparence complexe en bas est synthétisée à partir de l'ensemble de requêtes beaucoup plus simples que nous avons déjà définies. Il ne nous reste plus qu'à sélectionner le mécanisme de notification d'alerte, tel que PagerDuty (il existe un excellent outil hors du commun). boîte intégration entre Wavefront et PagerDuty ), et nous pouvons nous attendre à découvrir rapidement quand nous risquons de ne plus atteindre les SLO.
Conclusion
Dans ce blog, nous avons vu que la création d'alertes sur un SLO est assez complexe. Mais grâce au langage de requête et aux mécanismes d'alerte de Wavefront, nous pouvons créer des alertes SLO intelligentes en quelques minutes.
Dans un scénario réel, il existe des techniques supplémentaires qui peuvent être utilisées pour affiner encore plus les alertes. Par exemple, nous pouvons vouloir utiliser plusieurs fenêtres par taux de combustion. Si vous souhaitez en savoir plus sur ce sujet, le manuel Google SRE est un bon point de départ.
Pour en savoir plus sur la plateforme d'observabilité Wavefront Enterprise, consultez notre essai gratuit aujourd'hui.
1. Rick Sturm, Wayne Morris « Fondements de la gestion des niveaux de service », avril 2000, Pearson
A propos de l'auteur
Pontus Rydin travaille depuis dix ans dans le domaine des solutions de gestion et d'exploitation informatiques et possède une vaste expérience dans le développement de logiciels et la gestion d'applications. Il occupe aujourd'hui le poste de directeur de l'évangélisation technologique et de défenseur des développeurs pour Wavefront by VMware. Sa mission principale est d'aider les développeurs et les SRE à mieux comprendre et à contrôler leurs applications afin d'augmenter les performances de l'entreprise tout en réduisant les risques. Pontus passe ses journées à travailler sur des contributions open source, à parler directement aux clients et à partager des idées novatrices lors de conférences via divers canaux numériques.
Vous aimerez peut-être aussi ceux-ci...

