
- PagerDuty /
- Der Blog /
- Digitale Operationen /
- 10 Fragen, die Teams stellen sollten, um schneller auf Vorfälle reagieren zu können
Der Blog
10 Fragen, die Teams stellen sollten, um schneller auf Vorfälle reagieren zu können
von Hannah Culver
13. September 2021 | 9 min lesen
Zwischen 2019 und 2020 lagen Welten. Unsere gesamte Arbeits-, Lebens-, Sozial- und Lernweise änderte sich fast über Nacht. In den letzten 18 Monaten mussten technische Teams all ihre digitalen Anstrengungen verdoppeln, um ihren Kunden bei der Anpassung an die neue Normalität zu helfen. Gleichzeitig waren die Teams für mehr ungeplante Arbeit denn je verantwortlich, da die Zahl der Vorfälle stetig zunahm.
Zum ersten Mal haben wir das Bericht zum Stand digitaler Abläufe der auf Daten der PagerDuty -Plattform basiert. Dieser Bericht zeigt die Unterschiede zwischen der Arbeit, mit der technische Teams 2019 und 2020 konfrontiert waren. Wir haben Veränderungen bei der Anzahl kritischer Vorfälle festgestellt, bei gängigen Kennzahlen wie MTTR und MTTA, wie der zusätzliche Druck betroffen Burnout, Fluktuation, und mehr.
In der neuesten Ausgabe dieser Blog-Serie Wir werden einige dieser Erkenntnisse durchgehen und 10 Fragen nennen, die sich Teams stellen können, um ihre Reaktion auf Vorfälle zu verbessern.
Was hat sich geändert?
Laut unseren Plattformdaten stiegen die kritischen Vorfälle von 2019 bis 2020 um 19 % im Vergleich zum Vorjahr. Wir betrachten kritische Vorfälle als solche von Diensten mit hoher Dringlichkeit, die nicht innerhalb von fünf
Minuten, aber innerhalb von vier Stunden bestätigt und innerhalb von 24 Stunden gelöst.
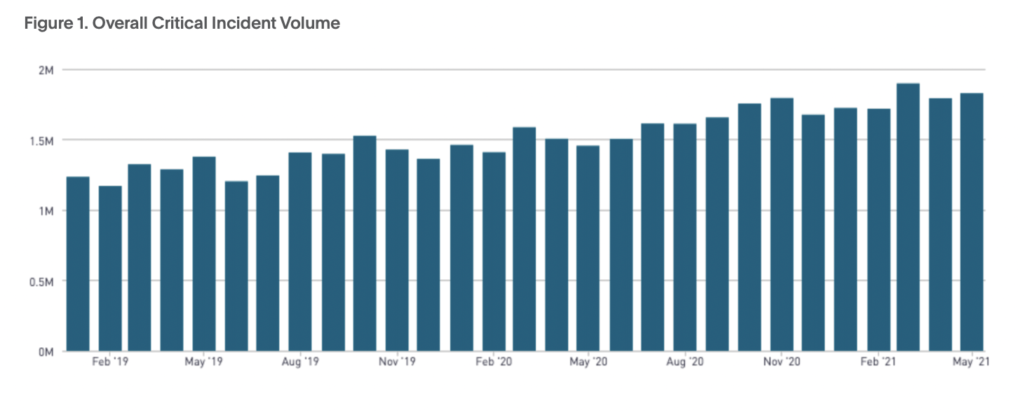
Auch wenn kritische Vorfälle zunahmen, sind MTTA (mittlere Zeit bis zur Bestätigung) und MTTR (mittlere Zeit bis zur Lösung) gesunken. MTTx-Metriken liefern kein Gesamtbild Ihres Vorfallreaktionsprozesses oder Ihrer Betriebsreife . Sie können Ihnen jedoch Einblicke in die Gesamtleistung geben und Ihnen dabei helfen, Stärken und Verbesserungsbereiche zu bewerten.
Wir haben festgestellt, dass MTTA und MTTR umso niedriger wurden, je länger ein Team PagerDuty verwendete. Wir betrachten diese verbesserte MTTA als Zeichen für eine erhöhte Verantwortlichkeit. Mit der Verbesserung der MTTA steigt auch der Ack%-Anteil, also die Anzahl der vom Bereitschaftstechniker bestätigten Alarme.
