
- PagerDuty /
- Blog /
- Automatisation /
- Qu’est-ce que le diagnostic automatisé et pourquoi devriez-vous vous en soucier ?
Blog
Qu’est-ce que le diagnostic automatisé et pourquoi devriez-vous vous en soucier ?
par Joseph Mandros
3 juin 2022 | 6 minutes de lecture
Comment mesure-t-on le coût d’un incident ?
De nombreuses personnes dans le secteur technologique évoquent le coût d’un incident uniquement sous l’angle des temps d’arrêt ou du nombre de clients et d’employés touchés. Et vu de face, c’est souvent un point de vue tout à fait pertinent. Cela fait la une des journaux, et la réputation et la confiance des clients sont essentielles au succès de toute entreprise, c’est évident.
Mais un autre coût direct des incidents qui est rarement reconnu est le nombre de personnes qui doivent intervenir lors d'un incident ; que ce soit pour aider à enquêter sur la cause profonde, dépanner et résoudre l'incident, ou absoudre leur équipe de toute responsabilité, indépendamment du fait que l'incident soit suffisamment grave pour avoir un impact sur vos clients.
Selon les données de PagerDuty , 50% de le temps d'un intervenant est consacré à déterminer qui est le mieux placé pour apporter un soutien supplémentaire ( et j'essaie de déterminer s'il y a réellement un problème ) dans un environnement x ou avec un service y. Compte tenu de cette statistique, cela signifie que 50 % de la durée de vie d'un incident est consacrée aux premières étapes d'un incident (les phases de diagnostic et de triage), plutôt qu'aux actions correctives réelles.
En résumé, le coût des heures de travail et le nombre d’actions manuelles effectuées par incident peuvent rapidement devenir élevés.
Automatiser votre réponse aux incidents
L’application de l’automatisation aux premières étapes récurrentes de l’incident, y compris le diagnostic de la gravité de l’incident et la compréhension de la composition génétique de ce qui s’est mal passé (et comment), est essentielle au succès de la résolution éventuelle de l’incident.
L'automatisation est également importante du point de vue des personnes, car elle permet de s'assurer que vos équipes ne se lassent pas d'effectuer les mêmes actions répétitives à chaque incident. Il est primordial de garantir que les données de diagnostic sont disponibles pour les premiers intervenants afin d'assurer l'efficacité du routage et le flux de travail global de la réponse aux incidents.
Avant d’aller plus loin, définissons d’abord les données de diagnostic. Données de diagnostic est données récupérées par les intervenants en cas d'incident, qui sont généralement plus spécifiques que les informations fournies par les outils de surveillance. Par exemple, alors que les outils de surveillance vous alertent en cas de pic de consommation de CPU ou de mémoire, les intervenants en cas d'incident enquêtent en examinant les processus les plus gourmands en CPU et en mémoire. Par conséquent, dans ce cas, les noms ou identifiants de processus et leur consommation de calcul associée constituent les « données de diagnostic ».
Maintenant que nous avons défini les diagnostics automatisés, Pourquoi devriez-vous vous en soucier ? Parce que la mise en œuvre d’une pratique de diagnostic automatisé peut réduire le coût des incidents, à la fois grâce à une durée réduite des incidents et à un nombre réduit d’intervenants contactés.
Le problème avec le MTTR
Peut-être que « problème » n’est pas le bon mot ici, mais écoutez-moi : Le MTTR est une mesure trop large pour fournir des informations détaillées et exploitables Le temps moyen de réparation (MTTR) est une mesure de maintenabilité de base dans l'univers informatique depuis des décennies. Et bien qu'il ait de nombreuses applications et qu'il explique très bien le taux de récupération général, son talon d'Achille est justement cela : la généralité. Et maintenant que nous pouvons en déduire en toute sécurité que 50 % de le temps d'un intervenant étant consacré à déterminer qui est le mieux placé pour apporter un soutien supplémentaire, nous avons commencé à examiner d'autres mesures dans le cadre de la chronologie MTTR, telles que le MTTT (temps moyen de triage) ou le MTTI (temps moyen d'enquête).