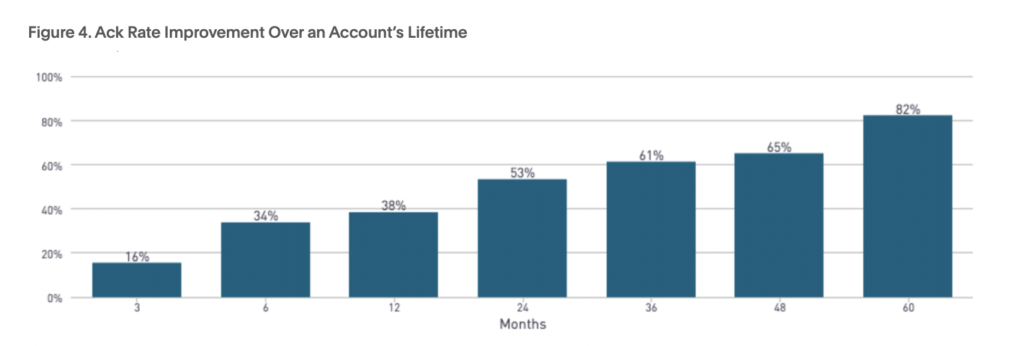
Doch obwohl MTTA und MTTR gesunken sind, ist der Zeitaufwand für die Lösung von Vorfällen immer noch gestiegen. Teams müssen intelligenter und nicht härter arbeiten. Dazu können sie Teile des Incident-Response-Lebenszyklus zur Optimierung identifizieren.
10 Fragen zu Ihrem Incident-Response-Lebenszyklus
Der Incident-Response-Lebenszyklus ist ein Prozess, der auf einen Fehler in Ihrem System folgt. Er beginnt mit der Erkennung des Fehlers, geht dann weiter mit der Verhinderung von Kundenauswirkungen, der Mobilisierung eines Teams zur Reaktion, der Diagnose des Geschehens, der Lösung des Problems und dem Lernen aus den Erfahrungen. In jeder Phase gibt es Möglichkeiten, Ihre Abläufe zu optimieren, um Vorfälle schneller und mit weniger kognitiver Anstrengung zu lösen.
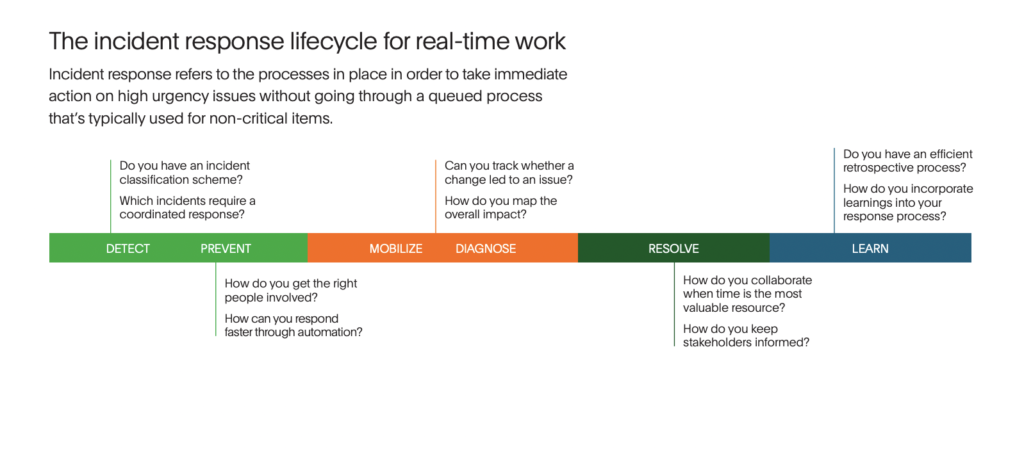
Erkennen : Diese Phase kann auf verschiedene Weise erfolgen. Im besten Fall werden Sie von Ihrer Überwachung darauf aufmerksam gemacht, dass eine Anomalie vorliegt, die Ihre Aufmerksamkeit erfordert. Im schlimmsten Fall beginnt die Erkennung damit, dass ein Kunde Ihnen mitteilen muss, dass ein Problem vorliegt. In jedem Fall können Sie schneller reagieren, indem Sie diese Fragen im Voraus beantworten:
- Welches ist das Vorfallklassifizierungsschema unserer Organisation? Manche Teams verwenden gerne Schweregrade. Andere nennen sie Prioritäten. Egal, welche Nomenklatur Sie verwenden, stellen Sie sicher, dass jeder im Team versteht, wie ein Vorfall klassifiziert wird. Was macht ihn zu einem Sev1-Vorfall im Gegensatz zu einem Sev3-Vorfall? Wenn Sie dies im Voraus verstehen, können Sie die Entscheidungen besser treffen, wenn tatsächlich ein Vorfall eintritt.
- Welche Vorfälle erfordern eine koordinierte Reaktion? Nachdem Sie nun die Schweregrade ermittelt haben, sollten Sie einen Plan für die Art von Personen erstellen, die für jeden dieser Schweregrade eingebunden werden müssen. Ein Sev3-Problem kann beispielsweise von einem einzelnen Bereitschaftstechniker problemlos bewältigt werden. Bei einem Sev1-Problem hingegen sind möglicherweise alle Hände voll zu tun, einschließlich der Geschäftsleitung. Durch die Planung können Sie Unentschlossenheit in unternehmenskritischen Momenten vermeiden.