MTTI/MTTT : Le temps moyen entre la détection d'un incident informatique et le moment où l'organisation commence à enquêter sur sa cause et sa solution. Il s'agit du temps écoulé entre le MTTD (temps moyen de détection) et le début du MTTR (temps moyen de réparation).
Chez PagerDuty, nous mesurons cela comme le laps de temps entre le moment où votre premier intervenant « accuse » et le moment où votre résolveur « accuse ». Cette métrique nous aide à comprendre ce qui se passe réellement sous le capot lors d'un incident. Après avoir observé nos propres données, nous avons pu en déduire que le MTTI est l'un des facteurs les plus chronophages du MTTR. Et dans l’entreprise moderne, lorsqu’une tâche nécessite du temps et de l’attention de la part des ingénieurs, cette tâche est alors coûteuse pour l’entreprise. Vraiment cher.
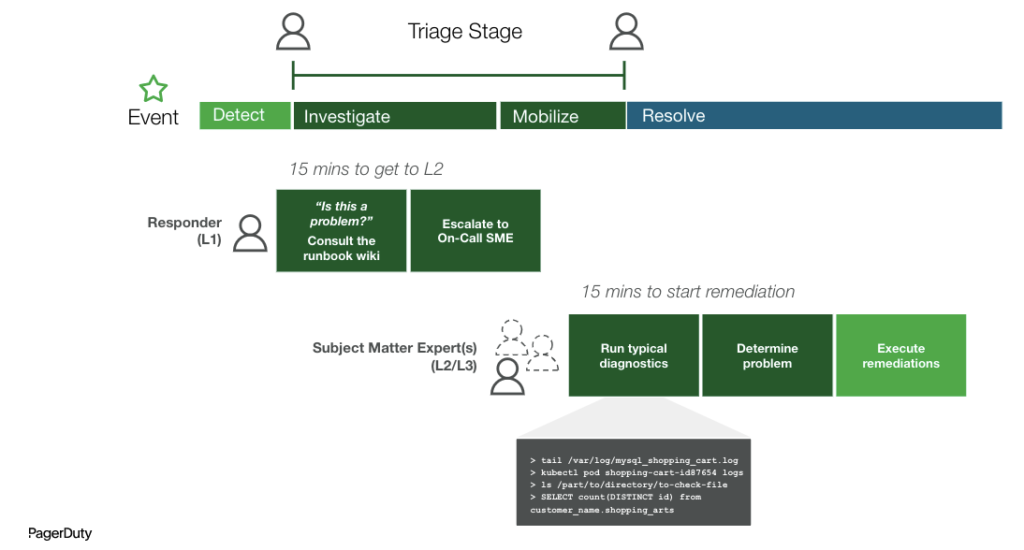
Utilisation des diagnostics automatisés
Revenons maintenant au MTTI et aux diagnostics automatisés. Le MTTI n'est pas seulement rallongé par les tâches techniques des intervenants qui extraient manuellement les données de diagnostic et doivent déchiffrer à quelle équipe faire remonter l'incident en fonction du service x et de l'incident y. Il s'agit également des personnes et de leurs limites, en fonction de l'expertise spécifique requise pour commencer la résolution. Par exemple, dans de nombreux cas, le premier intervenant ne sait pas comment enquêter sur le problème du point de vue de la base de données ou du réseau. Cela peut être dû à son manque de compétences (expérience en bases de données ou en réseaux), d'accès ou de connaissances tribales (par exemple, qu'un composant d'application spécifique dépend d'une intégration complexe avec un service tiers).
En automatisant ces tâches d’investigation et de débogage, en plus d’avoir la possibilité de déléguer ces actions entre les équipes et les intervenants, vous ressentirez un effet positif en cascade sur le MTTI et, à terme, sur le MTTR.
Alors pourquoi devriez-vous vous soucier du diagnostic automatisé ?
Grâce aux diagnostics automatisés, vous pouvez :
- Réduire escalades vers des experts rares en concevant des chemins pour fournir aux premiers intervenants des informations qui seraient normalement collectées manuellement
- Distribuer expertise en la matière au sein des équipes d'intervention
- Invoquer automatisation sécurisée derrière des pare-feu et des VPC
- Dépannage et résoudre plus rapidement sans intervention humaine requise
- Améliorer la rapidité d'activation des nouveaux ingénieurs et assurer une efficacité optimale à tous les niveaux de l'organisation de réponse aux incidents
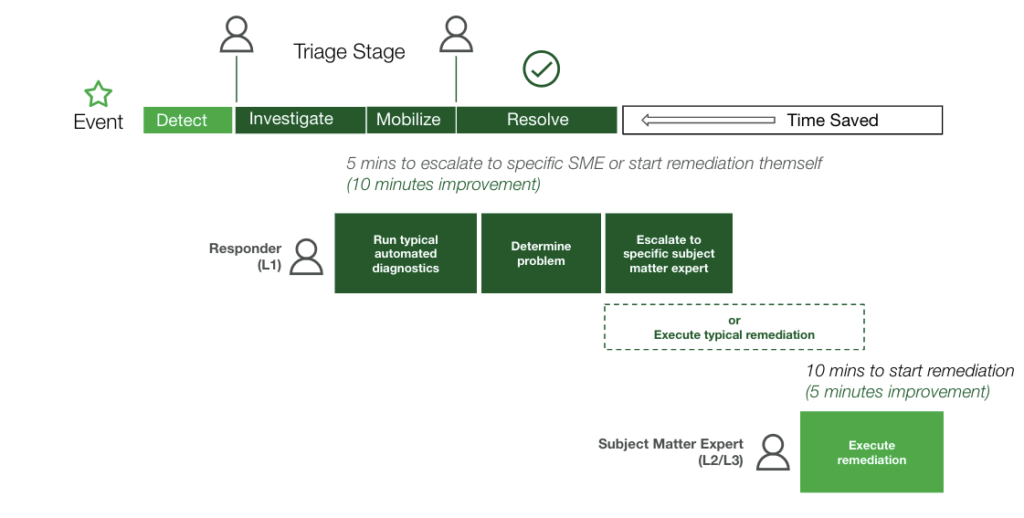
Commencer
Vous avez pris votre décision. Il est désormais temps de tracer la voie, mais par où commencer ?
Pour utiliser un jargon marketing : n'essayez pas de faire bouillir l'océan. Testez des actions à la fois peu complexes et peu risquées. Il peut s'agir d'examiner de plus près certains de vos services les plus bruyants ou d'effectuer de simples extractions de données à partir de diverses applications de surveillance, de l'utilisation du disque, etc. Mais il est important d'avoir une stratégie pour le déploiement à long terme et une vision de cette fonctionnalité. Bien sûr, vous pouvez écrire un script qui extrait des données de nombreuses sources et les ajoute à un incident. Mais c'est loin d'être évolutif.
Il est important de Pensez aux différents éléments et outils d'infrastructure dont vous souhaiterez extraire les données de diagnostic. Vous aurez besoin d'une approche standardisée pour l'interface avec vos environnements hétérogènes et dynamiques.
Pour en savoir plus sur les diagnostics automatisés, consultez certains de nos Articles pratiques , que nous continuerons à publier tout au long de l'année. De plus, ne manquez pas une session sur tout ce qui concerne les diagnostics automatisés de Jake Cohen pendant Sommet PagerDuty la semaine prochaine !
Pour plus de ressources sur le portefeuille d'automatisation des processus de PagerDuty, visitez cette page et contactez votre gestionnaire de compte aujourd'hui.
Des questions ? N'hésitez pas à nous les poser sur Twitter @sordnam