Auswirkungen auf den Kunden verhindern: In dieser Phase versuchen Sie, die möglichen Auswirkungen auf den Kunden zu begrenzen. Dies erreichen Sie, indem Sie die richtigen Personen so schnell wie möglich einbeziehen und nach Möglichkeiten zur Automatisierung suchen. Dadurch können Sie Ihre Reaktionszeiten um mehrere Minuten verkürzen. Stellen Sie sich diese Fragen, um herauszufinden, wie Sie sich verbessern können:
- Wie bringen Sie die richtigen Leute dazu, sich zu engagieren? Oben haben wir festgestellt, dass es entscheidend ist, die richtigen Personen für jeden Schweregrad zu bestimmen. Hier denken wir darüber nach, wie wir die tatsächlichen Personen frühzeitig in den Vorfall einbeziehen können. Eine Möglichkeit hierfür ist die vollständige Verantwortung für den Service und ein detaillierter Bereitschaftsplan. Wenn Sie alle Ihre Services abgebildet und jedem ein Team zugewiesen haben, ist es einfacher herauszufinden, welches Team für die Lösung des Vorfalls verantwortlich ist. Darüber hinaus sollte bei einer detaillierten Bereitschaftsplanung die Warnung für den betreffenden Service an den genauen Techniker weitergeleitet werden, der den Reaktionsprozess einleitet.
- Wie können Sie durch Automatisierung schneller reagieren? Nirvana ist hier die Möglichkeit, Vorfälle automatisch und ohne menschliches Eingreifen zu beheben. Dies ist zwar für die häufigsten Vorfälle möglich, die bei Ihnen auftreten, aber es ist wahrscheinlicher, dass Sie einen ähnlichen Ansatz wie den PagerDuty Kundendienst wählen. Pfarrer , das kleine Aufgaben automatisiert und dann im Laufe der Zeit komplexere Sequenzen aneinanderreiht.
Diagnostizieren : In dieser Phase geht es darum, das Problem zu verstehen, mit dem Sie konfrontiert sind, einschließlich möglicher Ursachen und betroffener abhängiger Dienste. Während Sie daran arbeiten, die Ursache des Vorfalls zu ermitteln, können Sie Änderungen untersuchen, die sich möglicherweise auf die Dienste ausgewirkt haben, für die Sie verantwortlich sind, und wie das gesamte Ökosystem betroffen ist. Je früher Sie verstehen, was passiert, desto schneller können Sie es beheben. Denken Sie über Fragen nach wie:
- Können Sie nachverfolgen, ob eine Änderung zu einem Problem geführt hat? Die häufigste Ursache eines Vorfalls ist eine Änderung der Codebasis. Wenn Sie einen Tool zur Verwaltung von Änderungsereignissen können Sie sich die letzten Bereitstellungen ansehen und einen möglichen Schuldigen schneller finden. Dies kann Ihnen zwar normalerweise keine 100 %ig positive Lösung bieten, aber es kann Ihnen eine Richtung vorgeben, in die Sie sich bewegen können. Stellen Sie sicher, dass Sie Änderungen verfolgen und dass alle Bereitschaftstechniker diese Informationen für die Dienste zur Verfügung haben, für die sie arbeiten.
- Wie bilden Sie die Gesamtauswirkungen ab? Es ist wichtig zu verstehen, wie sich Ihr Service auf andere auswirkt, sowohl technisch als auch geschäftlich. Dazu sollten Sie die Abhängigkeiten Ihres Services und die Abhängigkeiten Ihres Services abbilden. Servicediagramm kann Ihnen dabei helfen, dies zu visualisieren. Über die technischen Aspekte hinaus sollten Sie überlegen, wie sich Ihr Service auf das Geschäft auswirkt, und Ihre Technologiefunktionen auf die Geschäftsebene abbilden. Um zu verstehen, wie Sie mit diesem integrierten Ansatz Geschäftsvorfälle bewältigen können, lesen Sie dies Ops-Handbuch.
Lösen : Dies ist der Teil des Prozesses, an den die meisten Leute denken, wenn sie sich eine Reaktion auf einen Vorfall vorstellen. Ein Team talentierter Personen, die glauben, das Problem zu kennen und es zu beheben. An diesem Punkt arbeiten Ihre SMEs (wie viele davon je nach Schweregrad beteiligt sind) daran, den Service für die Kunden wiederherzustellen. Je schneller dies abgeschlossen ist, desto weniger geschäftliche Auswirkungen hat dieser Vorfall. Aber bevor Sie sich ins Detail begeben, ist es wichtig, diese beiden Dinge zu skizzieren.
- Wie arbeitet man zusammen, wenn Zeit die wertvollste Ressource ist? Stellen Sie vor Vorfällen sicher, dass Sie verstehen, welche Rollen jeder Schweregrad eines Vorfalls erfordert und welche Verantwortung diese Rollen tragen. Beispielsweise kann der Einsatzleiter nur bei Vorfällen der Schweregrade 2 und höher eingesetzt werden. Diese Person übernimmt das Ruder des Reaktionsprozesses. Der Schreiber dokumentiert in der Zwischenzeit alle wichtigen Entdeckungen während dieser Zeit. PagerDuty -Rollen und -Verantwortlichkeiten sind ausführlich hier zur weiteren Lektüre.
- Wie halten Sie die Stakeholder auf dem Laufenden? Es ist wichtig, wie Teams intern kommunizieren, aber Sie müssen auch überlegen, wie Sie mit anderen Stakeholdern im Geschäftsbereich wie Kundenerfolg, Vertrieb, PR und der Geschäftsleitung kommunizieren. Stellen Sie sicher, dass Ihr Kommunikationsplan nach Schweregrad gegliedert ist. Weitere Informationen zur Kommunikation mit Stakeholdern finden Sie unter Lesen Sie diesen Leitfaden.
Lernen : Nach Abschluss eines Vorfalls ist es zu spät, die Lösungszeit für diesen Fehler zu beschleunigen. Die Erkenntnisse aus jedem Vorfall können Ihnen jedoch dabei helfen, einen ähnlichen Vorfall in Zukunft besser zu lösen. Versuchen Sie, sich Zeit zu nehmen, um alle kritischen Vorfälle zu überprüfen und eine gründliche Nachbetrachtung durchzuführen. Um zu analysieren, wie Ihr Team lernt, können Sie diese Fragen stellen:
- Verfügen Sie über einen effizienten Retrospektivprozess? Wenn Sie eine Retrospektive durchführen, sollten Sie im Voraus vorbereitet sein und bereit, den Vorfall zu besprechen. Sie müssen einen Zeitplan erstellen, die Auswirkungen dokumentieren, den Vorfall analysieren, Aktionspunkte erstellen, externe Nachrichten schreiben und eine gründliche Diskussion darüber führen, was passiert ist. Am wichtigsten ist, dass Sie diesen Prozess frei von Schuldzuweisungen halten. Es ist wichtig, ihn aus einer Lernperspektive anzugehen, anstatt mit dem Finger auf andere zu zeigen. Weitere Informationen zu Postmortems finden Sie unter dieser Leitfaden .
- Wie integrieren Sie Erkenntnisse in Ihren Reaktionsprozess? Nach einer guten Postmortem-Analyse haben Sie etwas Neues über Ihr System gelernt. Sie können Aktionspunkte priorisieren und Fehler beheben, um den betroffenen Dienst in Zukunft zuverlässiger zu machen. Darüber hinaus können Sie Ihren Reaktionsprozess verbessern. Dies hilft Ihnen, effizienter und besser vorbereitet zu sein. Suchen Sie nach Kommunikationsproblemen, Automatisierungsmöglichkeiten oder Möglichkeiten zur Verbesserung Ihrer Dokumentation.
Mithilfe dieser 10 Fragen kann Ihr Team besser verstehen, wie weit Sie in Bezug auf Ihre Reaktionsfähigkeit bei Vorfällen sind. Wenn Sie schrittweise in die Verbesserung der Prozesse investieren, werden Sie feststellen, dass Sie die immer größer werdende Zahl an Vorfällen besser bewältigen können.
Was kommt als nächstes?
Die Mitarbeiterzahl wächst nicht, um der Anzahl der Vorfälle gerecht zu werden, mit denen die Teams konfrontiert sind. Und angesichts der bevorstehenden großen Kündigungswelle ist es wichtig, effizient zu arbeiten, bis neue Teammitglieder geschult sind. Während die Erhöhung der Ressourcen ein Thema ist, das angegangen werden sollte, um den Teams zu helfen, die Arbeitsbelastung besser auszugleichen, können Sie auch die Art und Weise verbessern, wie Sie Vorfälle erkennen, Auswirkungen auf Kunden verhindern, das Problem diagnostizieren und lösen und aus Fehlern lernen.
PagerDuty kann Ihrem Team bei diesen Initiativen helfen. Um sich selbst davon zu überzeugen, melden Sie sich an für 14 Tage kostenlos testen. Wenn Sie mehr über unsere Plattformdaten erfahren möchten, können Sie den gesamten Bericht zum Stand digitaler Abläufe .

